二、mongo集群搭建
系列导航
五、mongo备份篇 mongoexport、mongoimport 以及mongodump、mongorestore
在生成环境中单机应用怎么能行必须要集群才能实现高可用,如下是总结网上比较好的例子并得到亲手实验的结果,希望对后来的学习者提供一些帮助。
相关概念
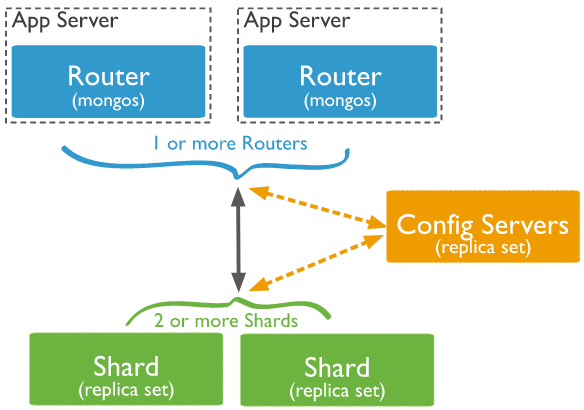
从图中可以看到有四个组件:mongos、config server、shard、replica set。
mongos:数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器,mongos自己就是一个请求分发中心,它负责把对应的数据请求请求转发到对应的shard服务器上。在生产环境通常有多mongos作为请求的入口,防止其中一个挂掉所有的mongodb请求都没有办法操作。
config server:顾名思义为配置服务器,存储所有数据库元信息(路由、分片)的配置。mongos本身没有物理存储分片服务器和数据路由信息,只是缓存在内存里,配置服务器则实际存储这些数据。mongos第一次启动或者关掉重启就会从 config server 加载配置信息,以后如果配置服务器信息变化会通知到所有的 mongos 更新自己的状态,这样 mongos 就能继续准确路由。在生产环境通常有多个 config server 配置服务器,因为它存储了分片路由的元数据,防止数据丢失!
shard:分片(sharding)是指将数据库拆分,将其分散在不同的机器上的过程。将数据分散到不同的机器上,不需要功能强大的服务器就可以存储更多的数据和处理更大的负载。基本思想就是将集合切成小块,这些块分散到若干片里,每个片只负责总数据的一部分,最后通过一个均衡器来对各个分片进行均衡(数据迁移)。
replica set:中文翻译副本集,其实就是shard的备份,防止shard挂掉之后数据丢失。复制提供了数据的冗余备份,并在多个服务器上存储数据副本,提高了数据的可用性, 并可以保证数据的安全性。
补充:仲裁者(Arbiter),是复制集中的一个MongoDB实例,它并不保存数据。仲裁节点使用最小的资源并且不要求硬件设备,不能将Arbiter部署在同一个数据集节点中,可以部署在其他应用服务器或者监视服务器中,也可部署在单独的虚拟机中。为了确保复制集中有奇数的投票成员(包括primary),需要添加仲裁节点做为投票,否则primary不能运行时不会自动切换primary。
简单了解之后,我们可以这样总结一下,应用请求mongos来操作mongodb的增删改查,配置服务器存储数据库元信息,并且和mongos做同步,数据最终存入在shard(分片)上,为了防止数据丢失同步在副本集中存储了一份,仲裁在数据存储到分片的时候决定存储到哪个节点。
环境
操作系统:Red Hat Enterprise Linux Server release 6.1 (Santiago)
安装包:mongodb-linux-x86_64-rhel62-v3.4-latest.tgz
三台服务器:192.168.0.1,192.168.0.2,192.168.0.3
服务器规划
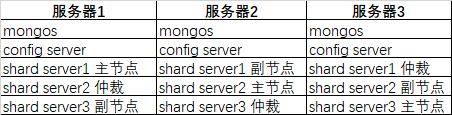
端口分配:
mongos:20000
config:21000
shard1:27001
shard2:27002
shard3:27003集群搭建
1、安装mongodb
将mongodb-linux-x86_64-rhel62-v3.4-latest.tgz放到/usr/local/下
#解压
cd /usr/local/
tar -xzvf mongodb-linux-x86_64-rhel62-v3.4-latest.tgz
#改名
mv mongodb-linux-x86_64-rhel62-v3.4-latest分别在每台机器建立conf、mongos、config、shard1、shard2、shard3六个目录,因为mongos不存储数据,只需要建立日志文件目录即可。
mkdir -p /usr/local/mongodb/conf
mkdir -p /usr/local/mongodb/mongos/log
mkdir -p /usr/local/mongodb/config/data
mkdir -p /usr/local/mongodb/config/log
mkdir -p /usr/local/mongodb/shard1/data
mkdir -p /usr/local/mongodb/shard1/log
mkdir -p /usr/local/mongodb/shard2/data
mkdir -p /usr/local/mongodb/shard2/log
mkdir -p /usr/local/mongodb/shard3/data
mkdir -p /usr/local/mongodb/shard3/log配置环境变量
vim /etc/profile
# 内容
export MONGODB_HOME=/usr/local/mongodb
export PATH=$MONGODB_HOME/bin:$PATH
# 使立即生效
source /etc/profile2、config server配置服务器
添加配置文件
vi /usr/local/mongodb/conf/config.conf
## 配置文件内容
pidfilepath = /usr/local/mongodb/config/log/configsrv.pid
dbpath = /usr/local/mongodb/config/data
logpath = /usr/local/mongodb/config/log/congigsrv.log
logappend = true
bind_ip = 0.0.0.0
port = 21000
fork = true
#declare this is a config db of a cluster;
configsvr = true
#副本集名称
replSet=configs
#设置最大连接数
maxConns=20000启动三台服务器的config server
mongod -f /usr/local/mongodb/conf/config.conf登录任意一台配置服务器,初始化配置副本集
#连接
mongo --port 21000
#config变量
config = {
... _id : "configs",
... members : [
... {_id : 0, host : "192.168.0.1:21000" },
... {_id : 1, host : "192.168.0.2:21000" },
... {_id : 2, host : "192.168.0.3:21000" }
... ]
... }
#初始化副本集
rs.initiate(config)其中,"_id" : "configs"应与配置文件中配置的 replicaction.replSetName 一致,"members" 中的 "host" 为三个节点的 ip 和 port
3、配置分片副本集(三台机器)
设置第一个分片副本集
配置文件
vi /usr/local/mongodb/conf/shard1.conf
#配置文件内容
#——————————————–
pidfilepath = /usr/local/mongodb/shard1/log/shard1.pid
dbpath = /usr/local/mongodb/shard1/data
logpath = /usr/local/mongodb/shard1/log/shard1.log
logappend = true
bind_ip = 0.0.0.0
port = 27001
fork = true
#打开web监控
httpinterface=true
rest=true
#副本集名称
replSet=shard1
#declare this is a shard db of a cluster;
shardsvr = true
#设置最大连接数
maxConns=20000启动三台服务器的shard1 server
mongod -f /usr/local/mongodb/conf/shard1.conf登陆任意一台服务器,初始化副本集
mongo --port 27001
#使用admin数据库
use admin
#定义副本集配置,第三个节点的 "arbiterOnly":true 代表其为仲裁节点。
config = {
... _id : "shard1",
... members : [
... {_id : 0, host : "192.168.0.1:27001" },
... {_id : 1, host : "192.168.0.2:27001" },
... {_id : 2, host : "192.168.0.3:27001” , arbiterOnly: true }
... ]
... }
#初始化副本集配置
rs.initiate(config);
设置第二个分片副本集
配置文件
vi /usr/local/mongodb/conf/shard2.conf
#配置文件内容
#——————————————–
pidfilepath = /usr/local/mongodb/shard2/log/shard2.pid
dbpath = /usr/local/mongodb/shard2/data
logpath = /usr/local/mongodb/shard2/log/shard2.log
logappend = true
bind_ip = 0.0.0.0
port = 27002
fork = true
#打开web监控
httpinterface=true
rest=true
#副本集名称
replSet=shard2
#declare this is a shard db of a cluster;
shardsvr = true
#设置最大连接数
maxConns=20000启动三台服务器的shard2 server
mongod -f /usr/local/mongodb/conf/shard2.conf登陆任意一台服务器,初始化副本集
mongo --port 27002
#使用admin数据库
use admin
#定义副本集配置
config = {
... _id : "shard2",
... members : [
... {_id : 0, host : "192.168.0.1:27002" , arbiterOnly: true },
... {_id : 1, host : "192.168.0.2:27002" },
... {_id : 2, host : "192.168.0.3:27002" }
... ]
... }
#初始化副本集配置
rs.initiate(config);设置第三个分片副本集
配置文件
vi /usr/local/mongodb/conf/shard3.conf
#配置文件内容
#——————————————–
pidfilepath = /usr/local/mongodb/shard3/log/shard3.pid
dbpath = /usr/local/mongodb/shard3/data
logpath = /usr/local/mongodb/shard3/log/shard3.log
logappend = true
bind_ip = 0.0.0.0
port = 27003
fork = true
#打开web监控
httpinterface=true
rest=true
#副本集名称
replSet=shard3
#declare this is a shard db of a cluster;
shardsvr = true
#设置最大连接数
maxConns=20000启动三台服务器的shard3 server
mongod -f /usr/local/mongodb/conf/shard3.conf登陆任意一台服务器,初始化副本集
mongo --port 27003
#使用admin数据库
use admin
#定义副本集配置
config = {
... _id : "shard3",
... members : [
... {_id : 0, host : "192.168.0.1:27003" },
... {_id : 1, host : "192.168.0.2:27003" , arbiterOnly: true},
... {_id : 2, host : "192.168.0.3:27003" }
... ]
... }
#初始化副本集配置
rs.initiate(config);4、配置路由服务器 mongos
先启动配置服务器和分片服务器,后启动路由实例启动路由实例:(三台机器)
vi /usr/local/mongodb/conf/mongos.conf
#内容
pidfilepath = /usr/local/mongodb/mongos/log/mongos.pid
logpath = /usr/local/mongodb/mongos/log/mongos.log
logappend = true
bind_ip = 0.0.0.0
port = 20000
fork = true
#监听的配置服务器,只能有1个或者3个 configs为配置服务器的副本集名字
configdb = configs/192.168.0.1:21000,192.168.0.2:21000,192.168.0.3:21000
#设置最大连接数
maxConns=20000启动三台服务器的mongos server
mongos -f /usr/local/mongodb/conf/mongos.conf5、启用分片
目前搭建了mongodb配置服务器、路由服务器,各个分片服务器,不过应用程序连接到mongos路由服务器并不能使用分片机制,还需要在程序里设置分片配置,让分片生效。
登陆任意一台mongos
mongo --port 20000
#使用admin数据库
user admin
#串联路由服务器与分配副本集
sh.addShard("shard1/192.168.0.1:27001,192.168.0.2:27001,192.168.0.3:27001")
sh.addShard("shard2/192.168.0.1:27002,192.168.0.2:27002,192.168.0.3:27002")
sh.addShard("shard3/192.168.0.1:27003,192.168.0.2:27003,192.168.0.3:27003")
#查看集群状态
sh.status()6、测试
目前配置服务、路由服务、分片服务、副本集服务都已经串联起来了,但我们的目的是希望插入数据,数据能够自动分片。连接在mongos上,准备让指定的数据库、指定的集合分片生效。
#使用admin数据库
user admin
#指定testdb分片生效
db.runCommand( { enablesharding :"testdb"});
#指定数据库里需要分片的集合和片键
db.runCommand( { shardcollection : "testdb.person",key : {_id:'hashed'} } )
>use testdb
插入一些数据到person中,然后执行如下语句查看数据是否分在不同的分片上,如果是就成功了。
for (var i = 1; i <= 100000; i++)
db.person.save({id:i,"name":"hahah"});
>db.person.getShardDistribution();
7、启动关闭
mongodb的启动顺序是,先启动配置服务器,在启动分片,最后启动mongos.
numactl --interleave=all /opt/mongodb/bin/mongod -f /opt/mongodb/conf/config.conf;
numactl --interleave=all /opt/mongodb/bin/mongod -f /opt/mongodb/conf/shard1.conf;
numactl --interleave=all /opt/mongodb/bin/mongod -f /opt/mongodb/conf/shard2.conf;
numactl --interleave=all /opt/mongodb/bin/mongod -f /opt/mongodb/conf/shard3.conf;
numactl --interleave=all /opt/mongodb/bin/mongos -f /opt/mongodb/conf/mongos.conf;
关闭时
/opt/mongodb/bin/mongod -f /opt/mongodb/conf/config.conf -shutdown;
/opt/mongodb/bin/mongod -f /opt/mongodb/conf/shard1.conf -shutdown;
/opt/mongodb/bin/mongod -f /opt/mongodb/conf/shard2.conf -shutdown;
/opt/mongodb/bin/mongod -f /opt/mongodb/conf/shard3.conf -shutdown;
/opt/mongodb/bin/mongos -f /opt/mongodb/conf/mongos.conf -shutdown;如果关闭失败直接killall杀掉所有进程
killall mongod
killall mongos
二、mongo集群搭建的更多相关文章
- 高可用性的mongo集群搭建
mongoDB安装 参照:https://docs.mongodb.com/manual/tutorial/install-mongodb-on-red-hat/ 配置yum管理包 在路径/etc/y ...
- Zookeeper(二) zookeeper集群搭建 与使用
一.zookeeper集群搭建 鉴于 zookeeper 本身的特点,服务器集群的节点数推荐设置为奇数台.我这里我规划为三台, 为别为 hadoop01,hadoop02,hadoop03 1. ...
- Mongo集群搭建
1.集群角色及架构 在搭建集群之前,需要首先了解几个概念:路由,分片.副本集.配置服务器等 mongos,数据库集群请求的入口,所有的请求都通过mongos进行协调,不需要在应用程序添加一个路由选择器 ...
- kafka学习(二)-zookeeper集群搭建
zookeeper概念 ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,它包含一个简单的原语集,分布式应用程序可以基于它实现同步服务,配置维护和命名 服务等.Zookeeper是h ...
- Kafka 详解(二)------集群搭建
这里通过 VMware ,我们安装了三台虚拟机,用来搭建 kafka集群,虚拟机网络地址如下: hostname ipaddress ...
- Etcd学习(二)集群搭建Clustering
1.单个etcd节点(测试开发用) 之前我一直开发测试一直是用的一个Etcd节点,然后启动命令一直都是直接打一个etcd(我已经将etcd安装目录的bin目录加入到PATH环 境变量中),然后启动信息 ...
- Zookeeper学习之路 (二)集群搭建
ZooKeeper 软件安装须知 鉴于 ZooKeeper 本身的特点,服务器集群的节点数推荐设置为奇数台.我这里我规划为三台, 为别为 hadoop1,hadoop2,hadoop3 ZooKeep ...
- Storm实践(二):集群搭建
集群规划 角色 IP hostname nimbus 192.168.100.101 dda supervisor 192.168.100.102 ddb supervisor 192.168.100 ...
- elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理)
一.集群规划 搭建一个集群我们需要考虑如下几个问题: 1. 我们需要多大规模的集群? 2. 集群中的节点角色如何分配? 3. 如何避免脑裂问题? 4. 索引应该设置多少个分片? 5. 分片应该设置几个 ...
- 【转载】KETTLE集群搭建
一.集群的原理与优缺点 1.1集群的原理 Kettle集群是由一个主carte服务器和多个从carte服务器组成的,类似于master-slave结构,不同的是’master’处理具体任务,只负责任务 ...
随机推荐
- 231106-jmeter随笔
1. 获取接口的执行时间 String ctime = prev.getTime().toString();2. String转int int c = Integer.parseInt(ctime); ...
- 使用Druid解析SQL实现血缘关系计算
import com.alibaba.druid.sql.SQLUtils; import com.alibaba.druid.sql.ast.SQLStatement; import com.ali ...
- MySQL运维3-分库分表策略
一.介绍 单库瓶颈:如果在项目中使用的都是单MySQL服务器,则会随着互联网及移动互联网的发展,应用系统的数据量也是成指数式增长,若采用单数据库进行存储,存在一下性能瓶颈: IO瓶颈:热点数据太多,数 ...
- lca(数链剖分)板子
#include<bits/stdc++.h> #define endl '\n' #define int long long using namespace std; const int ...
- 华企盾DSC登录控制台提示查询数据库错误
解决方法:服务器防火墙已经关了,查看控制台日志,如出现下图2问题升级到最新版即可解决,否则需要找研发处理
- WebView中的页面调试方法
在 iOS 12 中,苹果正式弃用 UIWebView,改成 WKWebView,参考官方声明. 后者在性能.稳定性.功能方面有很大提升,并且与 Safari 具有相同的 JavaScript 引擎( ...
- shell中 << EOF 和 EOF 使用
转载请注明出处: EOF(End of File)在Shell中通常用于指示输入的结束,并在脚本或命令中进行多行输入.它允许用户指定一个特定的分界符来表示输入的结束,通常用于创建临时文件.重定向输入或 ...
- C#/.NET/.NET Core优秀项目和框架2023年12月简报
前言 公众号每月定期推广和分享的C#/.NET/.NET Core优秀项目和框架(公众号每周至少推荐两个优秀的项目和框架当然节假日除外),公众号推文有项目和框架的介绍.功能特点以及部分功能截图等(打不 ...
- 文心一言 VS 讯飞星火 VS chatgpt (171)-- 算法导论13.2 4题
四.用go语言,证明:任何一棵含n个结点的二叉搜索树可以通过 O(n)次旋转,转变为其他任何一棵含n个结点的二叉搜索树.(提示:先证明至多n-1次右旋足以将树转变为一条右侧伸展的链.) 文心一言: 这 ...
- P4928 [MtOI2018]衣服?身外之物! 题解
题意 gcd 共有 \(n\) 件衣服,编号为 \(A_1,A_2,\cdots A_n\). 每一件衣服分别拥有颜色值和清洗时间,他在每一件衣服穿完以后都会将其送去清洗,而这件衣服当天所拥有的舒适感 ...