NLP涉及技术原理和应用简单讲解【二】:paddle(分布式训练、AMP自动混合精度训练、模型量化、模型性能分析)
参考链接:
https://www.paddlepaddle.org.cn/tutorials/projectdetail/3949129#anchor-19
1.分布式训练
FleetX 是飞桨分布式训练扩展包,为了可以让用户更快速了解和使用飞桨分布式训练特性,提供了大量分布式训练例子,可以查阅 FleetX/examples at develop · PaddlePaddle/FleetX · GitHub,以下章节的例子都可以在这找到,用户也可以直接将仓库下载到本地直接。
1.1 Collective 训练快速开始¶
本节将采用CV领域非常经典的模型ResNet50为例,介绍如何使用Fleet API(paddle.distributed.fleet)完成Collective训练任务。 数据方面我们采用Paddle内置的flowers数据集,优化器使用Momentum方法。循环迭代多个epoch,每轮打印当前网络具体的损失值和acc值。 具体代码保存在FleetX/examples/resnet下面, 其中包含动态图和静态图两种执行方式。resnet_dygraph.py为动态图模型相关代码,train_fleet_dygraph.py为动态图训练脚本。 resnet_static.py为静态图模型相关代码,而train_fleet_static.py为静态图训练脚本。
1.1 版本要求¶
在编写分布式训练程序之前,用户需要确保已经安装paddlepaddle-2.0.0-rc-cpu或paddlepaddle-2.0.0-rc-gpu及以上版本的飞桨开源框架。
1.2 操作方法¶
与单机单卡的普通模型训练相比,无论静态图还是动态图,Collective训练的代码都只需要补充三个部分代码:
导入分布式训练需要的依赖包。
初始化Fleet环境。
设置分布式训练需要的优化器。
1.2 ParameterServer训练快速开始¶
本节将采用推荐领域非常经典的模型wide_and_deep为例,介绍如何使用Fleet API(paddle.distributed.fleet)完成参数服务器训练任务,本次快速开始的完整示例代码位于 https://github.com/PaddlePaddle/FleetX/tree/develop/examples/wide_and_deep。
2.1 版本要求¶
在编写分布式训练程序之前,用户需要确保已经安装paddlepaddle-2.0.0-rc-cpu或paddlepaddle-2.0.0-rc-gpu及以上版本的飞桨开源框架。
2.2 操作方法¶
参数服务器训练的基本代码主要包括如下几个部分:
导入分布式训练需要的依赖包。
定义分布式模式并初始化分布式训练环境。
加载模型及数据。
定义参数更新策略及优化器。
开始训练。
1.3 ParameterServer训练快速开始¶
本节将采用推荐领域非常经典的模型wide_and_deep为例,介绍如何使用Fleet API(paddle.distributed.fleet)完成参数服务器训练任务,本次快速开始的完整示例代码位于 https://github.com/PaddlePaddle/FleetX/tree/develop/examples/wide_and_deep。
2.1 版本要求¶
在编写分布式训练程序之前,用户需要确保已经安装paddlepaddle-2.0.0-rc-cpu或paddlepaddle-2.0.0-rc-gpu及以上版本的飞桨开源框架。
2.2 操作方法¶
参数服务器训练的基本代码主要包括如下几个部分:
导入分布式训练需要的依赖包。
定义分布式模式并初始化分布式训练环境。
加载模型及数据。
定义参数更新策略及优化器。
开始训练。
1.3 FleetAPI进行分布式训练
FleetAPI 设计说明¶
Fleet是PaddlePaddle分布式训练的高级API。Fleet的命名出自于PaddlePaddle,象征一个舰队中的多只双桨船协同工作。Fleet的设计在易用性和算法可扩展性方面做出了权衡。用户可以很容易从单机版的训练程序,通过添加几行代码切换到分布式训练程序。此外,分布式训练的算法也可以通过Fleet API接口灵活定义。
使用FleetAPI进行分布式训练-API文档-PaddlePaddle深度学习平台
2. 性能调优:自动混合精度训练(AMP)
一般情况下,训练深度学习模型时默认使用的数据类型(dtype)是 float32,每个数据占用 32 位的存储空间。为了节约显存消耗,业界提出了 16 位的数据类型(如 GPU 支持的 float16、bfloat16),每个数据仅需要 16 位的存储空间,比 float32 节省一半的存储空间,并且一些芯片可以在 16 位的数据上获得更快的计算速度,比如按照 NVIDIA 的数据显示,V100 GPU 上 矩阵乘和卷积计算在 float16 的计算速度最大可达 float32 的 8 倍。
考虑到一些算子(OP)对数据精度的要求较高(如 softmax、cross_entropy),仍然需要采用 float32 进行计算;还有一些算子(如conv2d、matmul)对数据精度不敏感,可以采用 float16 / bfloat16 提升计算速度并降低存储空间,飞桨框架提供了自动混合精度(Automatic Mixed Precision,以下简称为AMP)训练的方法,可在模型训练时,自动为算子选择合适的数据计算精度(float32 或 float16 / bfloat16),在保持训练精度(accuracy)不损失的条件下,能够加速训练,可参考2018年百度与NVIDIA联合发表的论文:MIXED PRECISION TRAINING。本文将介绍如何使用飞桨框架实现自动混合精度训练。
动态图 AMP-O1 训练¶
使用 AMP-O1 训练,需要在 float32 训练代码的基础上添加两处逻辑:
逻辑1:使用
paddle.amp.auto_cast创建 AMP 上下文环境,开启自动混合精度策略Level = ‘O1’。在该上下文环境影响范围内,框架会根据预设的黑白名单,自动确定每个 OP 的输入数据类型(float32 或 float16 / bfloat16)。也可以在该 API 中添加自定义黑白名单 OP 列表。逻辑2:使用
paddle.amp.GradScaler控制 loss 缩放比例,规避浮点数下溢问题。在模型训练过程中,框架默认开启动态 loss scaling 机制(use_dynamic_loss_scaling=True),具体介绍见 1.2.2 grad_scaler 策略。
动态图 AMP-O2 训练¶
使用 AMP-O2训练,需要在 float32 训练代码的基础上添加三处逻辑:
O2模式采用了比O1更为激进的策略,除了框架不支持FP16计算的OP,其他全部采用FP16计算,需要在训练前将网络参数从FP32转为FP16,在FP32代码的基础上添加三处逻辑:
逻辑1:在训练前使用
paddle.amp.decorate将网络参数从 float32 转换为 float16。逻辑2:使用
paddle.amp.auto_cast创建 AMP 上下文环境,开启自动混合精度策略Level = ‘O2’。在该上下文环境影响范围内,框架会将所有支持 float16 的 OP 均采用 float16 进行计算(自定义的黑名单除外),其他 OP 采用 float32 进行计算。逻辑3:使用
paddle.amp.GradScaler控制 loss 缩放比例,规避浮点数下溢问题。用法与 AMP-O1 中相同。
比不同模式下训练速度¶
动态图FP32及AMP训练的精度速度对比如下表所示:
| - | float32 | AMP-O1 | AMP-O2 |
|---|---|---|---|
| 训练耗时 | 0.529s | 0.118s | 0.102s |
| loss | 0.6486028 | 0.6486219 | 0.6743 |
从上表统计结果可以看出,相比普通的 float32 训练模式, AMP-O1 模式训练速度提升约为 4.5 倍,AMP-O2 模式训练速度提升约为 5.2 倍。
注:上述实验构建了一个理想化的实验模型,其matmul算子占比较高,所以加速比较明显,实际模型的加速效果与模型特点有关,理论上数值计算如matmul、conv占比较高的模型加速效果更明显。此外,受机器环境影响,上述示例代码的训练耗时统计可能存在差异,该影响主要包括:GPU 利用率、CPU 利用率等,本示例的测试机器配置如下:
| Device | MEM Clocks | SM Clocks | Running with CPU Clocks |
|---|---|---|---|
| Tesla V100 SXM2 16GB | 877 MHz | 1530 MHz | 1000 - 2400 MHz |
3.飞桨模型量化
飞桨模型量化-使用文档-PaddlePaddle深度学习平台
模型量化作为一种常见的模型压缩方法,使用整数替代浮点数进行存储和计算,可以减少模型存储空间、加快推理速度、降低计算内存,助力深度学习应用的落地。
飞桨提供了模型量化全流程解决方案,首先使用PaddleSlim产出量化模型,然后使用Paddle Inference和Paddle Lite部署量化模型。
产出量化模型¶
飞桨模型量化全流程解决方案中,PaddleSlim负责产出量化模型。
PaddleSlim支持三种模型量化方法:动态离线量化方法、静态离线量化方法和量化训练方法。这三种量化方法的特点如下图。
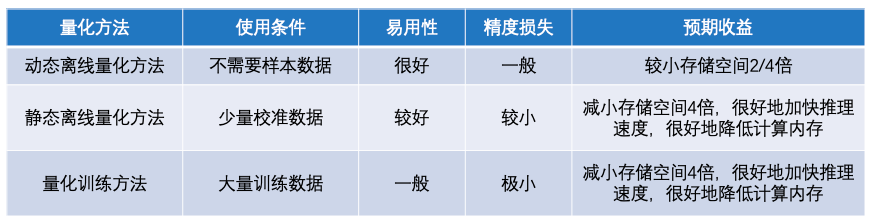
动态离线量化方法不需要使用样本数据,也不会对模型进行训练。在模型产出阶段,动态离线量化方法将模型权重从浮点数量化成整数。在模型部署阶段,将权重从整数反量化成浮点数,使用浮点数运算进行预测推理。这种方式主要减少模型存储空间,对权重读取费时的模型有一定加速作用,对模型精度影响较小。
静态离线量化方法要求有少量无标签样本数据,需要执行模型的前向计算,不会对模型进行训练。在模型产出阶段,静态离线量化方法使用样本数据执行模型的前向计算,同时对量化OP的输入输出进行采样,然后计算量化信息。在模型部署阶段,使用计算好的量化信息对输入进行量化,基于整数运算进行预测推理。静态离线量化方法可以减少模型存储空间、加快模型推理速度、降低计算内存,同时量化模型只存在较小的精度损失。
量化训练方法要求有大量有标签样本数据,需要对模型进行较长时间的训练。在模型产出阶段,量化训练方法使用模拟量化的思想,在模型训练过程中会更新权重,实现拟合、减少量化误差的目的。在模型部署阶段,量化训练方法和静态离线量化方法一致,采用相同的预测推理方式,在存储空间、推理速度、计算内存三方面实现相同的收益。更重要的是,量化训练方法对模型精度只有极小的影响。
飞桨模型量化全流程解决方案中,Paddle Inference负责在服务器端(X86 CPU和Nvidia GPU)部署量化模型,Paddle Lite负责在移动端(ARM CPU)上部署量化模型。
X86 CPU和Nvidia GPU上支持部署PaddleSlim静态离线量化方法和量化训练方法产出的量化模型。 ARM CPU上支持部署PaddleSlim动态离线量化方法、静态离线量化方法和量化训练方法产出的量化模型。
因为动态离线量化方法产出的量化模型主要是为了压缩模型体积,主要应用于移动端部署,所以在X86 CPU和Nvidia GPU上暂不支持这类量化模型。
4.模型性能分析工具:Profiler工具
在模型性能分析中,通常采用如下四个步骤:
获取模型正常运行时的ips(iterations per second, 每秒的迭代次数),给出baseline数据。
开启性能分析器,定位性能瓶颈点。
优化程序,检查优化效果。
获取优化后模型正常运行时的ips,和baseline比较,计算真实的提升幅度。
获取性能调试前模型正常运行的ips¶
上述程序在创建Profiler时候,timer_only设置的值为True,此时将只开启benchmark功能,不开启性能分析器,程序输出模型正常运行时的benchmark信息如下
============================================Perf Summary============================================
Reader Ratio: 53.514%
Time Unit: s, IPS Unit: steps/s
| | avg | max | min |
| reader_cost | 0.01367 | 0.01407 | 0.01310 |
| batch_cost | 0.02555 | 0.02381 | 0.02220 |
| ips | 39.13907 | 45.03588 | 41.99930 |
其中Reader Ratio表示数据读取部分占训练batch迭代过程的时间占比,reader_cost代表数据读取时间,batch_cost代表batch迭代的时间,ips表示每秒能迭代多少次,即跑多少个batch。可以看到,此时的ips为39.1,可将这个值作为优化对比的baseline。
2. 开启性能分析器,定位性能瓶颈点¶
修改程序,将Profiler的timer_only参数设置为False, 此时代表不只开启benchmark功能,还将开启性能分析器,进行详细的性能分析。

析程序发现,这是由于模型本身比较简单,需要的计算量小,再加上Dataloader 准备数据时只用了单进程来读取,使得程序读取数据时和执行计算时没有并行操作,导致Dataloader占比过大。
模型性能分析-使用文档-PaddlePaddle深度学习平台
NLP涉及技术原理和应用简单讲解【二】:paddle(分布式训练、AMP自动混合精度训练、模型量化、模型性能分析)的更多相关文章
- 从原理到场景 系统讲解 PHP 缓存技术
第1章课程介绍 此为PHP相关缓存技术的课堂,有哪些主流的缓存技术可以被使用? 第1章 课程介绍 1-1课程介绍1-2布置缓存的目的1-3合理使用缓存1-4哪些环节适合用缓存 第2章 文件类缓存 2- ...
- Ajax学习总结(1)——Ajax实例讲解与技术原理
摘要:AJAX即"Asynchronous Javascript And XML"(异步JavaScript和XML),是指一种创建交互式网页应用的网页开发技术.AJAX 是一种用 ...
- Ajax 技术原理(转)
Ajax 技术原理 2010-01-04 原文出处:http://www.nowamagic.net/ajax/ajax_AjaxPrinciple.php 在写这篇文章之前,曾经写过一篇关于AJAX ...
- Android插件化技术——原理篇
<Android插件化技术——原理篇> 转载:https://mp.weixin.qq.com/s/Uwr6Rimc7Gpnq4wMFZSAag?utm_source=androi ...
- 大话AI绘画技术原理与算法优化
引子 博主很长一段时间都没有发文,确实是在忙一些技术研究. 如标题所示,本篇博文主要把近段时间的研究工作做一个review. 看过各种相关技术的公关文章,林林总总,水分很多. 也确实没有多少人能把一些 ...
- 新手入门:史上最全Web端即时通讯技术原理详解
前言 有关IM(InstantMessaging)聊天应用(如:微信,QQ).消息推送技术(如:现今移动端APP标配的消息推送模块)等即时通讯应用场景下,大多数都是桌面应用程序或者native应用较为 ...
- Web端即时通讯技术原理详解
前言 有关IM(InstantMessaging)聊天应用(如:微信,QQ).消息推送技术(如:现今移动端APP标配的消息推送模块)等即时通讯应用场景下,大多数都是桌面应用程序或者native应用较为 ...
- 裸眼3D立体显示技术原理详解
众所周知,现实世界是一个三维空间,除去时间这一维度,现实世界是由长度.宽度和高度三个维度组成,我们每天就生活在这个三维世界中,而现有的显示设备大多数都只能显示二维信息,并不能带给人真实的三维感觉.为了 ...
- 快速理解高性能HTTP服务端的负载均衡技术原理(转)
1.前言 在一个典型的高并发.大用户量的Web互联网系统的架构设计中,对HTTP集群的负载均衡设计是作为高性能系统优化环节中必不可少的方案.HTTP负载均衡的本质上是将Web用户流量进行均衡减压,因此 ...
- 一文学会最常见的10种NLP处理技术
一文学会最常见的10种NLP处理技术(附资源&代码) 技术小能手 2017-11-21 11:08:29 浏览2562 评论0 算法 HTTPS 序列 自然语言处理 神经网络 摘要: 自然 ...
随机推荐
- anaconda学习(未完成)
1.Anaconda安装教程(以32.7.4为例)官网地址:https://www.anaconda.com/download(如无法下载可跳转清华源下载)下载完成后点击打开即可安装点击Next选择I ...
- Codeforces Round #679 (Div. 2, based on Technocup 2021 Elimination Round 1) (个人题解)
1434A. Finding Sasuke // Author : RioTian // Time : 20/10/25 #include <bits/stdc++.h> using na ...
- Java | 个人学习指南笔记
前言:由于作者已经有C语言,C++和Python语言的基础了,所以在文章的编写时会以这几门编程语言作对比.本文学习自 C语言中文网的 Java 教程,部分内容引用自这.引用内容仅作学习使用. 第1章: ...
- 云原生 Serverless Database 使用体验
作者 | 李欣 近十年来互联网技术得到了飞速的发展,越来越多的行业加入到了互联网的矩阵,由此带来了更为丰富且复杂的业务场景需求,这对于数据应用系统的性能无疑是巨大的挑战. 关系型数据库 MySQL ...
- kafka集群四、权限增加ACL
系列导航 一.kafka搭建-单机版 二.kafka搭建-集群搭建 三.kafka集群增加密码验证 四.kafka集群权限增加ACL 五.kafka集群__consumer_offsets副本数修改 ...
- vue tabBar导航栏设计实现5-最终版本
系列导航 一.vue tabBar导航栏设计实现1-初步设计 二.vue tabBar导航栏设计实现2-抽取tab-bar 三.vue tabBar导航栏设计实现3-进一步抽取tab-item 四.v ...
- C#使用迭代器显示公交车站点
public static IList<object> items = new List<object>();//定义一个泛型对象,用于存储对象 /// <summary ...
- B2033 A*B 问题
A*B 问题 题目描述 输入两个正整数 \(A\) 和 \(B\),求 \(A \times B\) 的值.注意乘积的范围和数据类型的选择. 输入格式 一行,包含两个正整数 \(A\) 和 \(B\) ...
- 【一文秒懂】Ftrace系统调试工具使用终极指南
[一文秒懂]Ftrace系统调试工具使用终极指南 1.Ftrace是什么 Ftrace是Function Trace的简写,由 Steven Rostedt 开发的,从 2008 年发布的内核 2.6 ...
- java - 局部变量和成员变量的区别
package class_object; /** * 局部变量和成员变量的区别 * * 1. 定义位置 * * 2. 作用域 * * 3. 默认值 => 局部变量没有默认值 * * 4. 内存 ...