深入浅出Sqoop之迁移过程源码分析
Sqoop作业执行过程
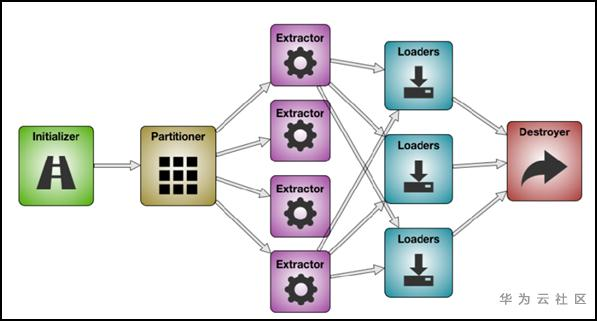
- Initializer:初始化阶段,源数据校验,参数初始化等工作;
- Partitioner:源数据分片,根据作业并发数来决定源数据要切分多少片;
- Extractor:开启extractor线程,根据用户配置从内存中构造数据写入队列;
- Loader:开启loader线程,从队列中读取数据并抛出;
- Destroyer:资源回收,断开sqoop与数据源的连接,并释放资源;
Initializer
public abstract void initialize(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration); public List<String> getJars(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration){ return new LinkedList<String>(); } public abstract Schema getSchema(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration) { return new NullSchema(); }
Destroyer
public abstract void destroy(DestroyerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration);
Partitioner
public abstract List<Partition> getPartitions(PartitionerContext context, LinkConfiguration linkConfiguration, FromJobConfiguration jobConfiguration);
Extractor
while (resultSet.next()) { ... context.getDataWriter().writeArrayRecord(array); ... }
Loader
public abstract void load(LoaderContext context, ConnectionConfiguration connectionConfiguration, JobConfiguration jobConfiguration) throws Exception;
load方法从SqoopOutputFormatDataReader中读取,它读取“中间数据格式表示形式” _中的数据并将其加载到数据源。此外Loader必须迭代的调用DataReader()直到它读完。
while ((array = context.getDataReader().readArrayRecord()) != null) { ... }
MapReduce执行过程
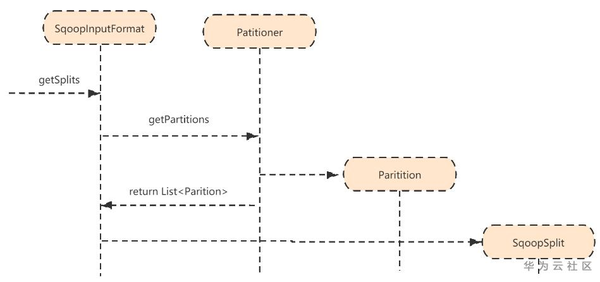
- SqoopInputFormat的getSplits方法会调用Partitioner类的getPartitions方法
- 将返回的Partition列表包装到SqoopSplit中;
- 默认分片个数为10
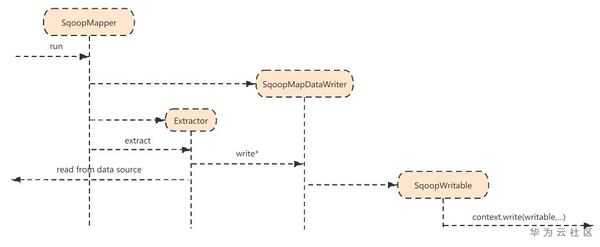
- SqoopMapper包含了一个SqoopMapDataWriter类,
- Mapper的run()调用Extractor.extract方法,该方法迭代的获取源端数据再调用DataWriter写入Context中
private Class SqoopMapDataWriter extends DataWriter { ... private void writeContent() { ... context.wirte(writable, NullWritable.get()); // 这里的writable 是SqoopWritable的一个对象 ... } ... }
- SqoopOutputFormatLoadExecutor包装了SqoopOuputFormatDataReader,SqoopRecordWriter, ConsumerThread三个内部类;
- SqoopNullOutputFormat调用getRecordWriter时创建一个线程:ConsumerThread,代码如下
- ConsumerThread集成了Runnable接口,线程内部调用Loader.load(...)方法,该方法用DataReader迭代的从Context中读取出SqoopWritable,并将其写入一个中间数据格式再写入目的端数据库中。
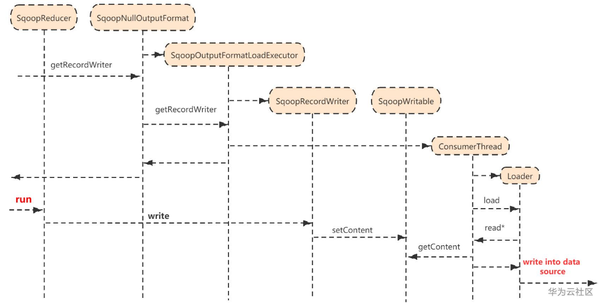
- 再本地模式下,Sqoop提交任务时没有设置SqoopReducer.class,MR会调用一个默认的reducer.class。
- setContent就是SqoopRecordWriter.write(...),它将SqoopWritable反序列化后存入中间存储格式中,即IntermediateDataFormat。与之对应,getContent就是从该中间存储格式中读取数据。
- Sqoop定义了一个可插拔的中间数据格式抽象类,IntermediateDataFormat类,SqoopWritable打包了这个抽象类用来保存中间数据。

深入浅出Sqoop之迁移过程源码分析的更多相关文章
- 大数据之Oozie——源码分析(一)程序入口
工作中发现在oozie中使用sqoop与在shell中直接调度sqoop性能上有很大的差异.为了更深入的探索其中的缘由,开始了oozie的源码分析之路.今天第一天阅读源码,由于没有编译成功,不能运行测 ...
- Sqoop-1.4.6 Merge源码分析与改造使其支持多个merge-key
Sqoop中提供了一个用于合并数据集的工具sqoop-merge.官方文档中的描述可以参考我的另一篇博客Sqoop-1.4.5用户手册. Merge的基本原理是,需要指定新数据集和老数据集的路径,根据 ...
- [Abp vNext 源码分析] - 文章目录
一.简要介绍 ABP vNext 是 ABP 框架作者所发起的新项目,截止目前 (2019 年 2 月 18 日) 已经拥有 1400 多个 Star,最新版本号为 v 0.16.0 ,但还属于预览版 ...
- linux内存源码分析 - 内存压缩(同步关系)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 最近在看内存回收,内存回收在进行同步的一些情况非常复杂,然后就想,不会内存压缩的页面迁移过程中的同步关系也 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- Spring IOC 容器源码分析系列文章导读
1. 简介 Spring 是一个轻量级的企业级应用开发框架,于 2004 年由 Rod Johnson 发布了 1.0 版本.经过十几年的迭代,现在的 Spring 框架已经非常成熟了.Spring ...
- [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本
[阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 目录 [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 0x00 摘要 0x01 背景 1.1 代码进化 1.2 Deep ...
- mongodb 数据块迁移的源码分析
1. 简介 上一篇我们聊到了mongodb数据块的基本概念,和数据块迁移的主要流程,这篇文章我们聊聊源码实现部分. 2. 迁移序列图 数据块迁移的请求是从配置服务器(config server)发给( ...
- JUC源码学习笔记8——ConcurrentHashMap源码分析1 如何实现低粒度锁的插入,如何实现统计元素个数,如何实现并发扩容迁移
源码基于jdk1.8 这一片主要讲述ConcurrentHashMap如何实现低粒度锁的插入,如何实现统计元素个数,如何实现并发扩容迁移 系列文章目录和关于我 一丶ConcurrentHashMap概 ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
随机推荐
- 2020/5/8—cf,我裂开来
呜呜呜我爆零了呜呜呜ljll 嗯T1T2防爆零的没了呜呜呜在此纪念可怜的yjz大佬21发AC 太惨了(逃 先来说说我们都有些啥题目吧... T1 嗯,裂开了,当场裂开我一看!桶排!然后实现,嗯?嗯!嗯 ...
- Rust学习 | Rustlings通关记录与题解
2023年6月19日决定对rust做一个重新的梳理,整理今年4月份做完的rustlings,根据自己的理解来写一份题解,记录在此. 周折很久,因为中途经历了推免的各种麻烦事,以及选择数据库作为未来研究 ...
- Python网页应用开发神器fac 0.2.10版本新功能介绍
fac项目地址:https://github.com/CNFeffery/feffery-antd-components 欢迎star支持 大家好我是费老师,由我开源维护的Python网页通用组件库f ...
- 基于Electron27+Vite4+React18搭建桌面端项目|electron多开窗口实践
前段时间有分享一篇electron25+vite4搭建跨桌面端vue3应用实践.今天带来最新捣鼓的electron27+react18创建跨端程序.electron多开窗体(模拟QQ登录窗口切换主窗口 ...
- JS深入之内存详解,数据结构,存储方式
理解了本文,就知道深拷贝和浅拷贝的底层,了解赋值的底层原理. 可以结合另一篇文章一起食用:深拷贝与浅拷贝的区别,实现深拷贝的方法介绍. 以下是正文: 栈数据结构 栈的结构就是后进先出(LIFO),如果 ...
- sed 原地替换文件时遇到的趣事
哈喽大家好,我是咸鱼 在文章<三剑客之 sed>中咸鱼向大家介绍了文本三剑客中的 sed sed 全名叫 stream editor,流编辑器,用程序的方式来编辑文本 那么今天咸鱼打算讲一 ...
- Welcome to YARP - 4.限流 (Rate Limiting)
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 2.1 - 配置文件(Configuration Files) 2.2 ...
- 你还在为SFTP连接超时而困惑么?
1. 前言 在最近的项目联调过程中,发现在连接上游侧SFTP时总是需要等待大约10s+的时间才会出现密码输入界面,这种长时间的等待直接导致的调用文件接口时连接sftp超时问题.于是决定自己针对该问题进 ...
- 解决 IAR中 Warning[Pa082] 的警告问题
这个警告不属于严重问题 在 IAR (for STM8)的编译中,经常有如下的警告: Warning[Pa082]: undefined behavior: the order of volatile ...
- .NET Conf 2023 将在 11 月 15日-17 日 举行 ,附中文日程表
北京时间 11月15-17日,.NET Conf 2023 即将到来!大会上将发布.NET 8, 以今为止运行最快的.NET 平台, .NET Conf 始终致力于为所有与会者创造世界级的.引人入胜的 ...