深入浅出Sqoop之迁移过程源码分析
Sqoop作业执行过程
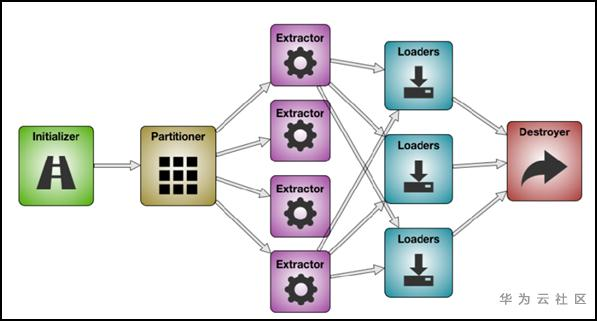
- Initializer:初始化阶段,源数据校验,参数初始化等工作;
- Partitioner:源数据分片,根据作业并发数来决定源数据要切分多少片;
- Extractor:开启extractor线程,根据用户配置从内存中构造数据写入队列;
- Loader:开启loader线程,从队列中读取数据并抛出;
- Destroyer:资源回收,断开sqoop与数据源的连接,并释放资源;
Initializer
public abstract void initialize(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration); public List<String> getJars(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration){ return new LinkedList<String>(); } public abstract Schema getSchema(InitializerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration) { return new NullSchema(); }
Destroyer
public abstract void destroy(DestroyerContext context, LinkConfiguration linkConfiguration,JobConfiguration jobConfiguration);
Partitioner
public abstract List<Partition> getPartitions(PartitionerContext context, LinkConfiguration linkConfiguration, FromJobConfiguration jobConfiguration);
Extractor
while (resultSet.next()) { ... context.getDataWriter().writeArrayRecord(array); ... }
Loader
public abstract void load(LoaderContext context, ConnectionConfiguration connectionConfiguration, JobConfiguration jobConfiguration) throws Exception;
load方法从SqoopOutputFormatDataReader中读取,它读取“中间数据格式表示形式” _中的数据并将其加载到数据源。此外Loader必须迭代的调用DataReader()直到它读完。
while ((array = context.getDataReader().readArrayRecord()) != null) { ... }
MapReduce执行过程
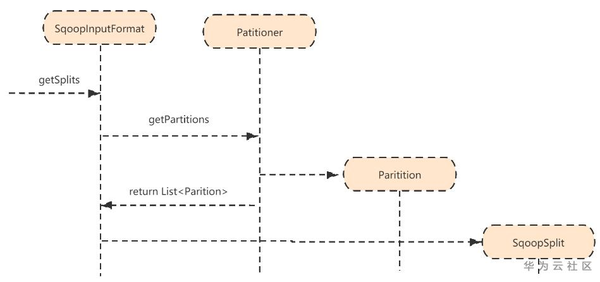
- SqoopInputFormat的getSplits方法会调用Partitioner类的getPartitions方法
- 将返回的Partition列表包装到SqoopSplit中;
- 默认分片个数为10
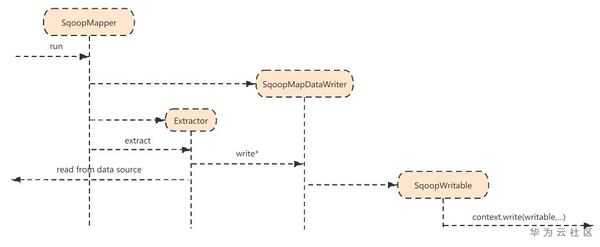
- SqoopMapper包含了一个SqoopMapDataWriter类,
- Mapper的run()调用Extractor.extract方法,该方法迭代的获取源端数据再调用DataWriter写入Context中
private Class SqoopMapDataWriter extends DataWriter { ... private void writeContent() { ... context.wirte(writable, NullWritable.get()); // 这里的writable 是SqoopWritable的一个对象 ... } ... }
- SqoopOutputFormatLoadExecutor包装了SqoopOuputFormatDataReader,SqoopRecordWriter, ConsumerThread三个内部类;
- SqoopNullOutputFormat调用getRecordWriter时创建一个线程:ConsumerThread,代码如下
- ConsumerThread集成了Runnable接口,线程内部调用Loader.load(...)方法,该方法用DataReader迭代的从Context中读取出SqoopWritable,并将其写入一个中间数据格式再写入目的端数据库中。
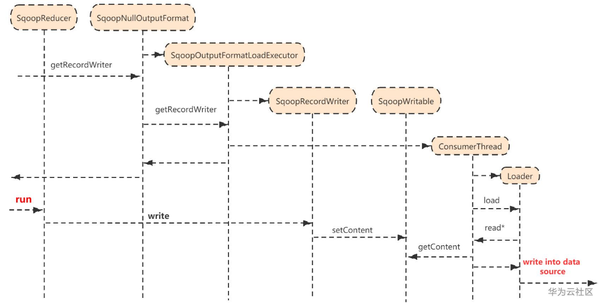
- 再本地模式下,Sqoop提交任务时没有设置SqoopReducer.class,MR会调用一个默认的reducer.class。
- setContent就是SqoopRecordWriter.write(...),它将SqoopWritable反序列化后存入中间存储格式中,即IntermediateDataFormat。与之对应,getContent就是从该中间存储格式中读取数据。
- Sqoop定义了一个可插拔的中间数据格式抽象类,IntermediateDataFormat类,SqoopWritable打包了这个抽象类用来保存中间数据。

深入浅出Sqoop之迁移过程源码分析的更多相关文章
- 大数据之Oozie——源码分析(一)程序入口
工作中发现在oozie中使用sqoop与在shell中直接调度sqoop性能上有很大的差异.为了更深入的探索其中的缘由,开始了oozie的源码分析之路.今天第一天阅读源码,由于没有编译成功,不能运行测 ...
- Sqoop-1.4.6 Merge源码分析与改造使其支持多个merge-key
Sqoop中提供了一个用于合并数据集的工具sqoop-merge.官方文档中的描述可以参考我的另一篇博客Sqoop-1.4.5用户手册. Merge的基本原理是,需要指定新数据集和老数据集的路径,根据 ...
- [Abp vNext 源码分析] - 文章目录
一.简要介绍 ABP vNext 是 ABP 框架作者所发起的新项目,截止目前 (2019 年 2 月 18 日) 已经拥有 1400 多个 Star,最新版本号为 v 0.16.0 ,但还属于预览版 ...
- linux内存源码分析 - 内存压缩(同步关系)
本文为原创,转载请注明:http://www.cnblogs.com/tolimit/ 概述 最近在看内存回收,内存回收在进行同步的一些情况非常复杂,然后就想,不会内存压缩的页面迁移过程中的同步关系也 ...
- 【转】HashMap实现原理及源码分析
哈希表(hash table)也叫散列表,是一种非常重要的数据结构,应用场景极其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,而HashMap的实现原理也常常出 ...
- Spring IOC 容器源码分析系列文章导读
1. 简介 Spring 是一个轻量级的企业级应用开发框架,于 2004 年由 Rod Johnson 发布了 1.0 版本.经过十几年的迭代,现在的 Spring 框架已经非常成熟了.Spring ...
- [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本
[阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 目录 [阿里DIEN] 深度兴趣进化网络源码分析 之 Keras版本 0x00 摘要 0x01 背景 1.1 代码进化 1.2 Deep ...
- mongodb 数据块迁移的源码分析
1. 简介 上一篇我们聊到了mongodb数据块的基本概念,和数据块迁移的主要流程,这篇文章我们聊聊源码实现部分. 2. 迁移序列图 数据块迁移的请求是从配置服务器(config server)发给( ...
- JUC源码学习笔记8——ConcurrentHashMap源码分析1 如何实现低粒度锁的插入,如何实现统计元素个数,如何实现并发扩容迁移
源码基于jdk1.8 这一片主要讲述ConcurrentHashMap如何实现低粒度锁的插入,如何实现统计元素个数,如何实现并发扩容迁移 系列文章目录和关于我 一丶ConcurrentHashMap概 ...
- ABP源码分析一:整体项目结构及目录
ABP是一套非常优秀的web应用程序架构,适合用来搭建集中式架构的web应用程序. 整个Abp的Infrastructure是以Abp这个package为核心模块(core)+15个模块(module ...
随机推荐
- 嵌入式BI的精解与探索
摘要:本文由葡萄城技术团队原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言 1996年,商业智能(BI)的概念首次浮现,随后的20多年间,商 ...
- solidity入门
1. solidity 简介 Solidity(中文名称:Solidity 语言)是一种面向智能合约(Smart Contracts)的高级编程语言,最初由以太坊(Ethereum)的团队开发并用于以 ...
- docker入门加实战—docker常见命令
docker入门加实战-docker常见命令 在介绍命令之前,先用一副图形象的展示一下docker的命令: 常见命令 docker的常见命令和文档地址如下表: 命令 说明 文档地址 docker pu ...
- Sentinel源码改造,实现Nacos双向通信!
Sentinel Dashboard(控制台)默认情况下,只能将配置规则保存到内存中,这样就会导致 Sentinel Dashboard 重启后配置规则丢失的情况,因此我们需要将规则保存到某种数据源中 ...
- 13. 从零开始编写一个类nginx工具, HTTP中的压缩gzip,deflate,brotli算法
wmproxy wmproxy将用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,后续将实现websocket代理, 内外网穿透等, 会将实现过程分享出来, 感 ...
- DFS洛谷4961(求联通块)
说实话这个题审题把我卡了半天,还是我太菜 直接上代码吧 偷个懒用万能库. #include"bits/stdc++.h" using namespace std; int mp[1 ...
- 向量数据库Chroma极简教程
引子 向量数据库其实最早在传统的人工智能和机器学习场景中就有所应用.在大模型兴起后,由于目前大模型的token数限制,很多开发者倾向于将数据量庞大的知识.新闻.文献.语料等先通过嵌入(embeddin ...
- 创造力的起源《The Origins of Creativity》
接近创造力 创造力是对原创的追求,其动力是人类对于新奇事物的钟爱. 了解创造力需要三个层次的思考. 1.What(如何定义这种现象) 2.Question(发问,他是如何出现的,导致其出现的最初原因是 ...
- ALSA Compress-Offload API
概述 从 ALSA API 的早期开始,它就被定义为支持 PCM,或考虑到了 IEC61937 等固定比特率的载荷.参数和返回值以帧计算是常态,这使得扩展已有的 API 以支持压缩数据流充满挑战. 最 ...
- 华为云WebAssembly代码静态符号执行技术实现新突破
本文分享自华为云社区<华为云WebAssembly代码静态符号执行技术实现新突破,相关论文被软件工程顶会ISSTA2023接收并荣获杰出论文奖>,作者:华为云软件分析Lab . WebAs ...