JAVA并发(7)-并发队列PriorityBlockingQueue的源码分析
本文讲PriorityBlockingQueue(优先阻塞队列)
1. 介绍
一个无界的具有优先级的阻塞队列,使用跟PriorityQueue相同的顺序规则,默认顺序是自然顺序(从小到大)。若传入的对象,不支持比较将报错( ClassCastException)。不允许null。
底层使用的是基于数组的平衡二叉树堆实现(它的优先级的实现)。
公共方法使用单锁ReetrantLock保证线程的安全性。
1.1 类结构
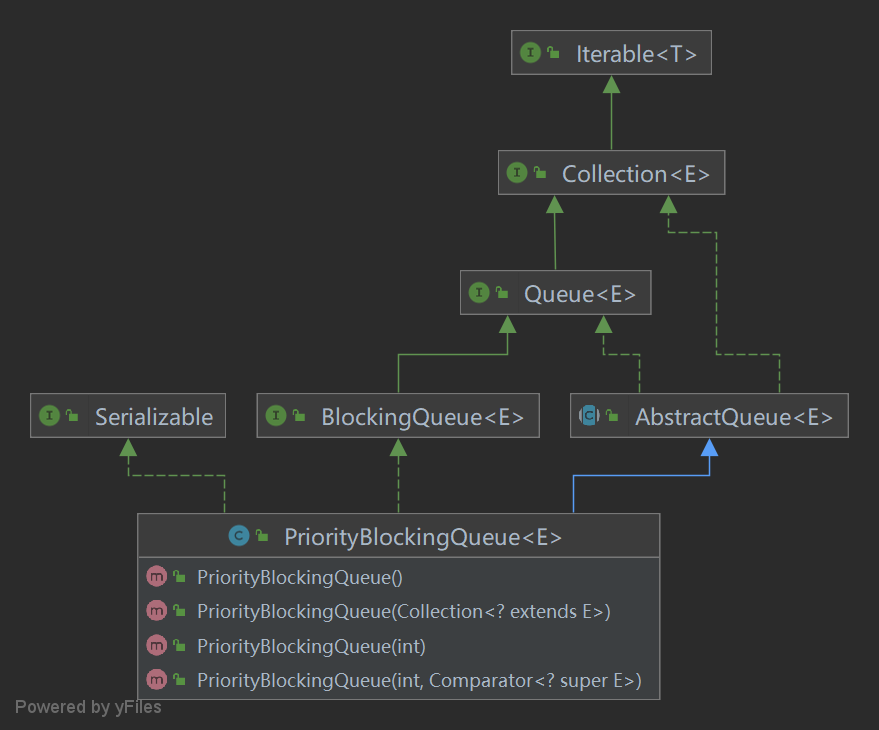
- PriorityBlockingQueue类图
重要的参数
// 数组的默认大小,会自动扩容的
private static final int DEFAULT_INITIAL_CAPACITY = 11;
/**
* The maximum size of array to allocate.
* Some VMs reserve some header words in an array.
* Attempts to allocate larger arrays may result in
* OutOfMemoryError: Requested array size exceeds VM limit
*/
// 为啥是减8,一些虚拟机会在数组中保留一些header words(头字), 应该学到jvm时,就知道了
private static final int MAX_ARRAY_SIZE = Integer.MAX_VALUE - 8;
private transient Object[] queue;
...
// 如果是空的话,优先级队列就使用元素的自然顺序(从小到大)
private transient Comparator<? super E> comparator;
保证线程安全的措施
/**
* Lock used for all public operations
*/
private final ReentrantLock lock;
/**
* Condition for blocking when empty
*/
// 为啥没有notFull,因为该队列是无界的
private final Condition notEmpty;
/**
* Spinlock for allocation, acquired via CAS.
*/
// 为啥用CAS,而不是锁,来控制线程安全在扩容时,后面讲
private transient volatile int allocationSpinLock;
2. 源码剖析
我们知道PriorityBlockingQueue实现了BlockingQueue,这篇博客有提到过BlockingQueue可以看一下,它定义了四种方式,对不能立即满足条件的不同的方法,有不同的处理方式。
我们一起去看看下面几种类型的方法的具体实现
- 入队
- 出队
2.1 入队
public boolean add(E e) {
return offer(e);
}
public void put(E e) {
offer(e); // never need to block
}
// 忽略时间
public boolean offer(E e, long timeout, TimeUnit unit) {
return offer(e); // never need to block
}
上面几个入队方法都是去调用的offer(e),所以主要来看看这个方法的实现吧
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
final ReentrantLock lock = this.lock;
lock.lock();
int n, cap;
Object[] array;
// 直到扩容成功或溢出为止
while ((n = size) >= (cap = (array = queue).length))
tryGrow(array, cap);
try {
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 二叉堆的插入算法,在后面讲
siftUpComparable(n, e, array);
else
siftUpUsingComparator(n, e, array, cmp);
size = n + 1;
notEmpty.signal();
} finally {
lock.unlock();
}
return true;
}
总体步骤很简单,查看是否需要扩容,然后再插入元素到二叉堆里。我们看看扩容的实现
- 扩容
容量小于64,oldCap + (oldCap + 2); 否则oldCap + (oldCap * 0.5)
private void tryGrow(Object[] array, int oldCap) {
lock.unlock(); // must release and then re-acquire main lock
Object[] newArray = null;
// allocationSpinLock默认是0,表示此时没有线程在扩容
if (allocationSpinLock == 0 &&
UNSAFE.compareAndSwapInt(this, allocationSpinLockOffset,
0, 1)) {
try {
int newCap = oldCap + ((oldCap < 64) ?
(oldCap + 2) : // grow faster if small
(oldCap >> 1));
// 检查是否溢出
if (newCap - MAX_ARRAY_SIZE > 0) { // possible overflow
int minCap = oldCap + 1;
if (minCap < 0 || minCap > MAX_ARRAY_SIZE)
throw new OutOfMemoryError();
newCap = MAX_ARRAY_SIZE;
}
if (newCap > oldCap && queue == array)
newArray = new Object[newCap];
} finally {
allocationSpinLock = 0;
}
}
// 此时,另一个线程正在扩容;让出自己的CPU时间片,下次再去抢占CPU时间片
if (newArray == null) // back off if another thread is allocating
Thread.yield();
// 重新获取锁
lock.lock();
// newArray已经被初始化了
// 如果queue != array, queue已经被改变了;有两种可能:
// 1. 已经有元素被出队了
// 2. 已经有元素入队了,此时入队的线程肯定扩容成功了(在没有其他元素出队的情况下)
if (newArray != null && queue == array) {
queue = newArray;
System.arraycopy(array, 0, newArray, 0, oldCap);
}
}
为什么扩容时,会解锁,并通过CAS去进行新容量的计算?
However, allocation during resizing uses a simple spinlock (used only while not holding main lock) in order to allow takes to operate concurrently with allocation.This avoids repeated postponement of waiting consumers and consequent element build-up.
上面的话,大致意思就是,扩容时使用自旋锁而不是lock,为了在扩容时,也可以执行出队操作(上面的代码中,扩容比较耗费时间)。避免让阻塞的消费者被反复阻塞(被唤醒后,不满足条件,又被阻塞,反复)。
Doug Lea
2.2 出队
只讲poll()的实现;take()与poll(long timeout, TimeUnit unit)的实现都差不多
public E poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
return dequeue();
} finally {
lock.unlock();
}
}
我们先看二叉堆的插入方法siftUpComparable,再看dequeue。
// k = size x为插入的元素
private static <T> void siftUpComparable(int k, T x, Object[] array) {
Comparable<? super T> key = (Comparable<? super T>) x;
while (k > 0) {
int parent = (k - 1) >>> 1; // (k -1) / 2
Object e = array[parent];
if (key.compareTo((T) e) >= 0)
break;
array[k] = e;
k = parent;
}
array[k] = key;
}
这个二叉堆是小根堆(任何一个结点的左右子节点的值都大于自己)
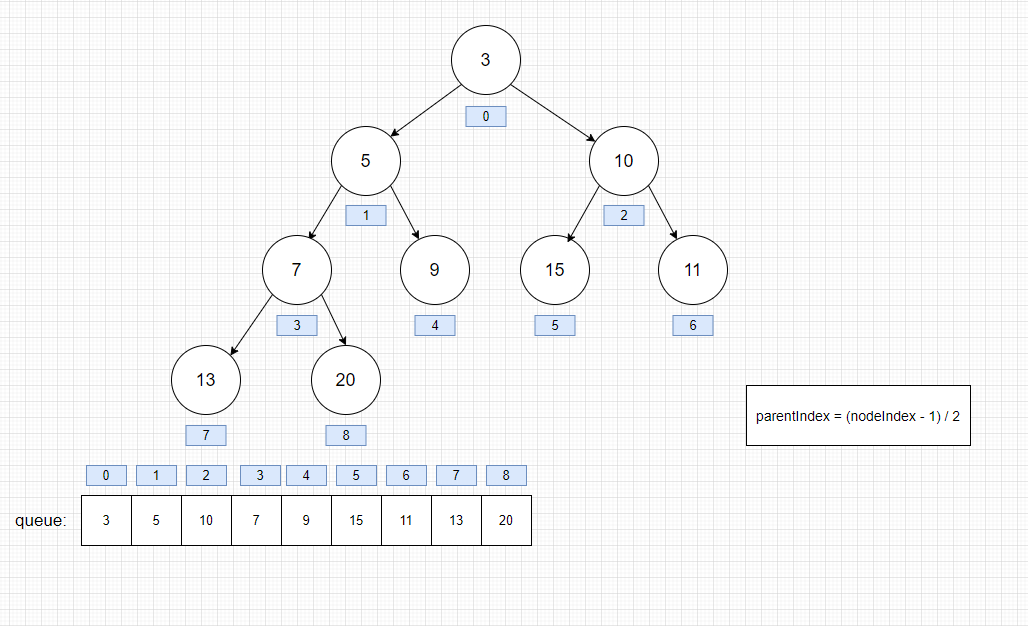
- 堆初始化
此时,我们执行offer(4)。按照上面的源码,我们最后得到
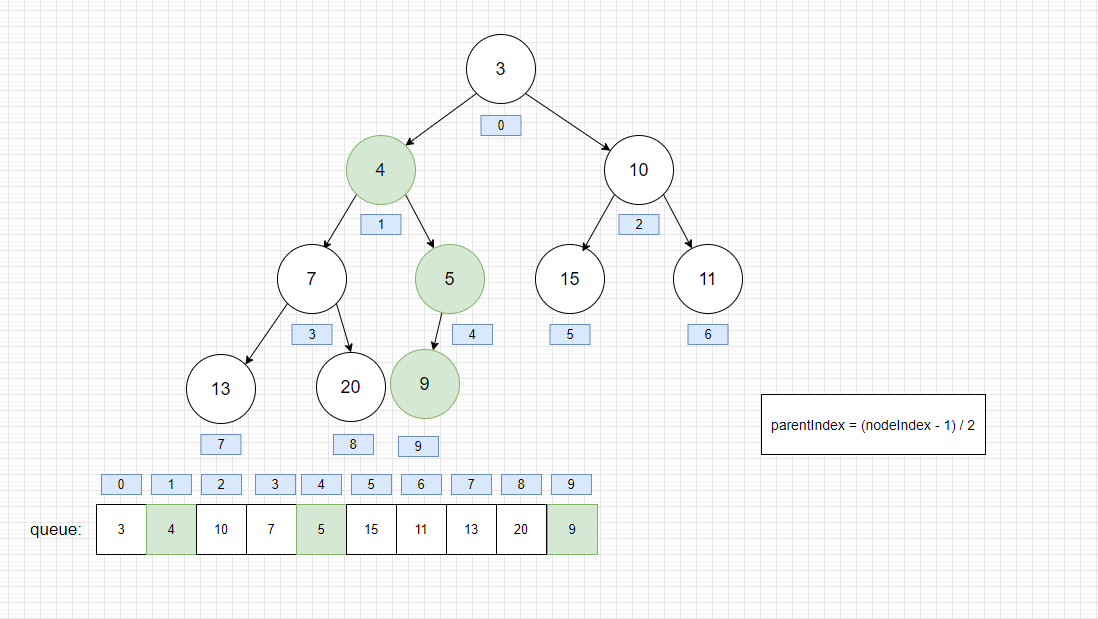
- offer(4)
整个堆插入的思路: 欲插入的元素是否比其父结点小,则与父结点互相交换(小根堆)
我们再执行poll() -> dequeue()
返回头部元素,然后重新调整堆元素位置
/**
* Mechanics for poll(). Call only while holding lock.
*/
private E dequeue() {
int n = size - 1;
if (n < 0)
return null;
else {
Object[] array = queue;
// 获取第一个值
E result = (E) array[0];
// 保存末尾的值,并置空
E x = (E) array[n];
array[n] = null;
Comparator<? super E> cmp = comparator;
if (cmp == null)
// 调整堆的位置
siftDownComparable(0, x, array, n);
else
siftDownUsingComparator(0, x, array, n, cmp);
size = n;
return result;
}
}
将 x元素插入到k位置,为了维持二叉堆的平衡,一直降级x直到它小于或等于它的子节点
private static <T> void siftDownComparable(int k, T x, Object[] array,
int n) {
if (n > 0) {
Comparable<? super T> key = (Comparable<? super T>)x;
int half = n >>> 1; // half = n / 2 // loop while a non-leaf
while (k < half) {
int child = (k << 1) + 1; // assume left child is least child = k * 2 + 1
Object c = array[child];
int right = child + 1;
if (right < n &&
((Comparable<? super T>) c).compareTo((T) array[right]) > 0)
// 左右节点谁小,谁就当父结点
c = array[child = right];
if (key.compareTo((T) c) <= 0)
break;
array[k] = c;
k = child;
}
array[k] = key;
}
}
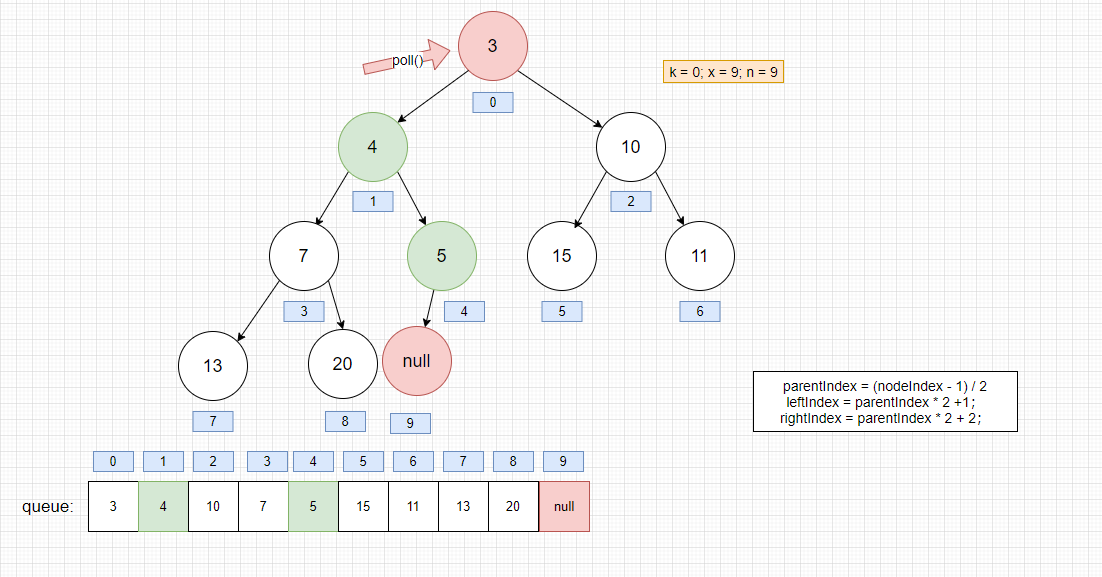
- 进入siftDownComparable的状态
执行完毕
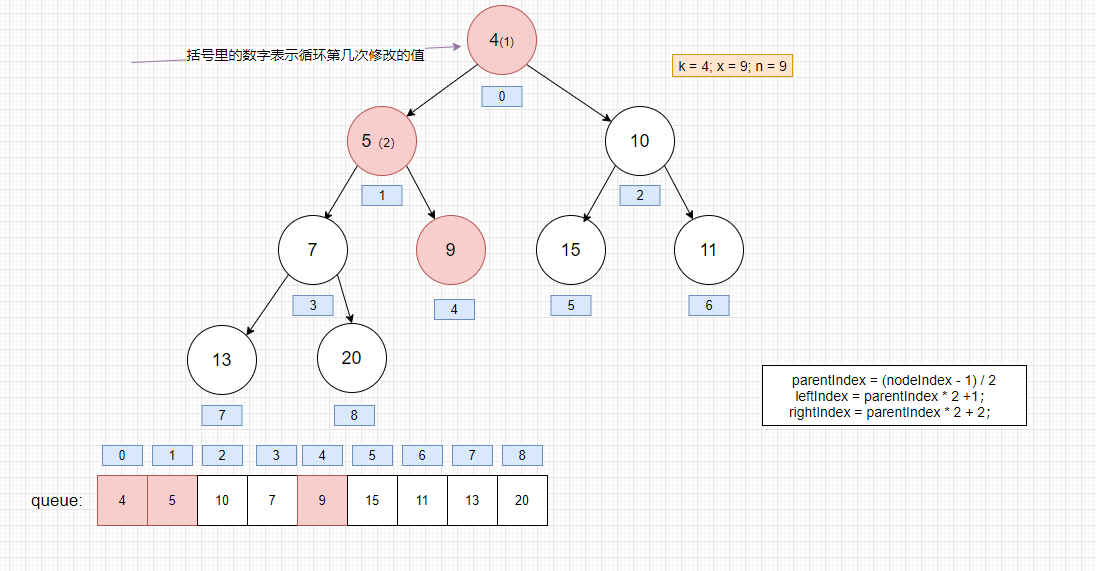
堆获取头结点后的思路: 将最后一个节点保存起来并置空,将它插入到第一个节点,若不满足就执行下面的流程.
- 比较第一个节点的左右节点是否小于该节点,是的话,就交换左右节点的最小的一个值的位置,周而复始。直到满足最小堆的性质为止
3. 总结
- PriorityBlockingQueue入队后的元素的顺序是按照元素的自然顺序(Comparator为null时)进行维护的。
- 使用ReetrantLock单锁,保证线程的安全性;在扩容时,通过CAS来保证只有一个线程可以成功扩容,同时扩容时,还可以进行出队操作
- 顺序通过二叉堆维护的,默认是最小堆
4. 参考
- 深入理解Java PriorityQueue -- 对堆的算法讲的很细致
JAVA并发(7)-并发队列PriorityBlockingQueue的源码分析的更多相关文章
- java并发包——阻塞队列BlockingQueue及源码分析
一.摘要 BlockingQueue通常用于一个线程在生产对象,而另外一个线程在消费这些对象的场景,例如在线程池中,当运行的线程数目大于核心的线程数目时候,经常就会把新来的线程对象放到Blocking ...
- Java的三种代理模式&完整源码分析
Java的三种代理模式&完整源码分析 参考资料: 博客园-Java的三种代理模式 简书-JDK动态代理-超详细源码分析 [博客园-WeakCache缓存的实现机制](https://www.c ...
- java 日志体系(四)log4j 源码分析
java 日志体系(四)log4j 源码分析 logback.log4j2.jul 都是在 log4j 的基础上扩展的,其实现的逻辑都差不多,下面以 log4j 为例剖析一下日志框架的基本组件. 一. ...
- java中的==、equals()、hashCode()源码分析(转载)
在java编程或者面试中经常会遇到 == .equals()的比较.自己看了看源码,结合实际的编程总结一下. 1. == java中的==是比较两个对象在JVM中的地址.比较好理解.看下面的代码: ...
- 延迟队列DelayQueue take() 源码分析
延迟队列DelayQueue take() 源码分析 在工作中使用了延迟队列,对其内部的实现很好奇,于是就研究了一下其运行原理,在这里就介绍一下take()方法的源码 1 take()源码 如下所示 ...
- Java SPI机制实战详解及源码分析
背景介绍 提起SPI机制,可能很多人不太熟悉,它是由JDK直接提供的,全称为:Service Provider Interface.而在平时的使用过程中也很少遇到,但如果你阅读一些框架的源码时,会发现 ...
- 【Java并发编程】16、ReentrantReadWriteLock源码分析
一.前言 在分析了锁框架的其他类之后,下面进入锁框架中最后一个类ReentrantReadWriteLock的分析,它表示可重入读写锁,ReentrantReadWriteLock中包含了两种锁,读锁 ...
- 并发编程(四)—— ThreadLocal源码分析及内存泄露预防
今天我们一起探讨下ThreadLocal的实现原理和源码分析.首先,本文先谈一下对ThreadLocal的理解,然后根据ThreadLocal类的源码分析了其实现原理和使用需要注意的地方,最后给出了两 ...
- HashMap在JDK1.8中并发操作,代码测试以及源码分析
HashMap在JDK1.8中并发操作不会出现死循环,只会出现缺数据.测试如下: package JDKSource; import java.util.HashMap; import java.ut ...
随机推荐
- 洛谷P1423 小玉在游泳
题目描述 小玉开心的在游泳,可是她很快难过的发现,自己的力气不够,游泳好累哦.已知小玉第一步能游2米,可是随着越来越累,力气越来越小,她接下来的每一步都只能游出上一步距离的98%.现在小玉想知道,如果 ...
- hdu5056(找相同字母不出现k次的子串个数)
题意: 给你一个字符串,然后问你这个字符串里面有多少个满足要求的子串,要求是每个子串相同字母出现的次数不能超过k. 思路: 这种题目做着比较有意思,而且不是很难(但自己还是嘚瑟,w ...
- Python脚本与Metasploit交互攻击
Metasploit是一款强大的漏洞扫描和利用工具,编写Python脚本与Metasploit进行交互,可以自动化的扫描和利用漏洞. 相关文章:Metasploit框架的使用 在脚本中,我们首选需要利 ...
- Win64 驱动内核编程-24.64位驱动里内嵌汇编
64位驱动里内嵌汇编 讲道理64位驱动是不能直接内链汇编的,遇到这种问题,可以考虑直接把机器码拷贝到内存里,然后直接执行. 获得机器码的方式,可以写好代码之后,直接通过vs看反汇编,然后根据地址在看内 ...
- FileItem的部分方法解释
FileItem的部分方法: boolean isFormField() isFormField() 方法用来判断FileItem对象里面封装的数据是一个普通文本表单字段,还是一个文件表单字段.如果是 ...
- HTML <video>
HTML <video> 元素 用于在HTML或者XHTML文档中嵌入媒体播放器,用于支持文档内的视频播放.你也可以将 <video> 标签用于音频内容,但是 <audi ...
- 全套AutoCAD版本安装教程及下载地址
1:AutoCAD 2004 安装教程及下载地址 https://mp.weixin.qq.com/s/4So2zmJ6nWu6Z3bSo3W19Q 2:AutoCAD 2005 安装教程及下载地址 ...
- Elasticsearch数据库优化实战:让你的ES飞起来
摘要:ES已经成为了全能型的数据产品,在很多领域越来越受欢迎,本文旨在从数据库领域分析ES的使用. 本文分享自华为云社区<Elasticsearch数据库加速实践>,原文作者:css_bl ...
- 获取CPU频率
#include <stdio.h> #include <string.h> float get_cpu_clock_speed() { FILE *fp; char buff ...
- Linux服务之nginx服务篇五(静态/动态文件缓存)
一.nginx实现静态文件缓存实战 1.nginx静态文件缓存 如果要熟练使用nginx来实现文件的缓存,那下面的几个指令你必须要牢记于心 (1)指令1:proxy_cache_path 作用:设置缓 ...