深度分析 [go的HttpClient读取Body超时]
故障现场
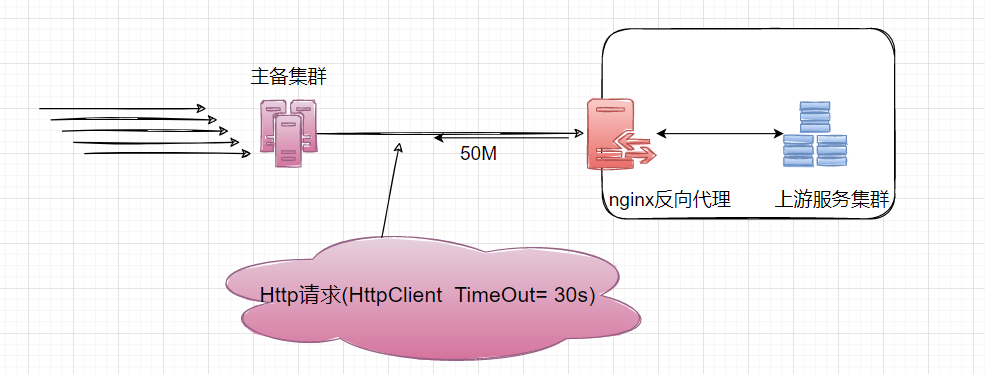
本人负责的主备集群,发出的 HttpClient 请求有 30%概率超时, 报context deadline exceeded (Client.Timeout or context cancellation while reading body)
异常
Kibana 显示 Nginx 处理请求的耗时request_time在[5s-1min]区间波动, upstream_response_time在 2s 级别。
所以我们认定是 Nginx 向客户端回传 50M 的数据,发生了网络延迟。
于是将 HttpClient Timeout 从 30s 调整到 60s, 上线之后明显改善。
But 昨天又出现了一次同样的超时异常
time="2022-01-05T22:28:59+08:00" ....
time="2022-01-05T22:30:02+08:00" level=error msg="service Run error" error="region: sz,first load self allIns error:context deadline exceeded (Client.Timeout or context cancellation while reading body)"
线下复盘
Kibana 显示 Nginx 处理请求的耗时request_time才 32s, 远不到我们对于 Http 客户端设置的 60s 超时阈值。
这里有必要穿插 Nginx Access Log 的几个背景点
- Nginx 写日志的时间
根据nginx access log官方,NGINX writes information about client requests in the access log right after the request is processed.也就是说 Nginx 是在端到端请求被处理完之后才写入日志。- Nginx Request_Time upstream_response_time
$upstream_response_time– The time between establishing a connection and receiving the last byte of the response body from the upstream server
从 Nginx 向后端建立连接开始到接受完数据然后关闭连接为止的时间$request_time– The total time spent processing a request
Nginx 从接受用户请求的第一个字节到发送完响应数据的时间
从目前的信息看,Nginx 从接受请求到发送完响应流,总共耗时 32s。
那剩下的 28s,是在哪里消耗的。
三省吾身
这是我抽离的 HttpClient 的实践, 常规的不能再常规。
package main
import (
"bytes"
"encoding/json"
"io/ioutil"
"log"
"net/http"
"time"
)
func main() {
c := &http.Client{Timeout: 10 * time.Second}
body := sendRequest(c, http.MethodPost)
log.Println("response body length:", len(body))
}
func sendRequest(client *http.Client, method string) []byte {
endpoint := "http://mdb.qa.17usoft.com/table/instance?method=batch_query"
expr := "idc in (logicidc_hd1,logicidc_hd2,officeidc_hd1)"
jsonData, err := json.Marshal([]string{expr})
response, err := client.Post(endpoint, "application/json", bytes.NewBuffer(jsonData))
if err != nil {
log.Fatalf("Error sending request to api endpoint, %+v", err)
}
defer response.Body.Close()
body, err := ioutil.ReadAll(response.Body)
if err != nil {
log.Fatalf("Couldn't parse response body, %+v", err)
}
return body
}
核心就两个动作
- 调用
Get、Post、Do方法发起 Http 请求, 如果无报错,则表示服务端已经处理了请求 iotil.ReadAll表示客户端准备从网卡读取 Response Body (流式数据), 超时异常正是从这里爆出来的
go 的 HttpClient Timeout 定义
Timeout specifies a time limit for requests made by this Client. The timeout includes connection time, any redirects, and reading the response body. The timer remains running after Get, Head, Post, or Do return and will interrupt reading of the Response.Body.
HttpClient Timeout包括连接、重定向(如果有)、从Response Body读取的时间,内置定时器会在Get,Head、Post、Do 方法之后继续运行,直到读取完Response.Body.
报错内容:"Client.Timeout or context cancellation while reading body" 读取 Response Body 超时,
潜台词是:服务器已经处理了请求,并且开始向客户端网卡写入数据。
根据我有限的网络原理/计算机原理,与此同时,客户端会异步从网卡读取 Response Body。
写入和读取互不干扰,但是时空有重叠。
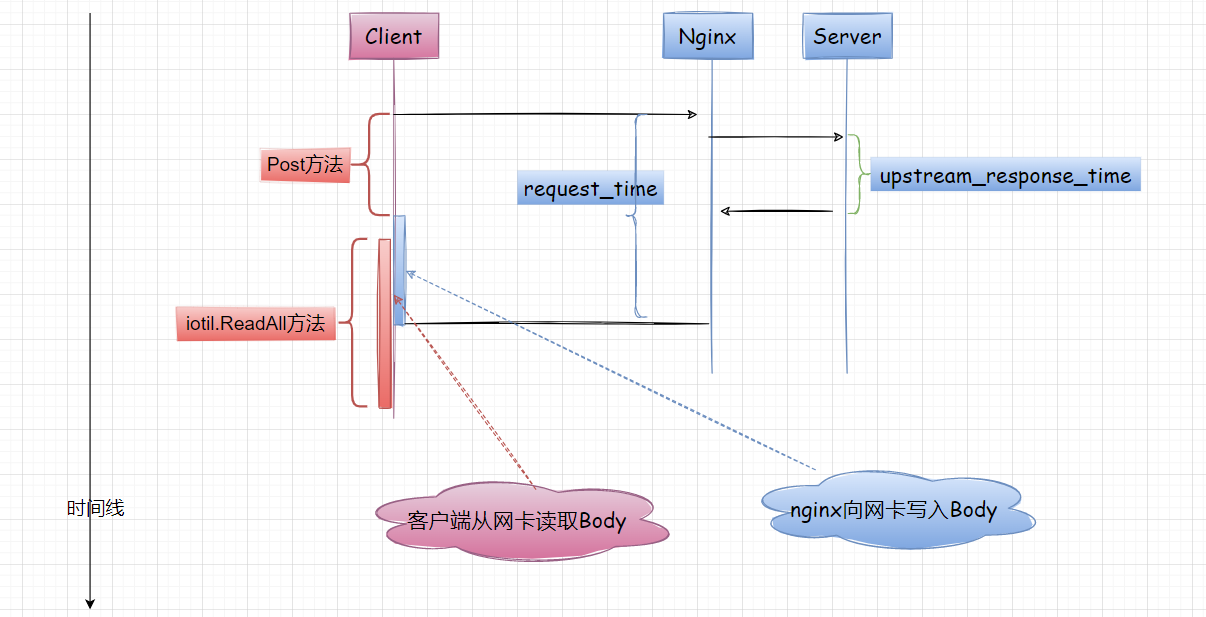
所以[读取 Body 超时]位于图中的红框区域,这就有点意思了。
之前我们有 30%概率[读取 Body 超时],确实是因为 Nginx 回传 50M 数据超时,这在 Nginx request_time 上能体现。
本次 Nginx 显示 request_time=32s, 却再次超时,推断 Nginx 已经写完数据,而客户端还没有读取完 Body。
至于为什么没读取完,这就得吐槽
iotil.ReadAll的性能了。
客户端使用 iotil.ReadAll 读取大的响应体,会不断申请内存(源码显示会从 512B->50M),耗时较长,性能较差、并且有内存泄漏的风险, 下一篇我会讲解针对大的响应体替换iotil.ReadAll的方案。
为了模拟这个偶发的情况,我们可在Post、iotil.ReadAll前后加入时间日志。
$ go run main.go
2022/01/07 20:21:46 开始请求: 2022-01-07 20:21:46.010
2022/01/07 20:21:47 服务端处理结束: 2022-01-07 20:21:47.010
2022/01/07 20:21:52 客户端读取结束: 2022-01-07 20:21:52.010
2022/01/07 20:21:52 response body length: 50575756
可以看出,当读取大的响应体时候,客户端iotil.ReadAll的耗时并不算小,这块需要开发人员重视。
我们甚至可以iotil.ReadAll之前time.Sleep(xxx), 就能轻松模拟出生产环境的读取 Body 超时。
我的收获
- Nginx Access Log 的时间含义
- go 的 HttpClient Timeout 包含了连接、请求、读取 Body 的耗时
- 通过对[读取 Body 超时异常]的分析,我梳理了端到端的请求耗时、客户端的行为耗时的时空关系, 这个至关重要。
深度分析 [go的HttpClient读取Body超时]的更多相关文章
- MapReduce深度分析(二)
MapReduce深度分析(二) 五.JobTracker分析 JobTracker是hadoop的重要的后台守护进程之一,主要的功能是管理任务调度.管理TaskTracker.监控作业执行.运行作业 ...
- [转帖]深度分析HBase架构
深度分析HBase架构 https://zhuanlan.zhihu.com/p/30414252 原文链接(https://mapr.com/blog/in-depth-look-hbase-a ...
- MapReduce深度分析(一)
MapReduce深度分析(一) 一.数据流向分析 图为MapReduce数据流向示意图 步骤1.输入文件从HDFS流向到Mapper节点.在一般情况下,存储数据的节点就是Mapper运行的节点,不需 ...
- HttpClient设置连接超时时间
https://www.cnblogs.com/winner-0715/p/7087591.html 使用HttpClient,一般都需要设置连接超时时间和获取数据超时时间.这两个参数很重要,目的是为 ...
- (转)Memcached深度分析
转自:http://jwen.iteye.com/blog/1123991 memcached是高性能的分布式内存缓存服务器.一般的使用目的是,通过缓存数据库查询结果,减少数据库访问次数,以提高动态W ...
- HttpClient库设置超时
HttpClient库API跟Lucene一样,每个版本的API都变化很大,这有点让人头疼.就好比创建一个HttpClient对象吧,每一个版本的都不一样. 3.X是正常的Java语法 HttpCli ...
- Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Job Manager 启动
Job Manager 启动 https://t.zsxq.com/AurR3rN 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Mac ...
- Flink 源码解析 —— Standalone Session Cluster 启动流程深度分析之 Task Manager 启动
Task Manager 启动 https://t.zsxq.com/qjEUFau 博客 1.Flink 从0到1学习 -- Apache Flink 介绍 2.Flink 从0到1学习 -- Ma ...
- 从Wannacry到WannaRen:螣龙安科带你深度分析勒索病毒原理
从Wannacry到WannaRen:螣龙安科2020年4月7日,360CERT监测发现网络上出现一款新型勒索病毒wannaRen,该勒索病毒会加密windows系统中几乎所有的文件,并且以.Wann ...
随机推荐
- Excel如何使用vlookup
一.vlookup的语法 VLOOKUP (lookup_value, table_array, col_index_num, [range_lookup]) ①Lookup_value为需要在数据表 ...
- MQTT协议 - arduino ESP32 通过精灵一号 MQTT Broker 进行通讯的代码详解
前言 之前研究了一段时间的 COAP 协议结果爱智那边没有测试工具,然后 arduino 也没有找到合适的库,我懒癌发作也懒得修这库,就只能非常尴尬先暂时放一放了.不过我在 爱智APP -> 设 ...
- supermarket(uaf)!!!!
在这道题目我花费了很长的时间去理解,因为绕进了死圈子 例行检查我就不放了 关键处在于选择5 使用了realloc,却没有让结构体指针node-> description正确指回去 (11条消息) ...
- 筛选Table.SelectRows-文本与数值(Power Query 之 M 语言)
数据源: 包含文本与数值的任意数据 目标: 对文本和数值进行筛选 M公式: = Table.SelectRows( 表, 筛选条件) 筛选条件: 等于:each [指定列] = "指定值&q ...
- Python3.6+Django2.0以上 xadmin站点的配置和使用
1. xadmin的介绍 django自带的admin站点虽然功能强大,但是界面不是很好看.而xadmin界面好看,功能更强大,并完全支持Bootstrap主题模板.xadmin内置了丰富的插件功能. ...
- CF31A Worms Evolution 题解
Content 有一个长度为 \(n\) 的数组 \(a_1,a_2,a_3,...,a_n\),试找出一个三元组 \((i,j,k)\),使得 \(a_i=a_j+a_k\). 数据范围:\(3\l ...
- java 图形化工具Swing 监听键盘输入字符触发动作getInputMap();getActionMap();
双缓冲技术的介绍: 所有的Swing组件默认启用双缓冲绘图技术.使用双缓冲技术能改进频繁重绘GUI组件的显示效果(避免闪烁现象)JComponent组件默认启用双缓冲,无须自己实现双缓冲.如果想关闭双 ...
- 10-2 bonding
创建bonding设备的配置文件 centos8 /etc/sysconfig/network-scripts/ifcfg-bond0 NAME=bond0 TYPE=bond DEVICE=bond ...
- sql改写优化:简单规则重组实现
我们知道sql执行是一个复杂的过程,从sql到逻辑计划,到物理计划,规则重组,优化,执行引擎,都是很复杂的.尤其是优化一节,更是内容繁多.那么,是否我们本篇要来讨论这个问题呢?答案是否定的,我们只特定 ...
- windows10源码编译llvm
准备 cmake, 我目前使用的版本是3.18 llvm 源码, 我下载的是 11.0 我已经具备Vs2015和Vs2017的开发环境. debug模式编译需要较多内存和较多硬盘存储空间. (debu ...