再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(3) —— 游戏AI解法设计篇
接前文:
再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(2) —— 游戏环境设计篇 - Hello_BeautifulWorld - 博客园 (cnblogs.com)
=========================================
在前文中主要是大致介绍了 https://gitee.com/devilmaycry812839668/highest_vote_2048_ai 中游戏环境部分的内容,其实游戏环境的实现只介绍了很小一部分,原本打算多说一些,不过后来发现意义价值不大,对于有兴趣研究这个游戏的实现逻辑的人知道这个游戏是用64bit的整数来表示一个游戏状态中16个数字并且每个数字是用半字节4bit来进行表示的就已经足够了,其他剩下的就是如何对这个64bit的整数进行移位操作了,如:transpose函数就是把这个64bit的整数按照游戏状态装置的方式变化为另一个游戏状态的64bit整数,move_0, move_1, move_2, move_3, 则是表示对这个64bit的整数进行上下左右移动操作后变化得到的新状态所表示的64bit整数;而对于那些对这个游戏实现逻辑没有兴趣的人来说自然是没有必要多说这个environment的实现细节了;对于我来说这个游戏实现细节确实不好理解但是要完整的说清楚又显得十分的琐碎和费事,于是也就作罢了。
其实这个系列主要的重点不是说这个游戏的实现,而是如何用AI方式来解决这个游戏。
现在很多人一听说AI就知道深度学习,Deep Learning,机器学习之类的,但是AI这个概念其实是一个比较宽泛的,所包容的内容也是很多的,在某种程度上说方式可以仿造人类去实现某个操作,或是具有人类某项功能的部分能力的方法都可以叫做AI方法,而现在的机器学习方法是AI方法中最为流行的方法,对于当前的CV,NLP等领域有很好的解决能力的一种方法,但这绝不是唯一,在这个《2048》游戏中所使用的方法就是AI方法中的启发式方法,启发式方法这个名字也是十分的唬人,其实启发式算法就是按照一定的规则条件来进行运算的算法,大致形式就是:
IF CONDITION:
DO SOMETHING;
ELSE:
DO ANOTHER SOMETHING;
ENDIF;
个人一般把启发式算法看做是根据预定规则(条件)设计好的算法。
启发式算法是听起来很高大上,实际一看又感觉很平民,那么他实际上的原理在哪呢?因为我们希望利用计算机程序来模仿实现人类的某项能力,说到底就是设计一个具备人类某项能力的算法代码,其中最为直接的方法就是把人类处理某个问题所采用的方法(策略)用条件规则写出来,那么我们编写计算机算法时只要按照这个预设的条件规则来进行设计就可以了。
启发式算法:
人类策略 ===》 计算机可识别的条件规则
那么在这个《2048》游戏中这个启发算法时如何设计的呢?
具体的实现代码:
cpp_source/2048_algorithm.cpp · 鬼&泣/2048-ai - 码云 - 开源中国 (gitee.com)
实现的启发式算法核心代码:
static float heur_score_table[65536]; // Heuristic scoring settings
static const float SCORE_LOST_PENALTY = 200000.0f;
static const float SCORE_MONOTONICITY_POWER = 4.0f;
static const float SCORE_MONOTONICITY_WEIGHT = 47.0f;
static const float SCORE_SUM_POWER = 3.5f;
static const float SCORE_SUM_WEIGHT = 11.0f;
static const float SCORE_MERGES_WEIGHT = 700.0f;
static const float SCORE_EMPTY_WEIGHT = 270.0f; void init_score_table()
{
for (unsigned row = 0; row < 65536; ++row)
{
unsigned line[4] = {
(row >> 0) & 0xf,
(row >> 4) & 0xf,
(row >> 8) & 0xf,
(row >> 12) & 0xf
}; // Heuristic score
float sum = 0;
int empty = 0;
int merges = 0; int prev = 0;
int counter = 0;
for (int i = 0; i < 4; ++i)
{
int rank = line[i];
sum += pow(rank, SCORE_SUM_POWER); if (rank == 0)
{
empty++;
}
else
{
if (prev == rank)
{
counter++;
}
else if (counter > 0)
{
merges += 1 + counter;
counter = 0;
}
prev = rank;
}
} if (counter > 0) {
merges += 1 + counter;
} float monotonicity_left = 0;
float monotonicity_right = 0;
for (int i = 1; i < 4; ++i) {
if (line[i-1] > line[i]) {
monotonicity_left += pow(line[i-1], SCORE_MONOTONICITY_POWER) - pow(line[i], SCORE_MONOTONICITY_POWER);
} else {
monotonicity_right += pow(line[i], SCORE_MONOTONICITY_POWER) - pow(line[i-1], SCORE_MONOTONICITY_POWER);
}
} heur_score_table[row] = SCORE_LOST_PENALTY +
SCORE_EMPTY_WEIGHT * empty +
SCORE_MERGES_WEIGHT * merges -
SCORE_MONOTONICITY_WEIGHT * std::min(monotonicity_left, monotonicity_right) -
SCORE_SUM_WEIGHT * sum;
}
}
在这里启发式算法设计是按照四个预设规则来进行的:(算法中是计算每一行数据中符合规则的值,列是按照转置后按行的方式计算的)
1. 行中空格的数量, 算法中用变量 int empty 来进行计数,权值为 SCORE_EMPTY_WEIGHT = 270.0f ;
2. 行中可以合并的块数,变量为 merges,权值 float SCORE_MERGES_WEIGHT = 700.0f;
3. 行中数字排列的单调性,变量 std::min(monotonicity_left, monotonicity_right), 权值SCORE_MONOTONICITY_WEIGHT;
4. 行中数字的大小,变量sum,权值SCORE_SUM_WEIGHT 。
由于数字越大越不好合并,因此是 -SCORE_SUM_WEIGHT * sum;由于单调性越不好越不利于合并,因此是
-SCORE_MONOTONICITY_WEIGHT * std::min(monotonicity_left, monotonicity_right) 。
最终给每个游戏状态预设的启发值的计算方式为:

========================================
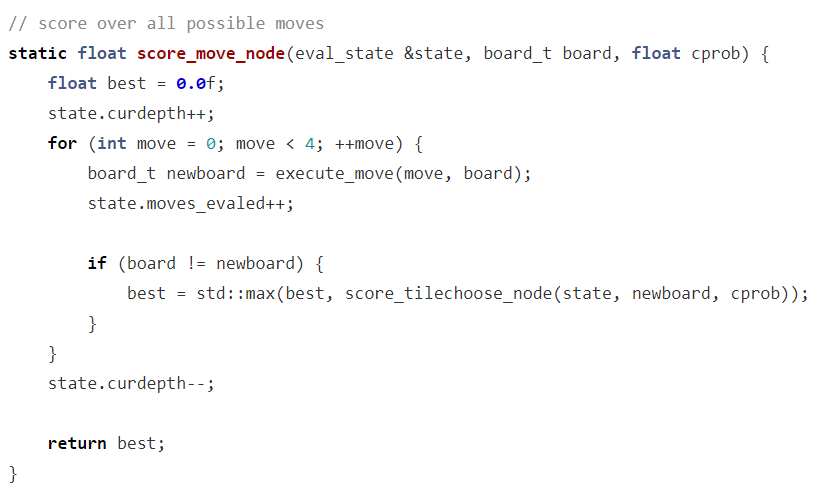
算法设定,每次进行选择时(上下左右四个方向),都要进行一定次数的推演,也就是假设执行在当前游戏状态执行某个移动后到达新的游戏状态,如此往复计算,最终向下推演多少步数(层数)是根据两个条件来判断的,一个是按照当前状态的不同数字个数来给出的,一个是最后探索到的状态其可能达到的概率的值是否满足阈值。
需要注意的是在算法中对游戏的状态其实是分为两种的,一种是移动后到达的游戏状态A,一种是移动后游戏自动生成块后的游戏状态B。我们计算启发值都是根据移动后到达的游戏状态A。
如果移动后到达的游戏状态不满足条件则返回该状态的启发值:

如果当前的移动后状态曾经探索过,并且该状态探索的层数低于现在,那么直接返回保存的值:

因为探索的终止条件是达到一定层数和探索到达的概率小于预设阈值,因为曾经探索过该游戏状态并且层数低于现在那么曾经探索的游戏值一定要比此刻往下探索进行过更多的探索,因此不需要再重新探索直接返回曾经探索后保存的值。
移动后到达的游戏状态后游戏自动生成新数字块,当前移动后的游戏状态的下一层补上新块后游戏状态的返回的期望值作为当前游戏状态的值并进行保存:

生成新块的游戏值为移动(上下左右四个移动)后的最大的游戏返回值。
===================================================
再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(3) —— 游戏AI解法设计篇的更多相关文章
- 跟k8s工作负载Deployments的缘起缘灭
跟k8s工作负载Deployments的缘起缘灭 考点之简单介绍一下什么是Deployments吧? 考点之怎么查看 Deployment 上线状态? 考点之集群中能不能设置多个Deployments ...
- 再探JS数组原生方法—没想到你是这样的数组
最近作死又去做了一遍javascript-puzzlers上的44道变态题,这些题号称"JS语言专业八级"的水准,建议可以去试试,这里我不去解析这44道题了, ...
- 2048游戏分析、讨论与扩展 - Part I - 游戏分析与讨论
2048这个游戏从刚出開始就风靡整个世界. 本技术博客的目的是想对2048涉及到相关的全部问题进行仔细的分析与讨论,得到一些大家能够接受而且理解的结果. 在这基础上,扩展2048的游戏性,使其变得更好 ...
- Android 带你玩转实现游戏2048 其实2048只是个普通的控件(转)
1.概述 博主本想踏入游戏开放行业,无奈水太深,不会游泳:于是乎,只能继续开发应用,但是原生Android也能开发游戏么,2048.像素鸟.别踩什么来着:今天给大家带来一篇2048的开发篇,别怕不分上 ...
- Android 带你玩转实现游戏2048 其实2048只是个普通的控件
转载请标明出处:http://blog.csdn.net/lmj623565791/article/details/40020137,本文出自:[张鸿洋的博客] 1.概述 博主本想踏入游戏开放行业,无 ...
- 制作 2D 素材|基于 AI 5 天创建一个农场游戏,第 4 天
欢迎使用 AI 进行游戏开发! 在本系列中,我们将使用 AI 工具在 5 天内创建一个功能完备的农场游戏.到本系列结束时,您将了解到如何将多种 AI 工具整合到游戏开发流程中.本系列文章将向您展示如何 ...
- ChatGPT 设计游戏剧情 | 基于 AI 5 天创建一个农场游戏,完结篇!
欢迎使用 AI 进行游戏开发! 在本系列中,我们将使用 AI 工具在 5 天内创建一个功能完备的农场游戏.到本系列结束时,您将了解到如何将多种 AI 工具整合到游戏开发流程中.本文将向您展示如何将 A ...
- 【再探backbone 02】集合-Collection
前言 昨天我们一起学习了backbone的model,我个人对backbone的熟悉程度提高了,但是也发现一个严重的问题!!! 我平时压根没有用到model这块的东西,事实上我只用到了view,所以昨 ...
- 再探jQuery
再探jQuery 前言:在使用jQuery的时候发现一些知识点记得并不牢固,因此希望通过总结知识点加深对jQuery的应用,也希望和各位博友共同分享. jQuery是一个JavaScript库,它极大 ...
- [老老实实学WCF] 第五篇 再探通信--ClientBase
老老实实学WCF 第五篇 再探通信--ClientBase 在上一篇中,我们抛开了服务引用和元数据交换,在客户端中手动添加了元数据代码,并利用通道工厂ChannelFactory<>类创 ...
随机推荐
- Java中创建对象的5种方式总结
引言 作为Java开发人员,我们每天都会代码中创建对象,但我们通常使用依赖管理系统,比如Spring框架,然后,这里有很多种创建对象的方式,本文就对Java创建对象的几种方式进行总结 五种创建方式 创 ...
- 前端模拟接口工具推荐—Apifox(mock数据)
参考文章:https://blog.csdn.net/m0_67403272/article/details/123376945 高级mock部分 1.通过设置期望值,选择类型,比对body部分的参数 ...
- OSI七层网络模型和TCP/IP四层模型
OSI七层网络模型 OSI: 开放系统互连参考模型是ISO制定的一个用于计算机或通信系统间互联的标准体系 OSI七层模型功能: 物理层: 七层模型的最底层,主要是物理介质传输媒介(网线或者无线),在不 ...
- 09-CentOS软件包管理
简介 CentOS7使用rpm和yum来管理软件包. CentOS 8附带YUM包管理器v4.0.4版本,该版本现在使用DNF (Dandified YUM)技术作为后端.DNF是新一代的YUM,新的 ...
- LangChain转换链:让数据处理更精准
上篇文章<5分钟了解LangChain的路由链>里主要介绍了路由链,核心类是LLMRouterChain和MultiPromptChain.本文介绍LangChain里的另外1个重要的链: ...
- python重拾第十一天-REDIS缓存数据库
缓存数据库介绍 NoSQL(NoSQL = Not Only SQL ),意即"不仅仅是SQL",泛指非关系型的数据库,随着互联网web2.0网站的兴起,传统的关系数据库在应付we ...
- VulnHub-DC-8渗透流程
DC-8 kali:192.168.157.131 靶机:192.168.157.152 信息收集 SQL注入 Drupal 7是有sql注入漏洞的,这里也能看到?nid=1,那测试一下?nid=1' ...
- SpringBoot集成MQTT
MQTT介绍 MQTT 是基于 Publish/Subscribe(发布/订阅) 模式的物联网通信协议,凭借简单易实现.支持 QoS.报文小等特点. 其具有协议简洁.⼩巧.可扩展性强.省流量.省电等优 ...
- 树莓派4B-Python-控制超声波模块
树莓派4B-Python-控制超声波模块 超声波模块: 超声波模块为常用的HC-SR04型号,有四个引脚,分别为Vcc.Trig(控制端).Echo(接收端).GND,使用起来也比较简单.在树莓派最新 ...
- 解读MySQL 8.0数据字典缓存管理机制
背景介绍 MySQL的数据字典(Data Dictionary,简称DD),用于存储数据库的元数据信息,它在8.0版本中被重新设计和实现,通过将所有DD数据唯一地持久化到InnoDB存储引擎的DD t ...