ByteHouse+Apache Airflow:高效简化数据管理流程
Apache Airflow 与 ByteHouse 相结合,为管理和执行数据流程提供了强大而高效的解决方案。本文突出了使用 Apache Airflow 与 ByteHouse 的主要优势和特点,展示如何简化数据工作流程并推动业务成功。
主要优势
可扩展可靠的数据流程:Apache Airflow 提供了一个强大的平台,用于设计和编排数据流程,让您轻松处理复杂的工作流程。搭配 ByteHouse,一款云原生的数据仓库解决方案,您可以高效地存储和处理大量数据,确保可扩展性和可靠性。
自动化工作流管理:Airflow 的直观界面通过可视化的 DAG(有向无环图)编辑器,使得创建和调度数据工作流程变得容易。通过与 ByteHouse 集成,您可以自动化提取、转换和加载(ETL)过程,减少手动工作量,实现更高效的数据管理。
简单的部署和管理:Apache Airflow 和 ByteHouse 均设计为简单的部署和管理。Airflow 可以部署在本地或云端,而 ByteHouse 提供完全托管的云原生数据仓库解决方案。这种组合使得数据基础设施的设置和维护变得无缝化。
客户场景
业务场景
在这个客户场景中,一家名为“数据洞察有限公司(假名)”的分析公司,他们将 Apache Airflow 作为数据管道编排工具。他们选择 ByteHouse 作为数据仓库解决方案,以利用其强大的分析和机器学习功能。
数据洞察有限公司在电子商务行业运营,并收集存储在 AWS S3 中的大量客户和交易数据。他们需要定期将这些数据加载到 ByteHouse,并执行各种分析任务,以获得对业务运营的洞察。
数据链路
使用 Apache Airflow,数据洞察有限公司设置了一个基于特定事件或时间表的数据加载管道。例如,他们可以配置 Airflow 在每天的特定时间触发数据加载过程,或者当新的数据文件添加到指定的 AWS S3 存储桶时触发。当触发事件发生时,Airflow 通过从 AWS S3 中检索相关数据文件来启动数据加载过程。它使用适当的凭据和 API 集成确保与 S3 存储桶的安全身份验证和连接。一旦数据从 AWS S3 中获取,Airflow 会协调数据的转换和加载到 ByteHouse 中。它利用 ByteHouse 的集成能力,根据预定义的模式和数据模型高效地存储和组织数据。
成功将数据加载到 ByteHouse 后,数据洞察有限公司可以利用 ByteHouse 的功能进行分析和机器学习任务。他们可以使用 ByteHouse 的类 SQL 语言查询数据,进行复杂的分析,生成报告,并揭示有关客户、销售趋势和产品性能的有意义洞察。
此外,数据洞察有限公司还利用 ByteHouse 的功能创建交互式仪表板和可视化。他们可以构建动态仪表板,显示实时指标,监控关键绩效指标,并与组织中的利益相关者共享可操作的洞察。
最后,数据洞察有限公司利用 ByteHouse 的机器学习功能来开发预测模型、推荐系统或客户细分算法。ByteHouse 提供了必要的计算能力和存储基础设施,用于训练和部署机器学习模型,使数据洞察有限公司能够获得有价值的预测性和规定性洞察。
总结
通过使用 Apache Airflow 作为数据管道编排工具,并将其与 ByteHouse 集成,数据洞察有限公司实现了从 AWS S3 加载数据到 ByteHouse 的流畅自动化流程。他们充分利用 ByteHouse 的强大分析、机器学习和仪表板功能,获得有价值的洞察,并推动组织内的数据驱动。
ByteHouse<>AirFlow 快速入门
先决条件
在您的虚拟/本地环境中安装 pip。在您的虚拟/本地环境中安装 ByteHouse CLI 并登录到 ByteHouse 账户。参考 ByteHouse CLI 以获取安装帮助。macOS 上使用 Homebrew 的示例brew install bytehouse-cli
安装 Apache Airflow
在本教程中,我们使用 pip 在您的本地或虚拟环境中安装 Apache Airflow。了解更多信息,请参阅官方 Airflow 文档。
# airflow需要一个目录,~/airflow是默认目录,
# 但如果您喜欢,可以选择其他位置
#(可选)
export AIRFLOW_HOME=~/airflow AIRFLOW_VERSION=2.1.3
PYTHON_VERSION="$(python --version | cut -d " " -f 2 | cut -d "." -f 1-2)" # 例如:3.6
CONSTRAINT_URL="https://raw.githubusercontent.com/apache/airflow/constraints-${AIRFLOW_VERSION}/constraints-${PYTHON_VERSION}.txt"
pip install "apache-airflow==${AIRFLOW_VERSION}" --constraint "${CONSTRAINT_URL}"
如果使用 pip 无法安装,请尝试使用 pip3 install 进行安装。安装完成后,运行命令 airflow info 以获取有关 Airflow 的更多信息。
Airflow 初始化
通过执行以下命令来初始化 Airflow 的 Web 服务器
# 初始化数据库
airflow db init airflow users create \
--username admin \
--firstname admin \
--lastname admin \
--role Admin \
--email admin # 启动Web服务器,默认端口是8080
# 或修改airflow.cfg设置web_server_port
airflow webserver --port 8080
设置好 Web 服务器后,您可以访问 http://localhost:8080/使用先前设置的用户名和密码登录 Airflow 控制台。
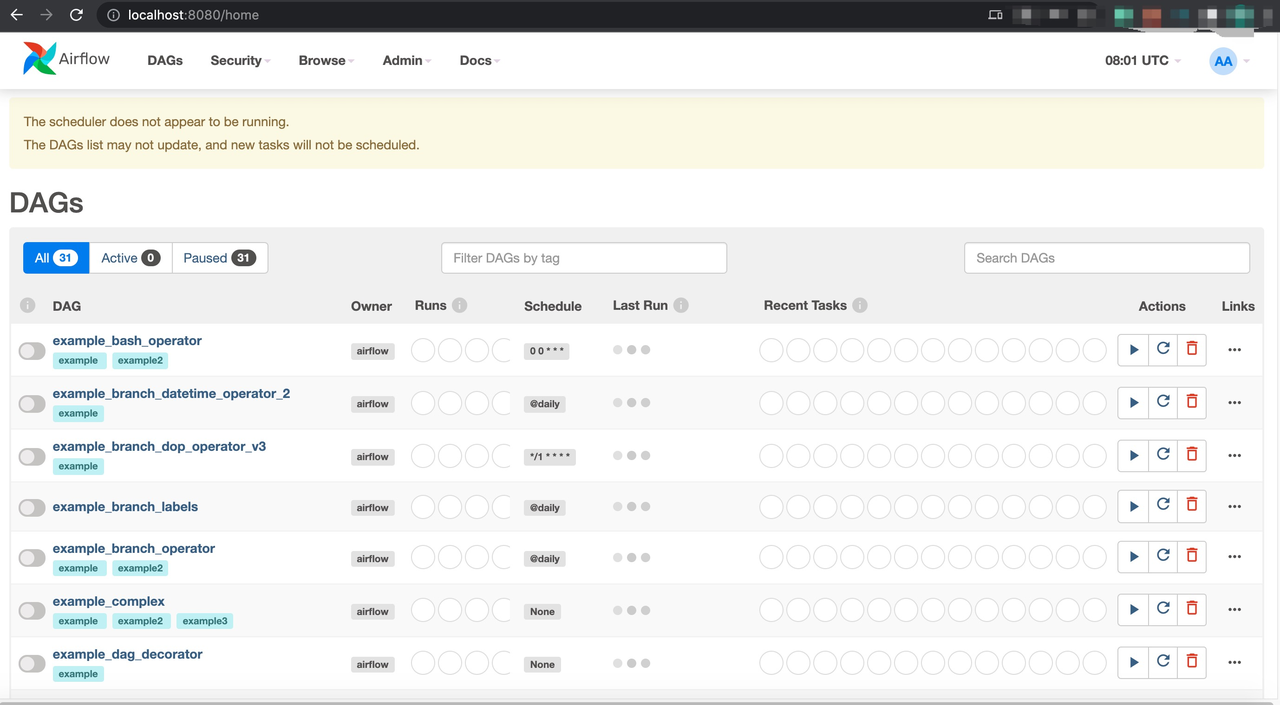
在新的终端中,使用以下命令设置 Airflow 调度器。然后,刷新 http://localhost:8080/。
YAML 配置
使用 cd ~/airflow 命令进入 Airflow 文件夹。打开名为 airflow.cfg 的配置文件。添加配置并连接到数据库。默认情况下,您可以使用 SQLite,但也可以连接到 MySQL。
# 默认情况下是SQLite,也可以连接到MySQL
sql_alchemy_conn = mysql+pymysql://airflow:airflow@xxx.xx.xx.xx:8080/airflow # authenticate = False
# 禁用Alchemy连接池以防止设置Airflow调度器时出现故障 https://github.com/apache/airflow/issues/10055
sql_alchemy_pool_enabled = False # 存放Airflow流水线的文件夹,通常是代码库中的子文件夹。该路径必须是绝对路径。
dags_folder = /home/admin/airflow/dags
创建有向无环图(DAG)作业
在 Airflow 路径下创建一个名为 dags 的文件夹,然后创建 test_bytehouse.py 以启动一个新的 DAG 作业。
~/airflow
mkdir dags
cd dags
nano test_bytehouse.py
在 test_bytehouse.py 中添加以下代码。该作业可以连接到 ByteHouse CLI,并使用 BashOperator 运行任务、查询或将数据加载到 ByteHouse 中。
from datetime import timedelta
from textwrap import dedent from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.utils.dates import days_ago default_args = {
'owner': 'airflow',
'depends_on_past': False,
'email': ['airflow@example.com'],
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
with DAG(
'test_bytehouse',
default_args=default_args,
description='A simple tutorial DAG',
schedule_interval=timedelta(days=1),
start_date=days_ago(1),
tags=['example'],
) as dag: tImport = BashOperator(
task_id='ch_import',
depends_on_past=False,
bash_command='$Bytehouse_HOME/bytehouse-cli -cf /root/bytehouse-cli/conf.toml "INSERT INTO korver.cell_towers_1 FORMAT csv INFILE \'/opt/bytehousecli/data.csv\' "',
) tSelect = BashOperator(
task_id='ch_select',
depends_on_past=False,
bash_command='$Bytehouse_HOME/bytehouse-cli -cf /root/bytehouse-cli/conf.toml -q "select * from korver.cell_towers_1 limit 10 into outfile \'/opt/bytehousecli/dataout.csv\' format csv "'
) tSelect >> tImport
在当前文件路径下运行 python test_bytehouse.py 以在 Airflow 中创建 DAG。在浏览器中刷新网页。您可以在 DAG 列表中看到新创建的名为 test_bytehouse 的 DAG。
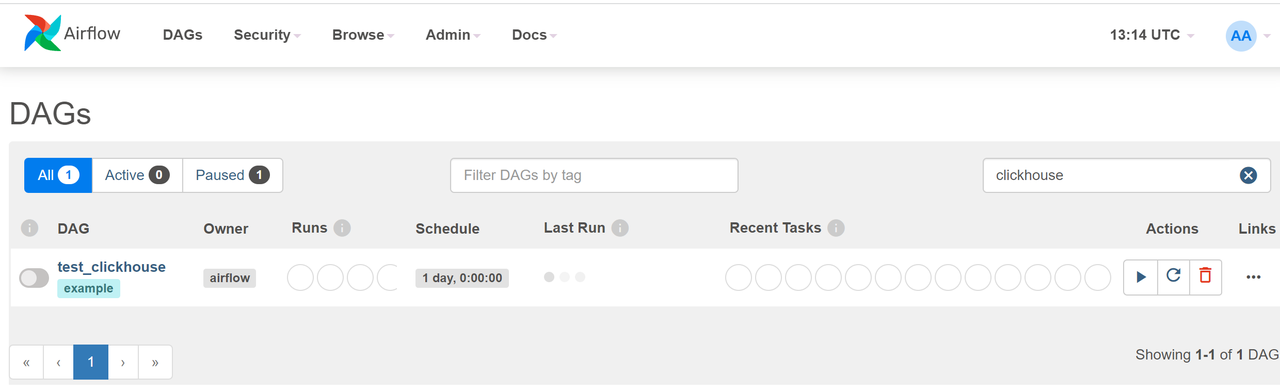
执行 DAG
在终端中运行以下 Airflow 命令来查看 DAG 列表和 test_bytehouse DAG 中的子任务。您可以分别测试查询执行和数据导入任务。
#打印"test_bytehouse" DAG中的任务列表
[root@VM-64-47-centos dags]# airflow tasks list test_bytehouse
ch_import
ch_select #打印"test_bytehouse" DAG中任务的层次结构
[root@VM-64-47-centos dags]# airflow tasks list test_bytehouse --tree
<Task(BashOperator): ch_select>
<Task(BashOperator): ch_import>
运行完 DAG 后,查看您的 ByteHouse 账户中的查询历史页面和数据库模块。您应该能够看到查询/加载数据成功执行的结果。
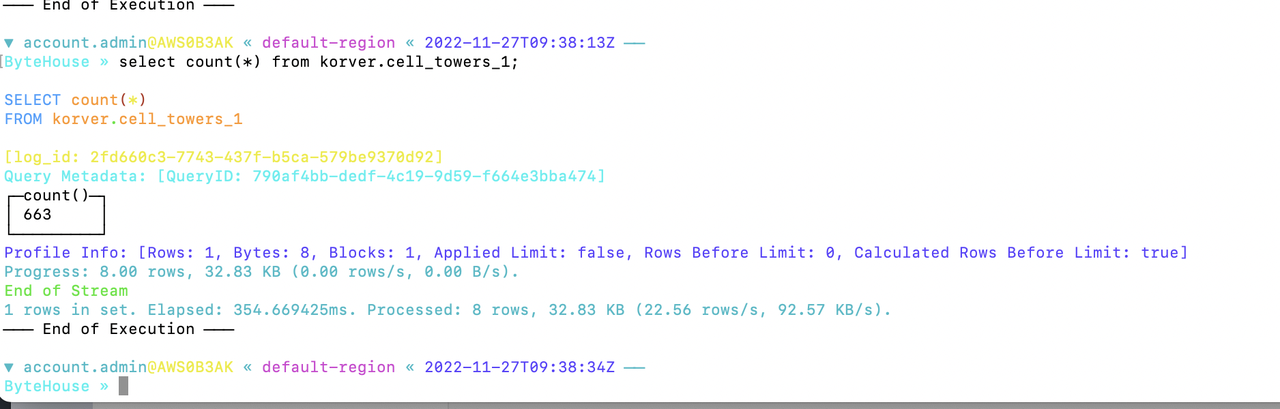
ByteHouse+Apache Airflow:高效简化数据管理流程的更多相关文章
- 任务调度工具 Apache Airflow 初识
参考文章: Apache Airflow (incubating) Documentation — Airflow ... 任务调度神器 airflow 之初体验 airflow 介绍 - 简书(原文 ...
- Nginx为什么比Apache Httpd高效
转载于:http://www.toxingwang.com/linux-unix/linux-basic/1712.html 一.进程.线程? 在回答nginx 为什么比apache更高效之前,必须要 ...
- SpringCloud+Eureka+Feign+Ribbon的简化搭建流程,加入熔断,网关和Redis缓存[2]
目录 前提:本篇是基于 SpringCloud+Eureka+Feign+Ribbon的简化搭建流程和CRUD练习[1] 的修改与拓展 1.修改consumer的CenterFeign.java,把返 ...
- 在 Docker 上快速运行 Apache Airflow 2.2.4
Docker 安装 Apache Airflow 参考资料 Running Airflow in Docker 安装依赖 Docker Engine Docker Composite 快速运行 Apa ...
- Nginx为什么比Apache Httpd高效:原理篇
一.进程.线程? 进程是具有一定独立功能的,在计算机中已经运行的程序的实体.在早期系统中(如linux 2.4以前),进程是基本运作单位,在支持线程的系统中(如windows,linux2.6)中,线 ...
- apache airflow docker 运行简单试用
airflow 是一个编排.调度和监控workflow的平台,由Airbnb开源,现在在Apache Software Foundation 孵化. airflow 将workflow编排为tasks ...
- DolphinDB +Python Airflow 高效实现数据清洗
DolphinDB 作为一款高性能时序数据库,其在实际生产环境中常有数据的清洗.装换以及加载等需求,而对于该如何结构化管理好 ETL 作业,Airflow 提供了一种很好的思路.本篇教程为生产环境中 ...
- apache本地服务器的配置流程
安装Apache 一.目的: 1. 能够有一个测试的服务器,不是所有的特殊网络服务都能找到免费的! 二.为什么是 "Apache" 1. 使用最广的 Web 服务器 2. Mac自 ...
- SpringCloud+Eureka+Feign+Ribbon的简化搭建流程和CRUD练习
作者:个人微信公众号:程序猿的月光宝盒 环境:win10--idea2019--jdk8 1.搭建Eureka服务模块 1.1 新建eureka服务模块(Sping Initializr) 取名为eu ...
- SpringCloud+Eureka+Feign+Ribbon+zuul的简化搭建流程和CRUD练习
环境:win10--idea2019--jdk8 1.搭建Eureka服务模块 1.1 新建eureka服务模块(Sping Initializr) 取名为eureka-server,并添加如下Dep ...
随机推荐
- AGC 补题笔记
[AGC001] A.BBQ Easy 由于最大数肯定要和一个比自己小的数搭配保留该数,不如选择保留次大数,如此递归即解.因此将序列排序后输出序号为奇数的数即可. B.Mysterious Light ...
- 数据结构-线性表-单循环链表(使用尾指针)(c++)
目录 单循环链表 说明 注意 (一)无参构造函数 (二)有参构造函数 (三)析构函数 (四)获取长度 (五)打印数组 (六)获取第i个元素的地址 (七)插入 (八)删除 (九)获取值为x的元素的位置 ...
- 阿里Java一面,难度适中!(下篇)
上一次因为文章篇幅和个人精力有限的原因,只分享了淘天的前 6 道题及其答案(点击访问上一篇).接下来,咱们把其他几道题面试题及答案也分享给大家. 1.公司简介 淘天集团就是"淘宝" ...
- 文心一言 VS 讯飞星火 VS chatgpt (140)-- 算法导论11.4 5题
五.用go语言,考虑一个装载因子为a的开放寻址散列表.找出一个非零的a值,使得一次不成功查找的探查期望数是一次成功查找的探查期望数的 2 倍.这两个探查期望数可以使用定理11.6 和定理 11.8 中 ...
- 2. Shell 条件测试
重点: 条件测试. read. Shell 环境配置. case. for. find. xargs. gzip,bzip2,xz. tar. sed. 1)位置 变量 位置变量:在 bash She ...
- CON2 工单重估 效率提升
CON2 工单重估 效率提升 业务背景:月结CON2 每次只能允许一个进程操作 集团公司较多的话,很影响月结效率. SAP提供了专家模式程序 RKAZCON2 ,可以选平行运行 平行处理 需要选服 ...
- 公司要做大数据可视化看板,除了EXCEL以外有没有好用的软件可以用
当企业需要进行大数据可视化看板的设计和开发时,除了Excel,还有许多其他强大且适合大数据可视化的软件工具.以下是几种常用的好用软件,以及它们的特点和优势,供您参考. 一.Datainside 特点和 ...
- 公司敏感数据被上传Github,吓得我赶紧改提交记录
大家好,我是小富- 说个事吧!最近公司发生了一个事故,有同事不小心把敏感数据上传到了GitHub上,结果被安全部门扫描出来了.这件事导致公司对所有员工进行了一次数据安全的培训.对于这个事我相信,有点工 ...
- 2023-12-09:用go语言,给你两个整数数组 arr1 和 arr2, 返回使 arr1 严格递增所需要的最小「操作」数(可能为 0)。 每一步「操作」中,你可以分别从 arr1 和 arr2
2023-12-09:用go语言,给你两个整数数组 arr1 和 arr2, 返回使 arr1 严格递增所需要的最小「操作」数(可能为 0). 每一步「操作」中,你可以分别从 arr1 和 arr2 ...
- 【已解决】【Tensorflow2.12.0版本以后合并CPU和GPU版】Tensorflow-gpu==2.12.0 安装失败解决办法
直接上解决方式,需要知道原因的看后文. 直接安装 tensroflow,从 2022 年 12 月起 tensorflow-gpu 已经合并到 tensorflow 包中了 pip install t ...