从Encoder-Decoder模型入手,探索语境偏移解决之道
摘要:在本文中,我们展示了CLAS,一个全神经网络组成,端到端的上下文ASR模型,通过映射所有的上下文短语,来融合上下文信息。在实验评估中,我们发现提出的CLAS模型超过了标准的shallow fusion偏置方法。
本文分享自华为云社区《语境偏移如何解决?专有领域端到端ASR之路(二)》,原文作者: xiaoye0829 。
在这里我们介绍一篇与专有领域的端到端ASR的相关工作《DEEP CONTEXT: END-TO-END CONTEXTUAL SPEECH RECOGNITION》,这篇工作也是来自Google的同一个研究团队。
在ASR中,一个用户说话的内容取决于他所处的上下文,通常这种上下文可以由一系列的n-gram单词所代表。在这篇工作中,我们同样是研究如何在端到端的模型中应用这种上下文信息。这篇文章的核心做法,可以看做是一个contextual的LAS[1]模型,Contextual LAS(CLAS)模型就是在LAS模型的基础上,联合n-gram的embedding进行优化。即在beam search时,将独立训练的n-gram和LAS模型进行shallow fusion。
在本文的工作中,我们考虑在识别过程中动态融入上下文信息。在传统的ASR系统里,融入上下文信息的一个主流做法是使用一个独立训练的在线重打分框架,这个框架可以动态调整一小部分与特定场景上下文相关的n-gram的权重。能够把这个技术拓展到Seq2Seq的ASR模型里是十分重要的。为了实现根据特定任务偏移识别过程的目的,先前也有工作尝试将独立的LM融入到识别过程中,常见的做法是shallow fusion或者cold fusion。在工作[2]里面,shallow fusion的方法被用来构建Contextual LAS,即LAS的输出概率被一个由说话人上下文构建的特殊WFST修改,并获得了效果的提升。
之前的工作使用外部独立训练的LM进行在线重打分,与Seq2Seq模型联合优化的好处相违背。因此,在本文中,我们提出了一个Contextual LAS(CLAS),提供一系列上下文短语(即语境短语)去提升识别效果。我们的方法是首先将每个短语映射成固定维度的词嵌入,然后采用一个attention注意力机制在模型输出预测的每一步去摘要可用的上下文信息。我们的方法可以被看成是流式关键词发现技术[3]的一个泛化,即允许在推理时使用可变数量的上下文短语。我们提出的模型在训练的时候不需要特定的上下文信息,并且也不需要对重打分的权重进行仔细的调整,仍然能融入OOV词汇。
本文接下来将从标准的LAS模型、标准的上下文LAS模型、以及我们提出的修改版LAS这几个部分进行讲解。
LAS模型就是一个Seq2Seq模型,包含编码器和带有注意力机制的解码器,在解码每个词语的时候,注意力机制会动态计算每个输入隐状态的权重,并通过加权线性组合得到当前的注意力向量。这个模型的输入x是语音信号,输出y是graphemes(即英文的character,包含a~z,0~9,<space>, <comma>, <period>, <apostrophe>,<unk>)。
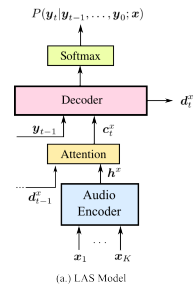
LAS的输出是如下公式:
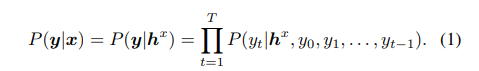
这个公式依赖于encoder的状态向量hx,decoder的隐藏层状态dt,以及建模为上下文向量的Ct, Ct是用一个attention gate去聚合decoder状态和encoder的输出。
在标准的上下文LAS模型中,我们假设已经提前知道了一系列的单词级偏移短语。并把他们编译成了一个WFST。这个单词级的WFST G可以由一个speller FST S组成。S可以把一串graphemes或者word-pieces转换成对应的单词。因此我们可以获得一个上下文语言模型LM C=min(det(SоG))。来自这个上下文语言模型的的分数Pc(y), 之后能被用到解码过程中来增强标准的log概率项。
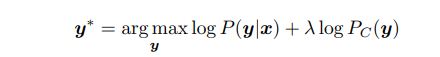
在这里,λ是一个可调整的参数,来控制上下文语言模型对整体模型得分的影响。这个公式中的总的分数,只在单词(word)层面应用。如下图所示:
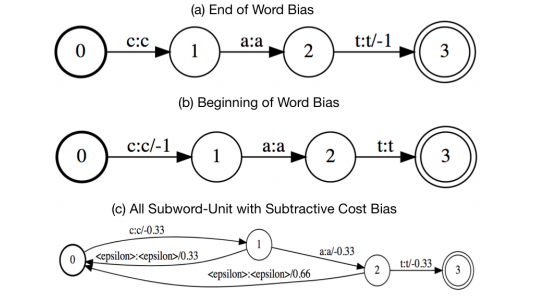
因此,如果相关单词(word)没有在beam中出现,那么这个技术不能提高效果。而且,我们观察到,尽管这个方法在上下文短语数量很少的时候(比如yes,no,cancel),这个方法的效果很好,但是当上下文短语中包含很多名词(比如歌名、联系人)时,这个方法效果不好。因此,如上图c中所示,我们探索在每一个单词的子词单元上施加权重。为了避免手动设定前缀词(与前缀匹配,但不与整个短语匹配)的权重,我们也包含了一个减法损失(subtractive cost),如上图C中的负权重。
下面我们开始介绍本文提出的上下文 LAS模型,它能够利用一系列偏置短语Z提供的额外上下文信息,来有效地建模P(y|x,z)。Z中的单个元素为与特定上下文语境相关的联系人、歌名等短语。假定这些上下文短语可以被表示成:Z = Z1,Z2 …,ZN。这些偏置短语是用来使模型朝输出特定短语偏置,然而,并不是所有的偏置短语都与当前要处理的语音相关,模型需要去决定哪些短语可能相关,并用这些短语去修改模型的目标输出分布。我们利用了一个bias-encoder(偏置编码器)去增强LAS,并把这些短语编码成hz={h0z,h1z,…, hNz}。我们用上标z来区分声音相关的向量。hiz是Zi的映射向量。由于所有的偏置短语可能都与当前的语音无关,我们额外包含了一个可学习的向量,h0z = hnbz,这个向量对应不使用偏置,即在输出时不使用任何偏置短语。这个选项使得模型能够忽略所有的偏置短语。这个偏置编码器是由一个多层的LSTM网络组成,hiz是将Zi中子词对应的embedding序列送到偏置编码器中,并用LSTM的最后状态作为整个短语的输出特征。我们然后用一个额外的attention去对hz进行计算,利用下面的公式,在输入到decoder中时,Ct = [Ctx;Ctz]。其他部分都与传统的LAS模型一样。
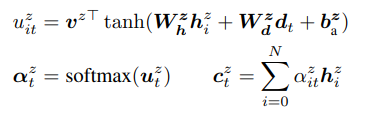
值得注意的是,上面的公式明确建模了在给定语音和之前的输出时,当前时刻看到每个特定短语的概率。
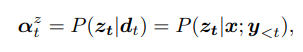
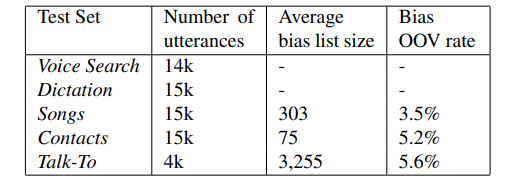
下面我们看下实验部分。实验是在25000小时的英文数据上进行的,这个数据集用一个房间模拟器,添加不同强度的噪声和混淆,手工干扰正常语音,使得信噪比在0到30dB之间,噪声源来自于Youtube和日常生活的噪声环境录音。Encoder的结构包含10层单向的LSTM,每层256个单元。偏置编码器包含单层的LSTM,有512个单元。解码器由4层LSTM组成,每层256个单元。实验的测试集如下:
首先,为了检验我们引入的偏移模块在没有偏移短语的情况下,会不会影响解码。我们对比了我们的CLAS和普通的LAS模型,CLAS模型在训练的时候,使用了随机的偏移短语,但是在测试的时候不提供偏移短语,出乎意料的是,CLAS在没有偏移短语提供时,也获得了比LAS更好的性能。

我们进一步对比了不同的在线重打分的方案,这些方案在如何分配权重给子词单元方面有区别。从下表中可以看到,最好的模型在每个子词单元上进行偏移,有助于在beam中保留单词。下面所有的在线重打分的实验都是在子词单元上进行偏移。
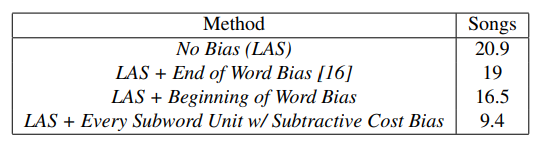
接下来,我们对比了CLAS和上面的各种方案的效果:
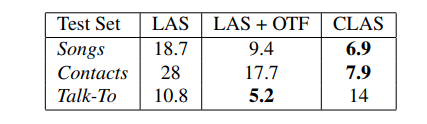
从这个表中可以看到,CLAS显著得超过了传统的方法,并且不需要任何额外的超参数调整。
最后,我们把CLAS和传统的方法结合,可以看到偏置控制和在线重打分都有助于效果提升。
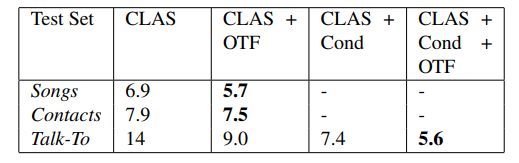
在本文中,我们展示了CLAS,一个全神经网络组成,端到端的上下文ASR模型,通过映射所有的上下文短语,来融合上下文信息。在实验评估中,我们发现提出的CLAS模型超过了标准的shallow fusion偏置方法。
[1] Chan, William, et al. "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition." 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.
[2] Ian Williams, Anjuli Kannan, Petar Aleksic, David Rybach, and Tara N. Sainath, “Contextual speech recognition in end-to-end neural network systems using beam search,” in Proc. of Interspeech, 2018.
[3] Y. He, R. Prabhavalkar, K. Rao, W. Li, A. Bakhtin, and I. McGraw, “Streaming Small-footprint Keyword Spotting Using Sequence-to-Sequence Models,” in Proc. ASRU, 2017.
从Encoder-Decoder模型入手,探索语境偏移解决之道的更多相关文章
- 自定义Encoder/Decoder进行对象传递
转载:http://blog.csdn.net/top_code/article/details/50901623 在上一篇文章中,我们使用Netty4本身自带的ObjectDecoder,Objec ...
- 比sun.misc.Encoder()/Decoder()的base64更高效的mxBase64算法
package com.mxgraph.online; import java.util.Arrays; /** A very fast and memory efficient class to e ...
- Netty自定义Encoder/Decoder进行对象传递
转载:http://blog.csdn.net/top_code/article/details/50901623 在上一篇文章中,我们使用Netty4本身自带的ObjectDecoder,Objec ...
- 探索专有领域的端到端ASR解决之道
摘要:本文从<Shallow-Fusion End-to-End Contextual Biasing>入手,探索解决专有领域的端到端ASR. 本文分享自华为云社区<语境偏移如何解决 ...
- IE/Chrome背景图片居中1px偏移解决方法
最近在支持行业运营的一个推广页面,遇到了非常规的页面banner图居中的问题,为了解决此问题,做了简单的测试,做了一个小结,为经常做大促页面的兄弟姐妹们提供参考解决方案. 首先来看看现象.最经典的页面 ...
- Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation
1.主要完成的任务是能够将英文转译为法文,使用了一个encoder-decoder模型,在encoder的RNN模型中是将序列转化为一个向量.在decoder中是将向量转化为输出序列,使用encode ...
- pytoch之 encoder,decoder
import torch import torch.nn as nn import torch.utils.data as Data import torchvision import matplot ...
- ASP.NET Core MVC/WebAPi 模型绑定探索
前言 相信一直关注我的园友都知道,我写的博文都没有特别枯燥理论性的东西,主要是当每开启一门新的技术之旅时,刚开始就直接去看底层实现原理,第一会感觉索然无味,第二也不明白到底为何要这样做,所以只有当你用 ...
- 并发编程-epoll模型的探索与实践
前言 我们知道nginx的效率非常高,能处理上万级的并发,其之所以高效离不开epoll的支持, epoll是什么呢?,epoll是IO模型中的一种,属于多路复用IO模型; 到这里你应该想到了,sele ...
- ASP.NET Core MVC/WebAPi 模型绑定探索 转载https://www.cnblogs.com/CreateMyself/p/6246977.html
前言 相信一直关注我的园友都知道,我写的博文都没有特别枯燥理论性的东西,主要是当每开启一门新的技术之旅时,刚开始就直接去看底层实现原理,第一会感觉索然无味,第二也不明白到底为何要这样做,所以只有当你用 ...
随机推荐
- 2023平台工程崭露头角,AI 带来新机遇与挑战
在今年,平台工程正在迅速在 IT 企业中崭露头角,成为软件开发团队的必要实践.根据 CloudBees 发布的最新报告<2023年平台工程:快速采纳和影响>,83%的受访者已经完全实施了平 ...
- k8s-服务网格实战-入门Istio
背景 终于进入大家都比较感兴趣的服务网格系列了,在前面已经讲解了: 如何部署应用到 kubernetes 服务之间如何调用 如何通过域名访问我们的服务 如何使用 kubernetes 自带的配置 Co ...
- spring---面向切面(AOP @Pointcut 注解篇)
2.1 第一个实例 接下来,我们先看一个极简的例子:所有的get请求被调用前在控制台输出一句"get请求的advice触发了". 具体实现如下: 1.创建一个AOP切面类,只要在类 ...
- [C++]线段树 区间修改 区间查询
线段树 区间修改 区间查询 请先阅读上一篇Bolg 算法思想 这次要引入一个核心变量: lazy 懒标记 为了达到区间修改的目的 又为了减少运算量 所以就需要引入懒标记这个变量 用来满足 即用即推 没 ...
- source insight 中添加指定类型文件
以下为source insight 3.X版本的设置方法: source insight 中过滤某些格式的文件. 建立source insight工程后,先暂时不要急于添加文件. 打开options- ...
- 小白必知:AIGC 和 ChatGPT 的区别
原文 : https://openaigptguide.com/chatgpt-aigc-difference/ AIGC 和 ChatGPT 都是人工智能技术,但它们的功能和应用场景不同. AIGC ...
- 【Android】Android Bmob后端云配置
简介 开发一个具有网络功能的应用,在Bmob移动应用云存储平台中,只需要注册一个账号,就可以实现申请创建任意多个数据库,获得对应的key,下载对应版本的SDK,并嵌入到移动应用中,调用存取的KPI,进 ...
- 构建满足流批数据质量监控用火山引擎DataLeap
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 面对今日头条.抖音等不同产品线的复杂数据质量场景,火山引擎 DataLeap 数据质量平台如何满足多样的需求?本文 ...
- MongoDB入门级别教程全(Windows版,保姆级教程)
下载mongodb 进入官网: Download MongoDB Community Server | MongoDB 选择msi,Windows版本 下载完后直接双击: 选择complete 这里建 ...
- [洛谷P8867] [NOIP2022] 建造军营
[NOIP2022] 建造军营 题目描述 A 国与 B 国正在激烈交战中,A 国打算在自己的国土上建造一些军营. A 国的国土由 \(n\) 座城市组成,\(m\) 条双向道路连接这些城市,使得任意两 ...