强化学习基础篇[2]:SARSA、Q-learning算法简介、应用举例、优缺点分析
强化学习基础篇[2]:SARSA、Q-learning算法简介、应用举例、优缺点分析
1.SARSA
SARSA(State-Action-Reward-State-Action)是一个学习马尔可夫决策过程策略的算法,通常应用于机器学习和强化学习学习领域中。它由Rummery 和 Niranjan在技术论文“Modified Connectionist Q-Learning(MCQL)” 中介绍了这个算法,并且由Rich Sutton在注脚处提到了SARSA这个别名。
State-Action-Reward-State-Action这个名称清楚地反应了其学习更新函数依赖的5个值,分别是当前状态S1,当前状态选中的动作A1,获得的奖励Reward,S1状态下执行A1后取得的状态S2及S2状态下将会执行的动作A2。我们取这5个值的首字母串起来可以得出一个词SARSA。
1.1基础概念
算法的核心思想可以简化为:
$$
Q(S_{t},A_{t})=Q(S_{t},A_{t})+\alpha[R_{t+1}+\gamma Q(S_{t+1},A_{t+1})-Q(S_{t},A_{t})]
$$
其中 $Q(S_{t+1},A_{t+1})$ 是下一时刻的状态和实际采取的行动对应的 Q 值,$Q(S_{t},A_{t})$ 是当前时刻的状态和实际采取的形同对应的Q值。折扣因子$\gamma$的取值范围是 [ 0 , 1 ],其本质是一个衰减值,如果gamma更接近0,agent趋向于只考虑瞬时奖励值,反之如果更接近1,则agent为延迟奖励赋予更大的权重,更侧重于延迟奖励;奖励值$R_{t+1}$为t+1时刻得到的奖励值。$\alpha$为是学习率。
1.2应用举例
将一个结冰的湖看成是一个4×4的方格,每个格子可以是起始块(S),目标块(G)、冻结块(F)或者危险块(H),目标是通过上下左右的移动,找出能最快从起始块到目标块的最短路径来,同时避免走到危险块上,(走到危险块就意味着游戏结束)为了引入随机性的影响,还可以假设有风吹过,会随机的让你向一个方向漂移。
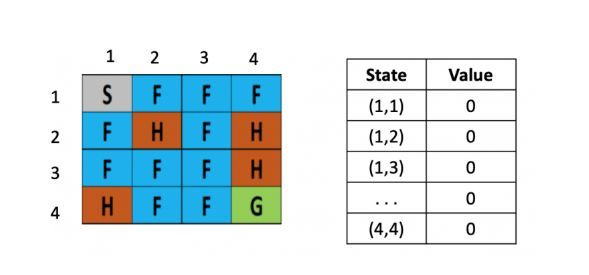
图1: 初始化
左图是每个位置对应的Q value的表,最初都是0,一开始的策略就是随机生成的,假定第一步是向右,那根据上文公式,假定学习率是$\alpha$是 0.1,折现率$\gamma$是0.5,而每走一步,会带来-0.4的奖励,那么(1.2)的Q value就是 0 + 0.1 ×[ -0.4 + 0.5× (0)-0] = -0.04,为了简化问题,此处这里没有假设湖面有风。
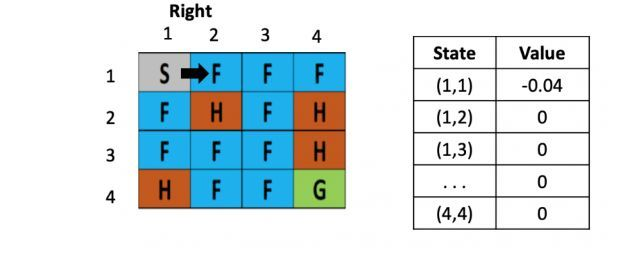
图2: 走一步
假设之后又接着往右走了一步,用类似的方法更新(1,3)的Q value了,得到(1.3)的Q value还为-0.04
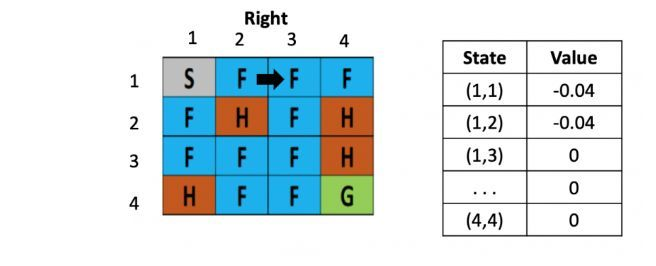
图3: 走一步
等到了下个时刻,骰子告诉我们要往左走,此时就需要更新(1,2)的Q-value,计算式为:V(s) = 0 +0.1× [ -0.4 + 0.5× (-0.04)-0) ]
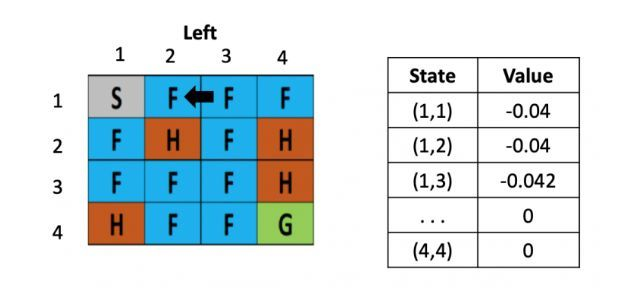
图4: 走一步
从这里,智能体就能学到先向右在向左不是一个好的策略,会浪费时间,依次类推,不断根据之前的状态更新左边的Q table,直到目标达成或游戏结束。
图5: 走一步
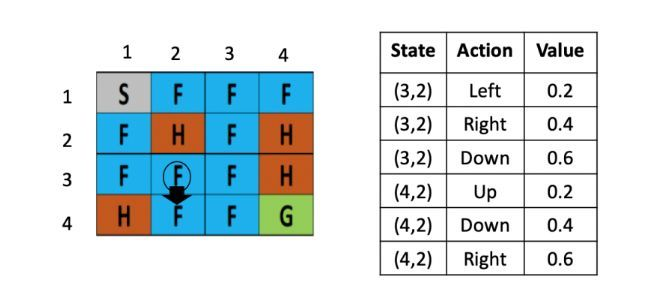
假设现在智能体到达了如图5所示的位置,现在要做的是根据公式,更新(3,2)这里的Q value,由于向下走的Q-value最低,假定学习率是0.1,折现率是0.5,那么(3,2)这个点向下走这个策略的更新后的Q value就是,Sarsa会随机选一个action,比如这里选择的是(Q(4,2),down):
$$ Q( (3,2) down) = Q( (3,2) down ) + 0.1× ( -0.4 + 0.5 × (Q( (4,2) down) )- Q( (3,2), down))$$
$$ Q( (3,2), down) = 0.6 + 0.1× ( -0.4 + 0.5 × 0.4 – 0.6)=0.52 $$
1.3 优缺点
SARSA 算法经常与Q-learning 算法作比较,以便探索出两种算法分别适用的情况。它们互有利弊。
与SARSA相比,Q-learning具有以下优点和缺点:
- Q-learning直接学习最优策略,而SARSA在探索时学会了近乎最优的策略。
- Q-learning具有比SARSA更高的每样本方差,并且可能因此产生收敛问题。当通过Q-learning训练神经网络时,这会成为一个问题。
- SARSA在接近收敛时,允许对探索性的行动进行可能的惩罚,而Q-learning会直接忽略,这使得SARSA算法更加保守。如果存在接近最佳路径的大量负面报酬的风险,Q-learning将倾向于在探索时触发奖励,而SARSA将倾向于避免危险的最佳路径并且仅在探索参数减少时慢慢学会使用它。
如果是在模拟中或在低成本和快速迭代的环境中训练代理,那么由于第一点(直接学习最优策略),Q-learning是一个不错的选择。 如果代理是在线学习,并且注重学习期间获得的奖励,那么SARSA算法更加适用。
2.Q-learning
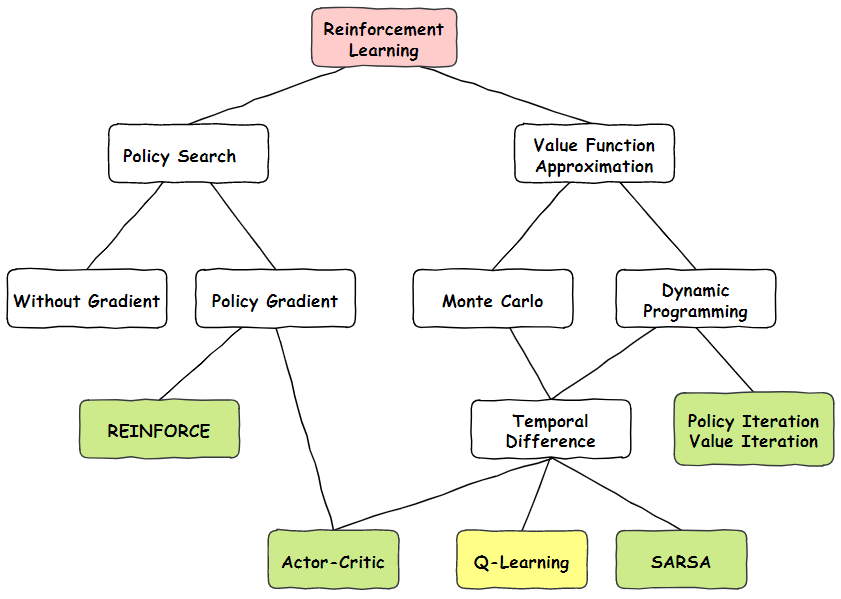
首先我们看一下上图Q-learning在整个强化学习的位置,Q-Learning是属于值函数近似算法中,蒙特卡洛方法和时间差分法相结合的算法。它在1989年被Watkins提出,可以说一出生就给强化学习带来了重要的突破。
Q-Learning假设可能出现的动作a和状态S是有限多,这时a和S的全部组合也是有限多个,并且引入价值量Q表示智能体认为做出某个a时所能够获得的利益。在这种假设下,智能体收到S,应该做出怎样的a,取决于选择哪一个a可以产生最大的Q。下面的表格显示了动物在面对环境的不同状态时做出的a对应着怎样的Q,这里为了简单说明只分别列举了2种S和a:
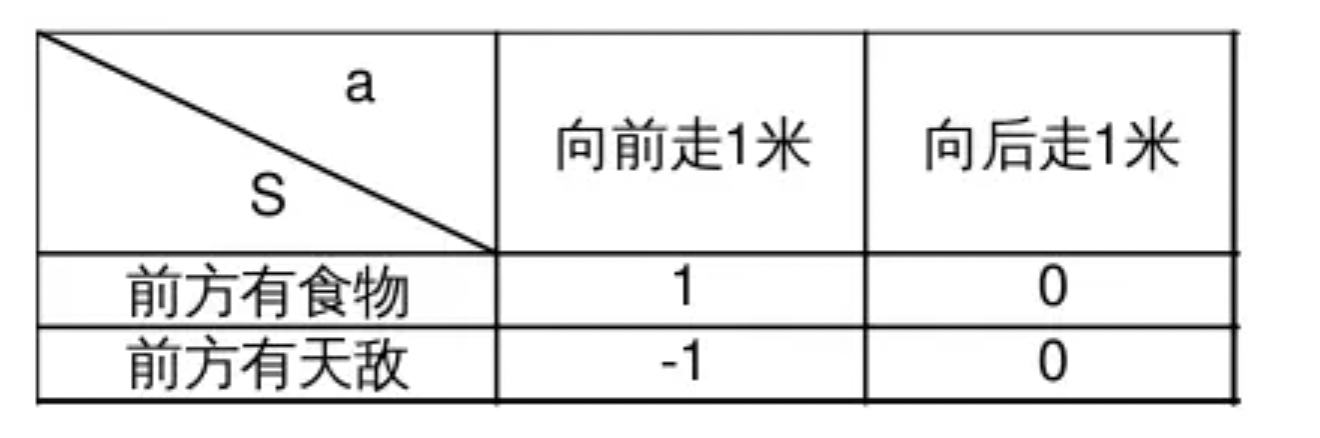
显然,如果此时S="前方有食物",选择a="向前走1米",得到的利益Q="1" 显然比选择a="向后走1米" 的q="0"要大,所以这时应该选择向前走;相对的前方如果有天敌,往前走显然没有任何利益,这时选择最大的利益就要向后走。这种表格在Q-Learning中被称为Q表,表中的S和a需要事先确定,表格主体的数据——q在初始化的时候被随机设置,在后续通过训练得到矫正。
2.1 基础概念
Q-Learning的训练过程是Q表的Q值逐渐调整的过程,其核心是根据已经知道的Q值,当前选择的行动a作用于环境获得的回报R和下一轮$S_{t+1}$对应可以获得的最大利益Q,总共三个量进行加权求和算出新的Q值,来更新Q表:
$$
Q(S_{t},A_{t})=Q(S_{t},A_{t})+\alpha[R_{t+1}+\gamma \mathop{max}{a} Q(S,a)-Q(S_{t},A_{t})]
$$
其中 $Q(S_{t+1}, a)$ 是在 $t+1$ 时刻的状态和采取的行动(并不是实际行动,所以公式采用了所有可能采取行动的Q的最大值)对应的 Q 值,$Q(S_{t},A_{t})$ 是当前时刻的状态和实际采取的形同对应的Q值。折扣因子$\gamma$的取值范围是 [ 0 , 1 ],其本质是一个衰减值,如果gamma更接近0,agent趋向于只考虑瞬时奖励值,反之如果更接近1,则agent为延迟奖励赋予更大的权重,更侧重于延迟奖励;奖励值$R_{t+1}$为t+1时刻得到的奖励值。$\alpha$为是学习率。
这里动作价值Q函数的目标就是逼近最优的$q$ $q=R_{t+1}+\gamma \mathop{max}{a} Q(S,a)$,并且轨迹的行动策略与最终的$q$是无关的。后面中括号的加和式表示的是 $q$的贝尔曼最优方程近似形式。
2.2 应用举例
将一个结冰的湖看成是一个4×4的方格,每个格子可以是起始块(S),目标块(G)、冻结块(F)或者危险块(H),目标是通过上下左右的移动,找出能最快从起始块到目标块的最短路径来,同时避免走到危险块上,(走到危险块就意味着游戏结束)为了引入随机性的影响,还可以假设有风吹过,会随机的让你向一个方向漂移。
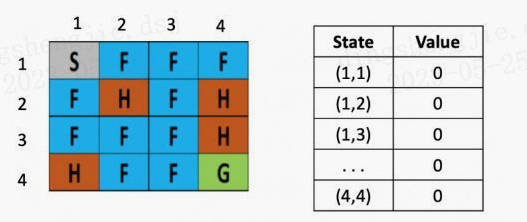
图1: 初始化
左图是每个位置对应的Q value的表,最初都是0,一开始的策略就是随机生成的,假定第一步是向右,那根据上文公式,假定学习率是$\alpha$是 0.1,折现率$\gamma$是0.5,而每走一步,会带来-0.4的奖励,那么(1.2)的Q value就是 0 + 0.1 ×[ -0.4 + 0.5× (0)-0] = -0.04,为了简化问题,此处这里没有假设湖面有风。
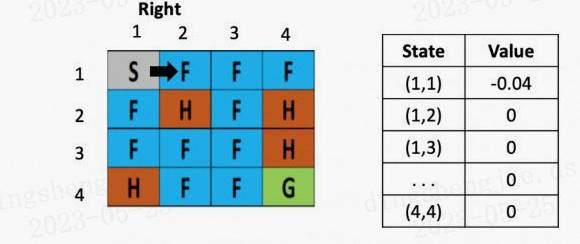
图2: 走一步
假设之后又接着往右走了一步,用类似的方法更新(1,3)的Q value了,得到(1.3)的Q value还为-0.04
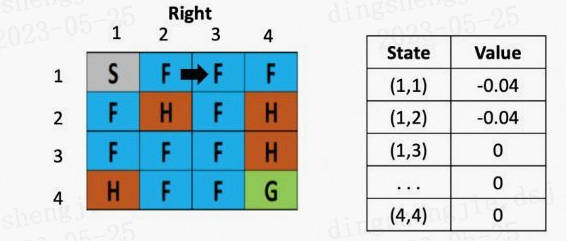
图3: 走一步
等到了下个时刻,骰子告诉我们要往左走,此时就需要更新(1,2)的Q-value,计算式为:V(s) = 0 +0.1× [ -0.4 + 0.5× (-0.04)-0) ]
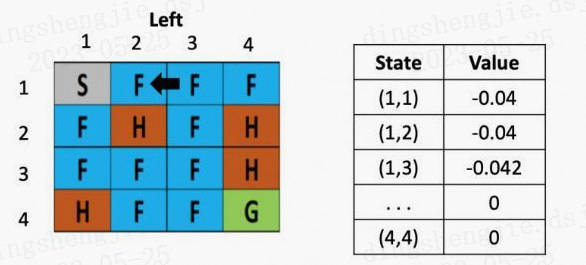
图4: 走一步
从这里,智能体就能学到先向右在向左不是一个好的策略,会浪费时间,依次类推,不断根据之前的状态更新左边的Q table,直到目标达成或游戏结束。
图5: 走一步
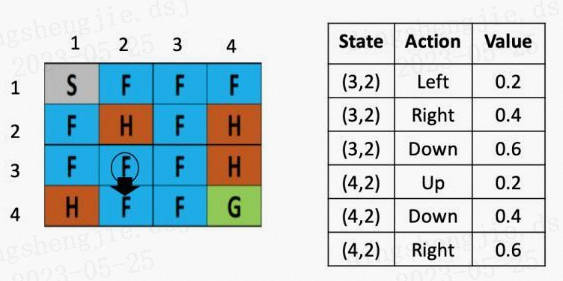
假设现在智能体到达了如图5所示的位置,现在要做的是根据公式,更新(3,2)这里的Q value,由于向下走的Q-value最低,假定学习率是0.1,折现率是0.5,那么(3,2)这个点向下走这个策略的更新后的Q value就是:
$$ Q( (3,2) down) = Q( (3,2) down ) + 0.1× ( -0.4 + 0.5 × max [Q( (4,2) action) ]- Q( (3,2), down))$$
$$ Q( (3,2), down) = 0.6 + 0.1× ( -0.4 + 0.5 × max [0.2, 0.4, 0.6] – 0.6)=0.53 $$
2.3 优缺点
Q-Learning算法有一些缺点,比如状态和动作都假设是离散且有限的,对于复杂的情况处理起来会很麻烦;智能体的决策只依赖当前环境的状态,所以如果状态之间存在时序关联那么学习的效果就不佳。
更多文章请关注公重号:汀丶人工智能

强化学习基础篇[2]:SARSA、Q-learning算法简介、应用举例、优缺点分析的更多相关文章
- 分布式强化学习基础概念(Distributional RL )
分布式强化学习基础概念(Distributional RL) from: https://mtomassoli.github.io/2017/12/08/distributional_rl/ 1. Q ...
- Docker虚拟化实战学习——基础篇(转)
Docker虚拟化实战学习——基础篇 2018年05月26日 02:17:24 北纬34度停留 阅读数:773更多 个人分类: Docker Docker虚拟化实战和企业案例演练 深入剖析虚拟化技 ...
- [转]C++学习–基础篇(书籍推荐及分享)
C++入门 语言技巧,性能优化 底层硬货 STL Boost 设计模式 算法篇 算起来,用C++已经有七八年时间,也有点可以分享的东西: 以下推荐的书籍大多有电子版.对于技术类书籍,电子版并不会带来一 ...
- 强化学习一:Introduction Of Reinforcement Learning
引言: 最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了.也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流. 一.强化学习是什么? ...
- 机器学习&深度学习基础(tensorflow版本实现的算法概述0)
tensorflow集成和实现了各种机器学习基础的算法,可以直接调用. 代码集:https://github.com/ageron/handson-ml 监督学习 1)决策树(Decision Tre ...
- Bat 脚本学习 (基础篇)
[转]Bat 脚本学习 2015-01-05 14:13 115人阅读 评论(0) 收藏 举报 基础部分: ============================================== ...
- ios学习基础篇一
搜集的不错的oc学习资料 大概总结: http://my.oschina.net/luoguankun/blog/208526 详细教程: http://www.w3cschool.cc/ios/io ...
- Laravel学习基础篇之--路由
终于还是决定再多学一门重量级框架,当然首选必备还是被称为最优雅的Web开发框架--Laravel 对于框架的入门,首先了解它的路由规则是先前必备的,以下是laravel 中几种常见的基础路由规则 // ...
- 深度学习基础(一)LeNet_Gradient-Based Learning Applied to Document Recognition
作者:Yann LeCun,Leon Botton, Yoshua Bengio,and Patrick Haffner 这篇论文内容较多,这里只对部分内容进行记录: 以下是对论文原文的翻译: 在传统 ...
- Flume搭建及学习(基础篇)
转载请注明原文出处:http://www.cnblogs.com/lighten/p/6830439.html 1.简介 该文主要是翻译官方的相关文档,源地址点击这里.介绍一下Flume的一些基本知识 ...
随机推荐
- 【django-vue】主页前端搭建 git介绍和安装 git工作流程 git常用命令 git过滤文件 重写drf方法 跨域中间件 导出项目依赖
目录 上节回顾 1 主页前端 Header组件 Banner组件 Footer组件 2 git介绍和安装 git和svn比较 pycharm中配置git svn,git ,github,gitee,g ...
- 拥抱智能,AI 视频编码技术的新探索
随着视频与交互在日常生活中的作用日益突显,愈发多样的视频场景与不断提高的视觉追求对视频编码提出更高的挑战.相较于人们手工设计的多种视频编码技术,AI 编码可以从大数据中自我学习到更广泛的信号内在编码规 ...
- Beyond Compare常用快捷键
[会话]菜单的功能与快捷键 [文件]菜单的功能与快捷键 [编辑]菜单的功能与快捷键 [搜索]菜单的功能与快捷键
- VA21 创建报价单
1.前台 报价是提供给客户交付货物或服务的一份文件,客户想要知道产品价格以及装运时间. 事务代码VA21 输入报价单类型和销售组织.分销渠道.产品组 输入售达方和行项目的物料信息,订购数量等信息 输入 ...
- Java 时间戳和时间相互转换 日期时间和字符串相互转换 日期时间相减差值 日期时间增加指定天数
Java 时间戳和时间相互转换 日期时间和字符串相互转换 日期时间相减差值 日期时间增加指定天数 代码: package com.sux.demo; import java.text.ParseExc ...
- SpringBoot-mybatisplus-@select用法
mybatisplus查询本生已经挺丰富,但有的时候还是想自己写sql语句,怎么写?这时候就需要使用@select来实现,具体用法如下: 1.数据准备 CREATE TABLE XY_DIC_BLOC ...
- lighthouse性能优化分析工具使用
- Threejs实现一个园区
一.实现方案 单独贴代码可能容易混乱,所以这里只讲实现思路,代码放在最后汇总了下. 想要实现一个简单的工业园区.主要包含的内容是一个大楼.左右两片停车位.四条道路以及多个可在道路上随机移动的车辆.遇到 ...
- 解决Xshell/Xftp提示“要继续使用此程序必须应用到最新的更新或者新版本”(临时规避和彻底解决方案)
一.xshell与xftp登录时提示,但是更新却又每次都失败,无法登录 二. 临时规避方案:手动修改日期为1年前,问题解决软件可以打开,但是每次启动都要手动修改,甚是麻烦 三.彻底解决方案,修改xs ...
- Nacos源码 (4) 配置中心
本文阅读nacos-2.0.2的config源码,编写示例,分析推送配置.监听配置的原理. 客户端 创建NacosConfigService对象 Properties properties = new ...