墨天轮沙龙 | Proxima 刘方:阿里巴巴大规模向量检索实时服务化引擎 Proxima SE
导读
随着 AI 技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了 AI 技术链路中不可或缺的一环。 在11月16日举办的【墨天轮数据库沙龙-向量数据库专场】邀请到阿里巴巴高级技术专家刘方,为大家带来《阿里巴巴大规模向量检索实时服务化引擎Proxima SE》主题分享,以下为演讲实录。

刘方 阿里巴巴高级技术专家
阿里巴巴达摩院Proxima-SE产品负责人,多年来从事HPC、中间件、数据库、向量检索等底层产品研发工作,对数据服务型产品及技术有广泛积累。
向量检索
1、什么是向量检索
人工智能算法可以对物理世界的人/物/场景所产生各种非结构化数据(如语音、图片、视频,语言文字、行为等)进行抽象,变成多维的向量。这些向量如同数学空间中的坐标,标识着各个实体和实体关系。我们一般将非结构化数据变成向量的过程称为 Embedding,而非结构化检索则是对这些生成的向量进行检索,从而找到相应实体的过程,非结构化检索本质是向量检索技术。
2、基本原理及实现方式
向量检索的基本原理是解决KNN(K-Nearest Neighbor)的问题,但在实际场景下,获取百分之百KNN结果所耗费的计算资源较高,于是引入了求近似解的方法。目前在业内普遍使用ANN(Approximate Nearest Neighbor)来进行大数据量查询,它被证明在实际场景下更有效,更加节省资源。
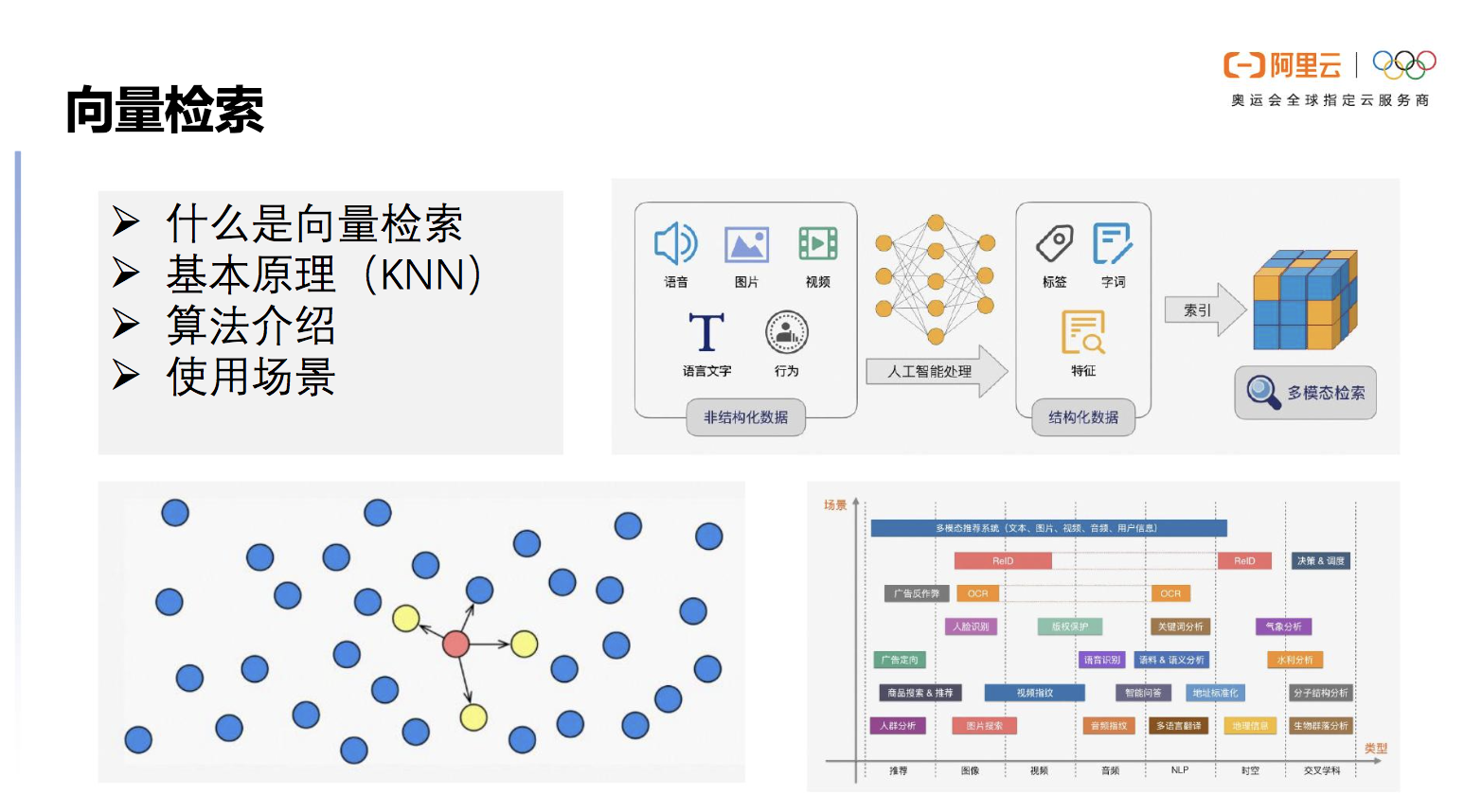
图1 向量检索介绍及场景
如何实现向量检索算法?主要是通过以下几个类别。
首先是哈希方法,通过局部敏感哈希(Locality Sensitive Hashing,LSH)将原始向量通过哈希函数映射到新的向量空间,在新的向量空间中,原始相近的向量会映射到一个桶中,以此实现检索。
其次是基于树的方法,比较典型的有KDTree,原理即选取向量中某个方差最大的维度切分直到切成一个很深的树,以此实现向量检索。
目前流行的是图算法,比如NSG、HNSW、NGT等,以HNSW为例,将快表的思想与NSW的算法相结合,实现层次型小世界图的快速检索,从而达到很好的效果。
PQ(Product quantization直译为乘积量化)也是比较重要的算法,通过乘积量化的方式将高维的向量进行压缩,切分为多个低位向量集合,低位向量会聚类出自己的中心点,反之每一个向量子集的中心点就代表了向量。PQ是压缩完成后再做检索,具有内存较少、效率较高的特点,但是召回率不及非压缩方法。
向量检索的使用场景非常广泛,如人脸识别、推荐系统、图片搜索、视频指纹等。随着 AI 技术的广泛应用,以及数据规模的不断增长,向量检索也逐渐成了 AI 技术链路中不可或缺的一环。
下图展现了向量数据库与传统数据库的区别。

图2 向量数据库vs传统数据库
向量检索内核Proxima
1、Proxima 由来及现状
向量检索内核Proxima 是阿里巴巴达摩院自研的一款向量检索引擎,在2014年随着拍立淘应运而生。Proxima的底库规模有数亿个商品、几十亿个图片,很好的支撑了拍立淘的应用,,为集团带来数十亿个GMV的收益。Proxima还支撑了阿里其他的业务系统,淘宝的主页搜索与推荐也在利用它做内核实现。在双11高峰期,Proxima也能很好利用计算资源并承接高峰流量。
除了阿里的业务系统,Proxima还深度集成在阿里云数据库服务上,为其提供向量检索的能力。
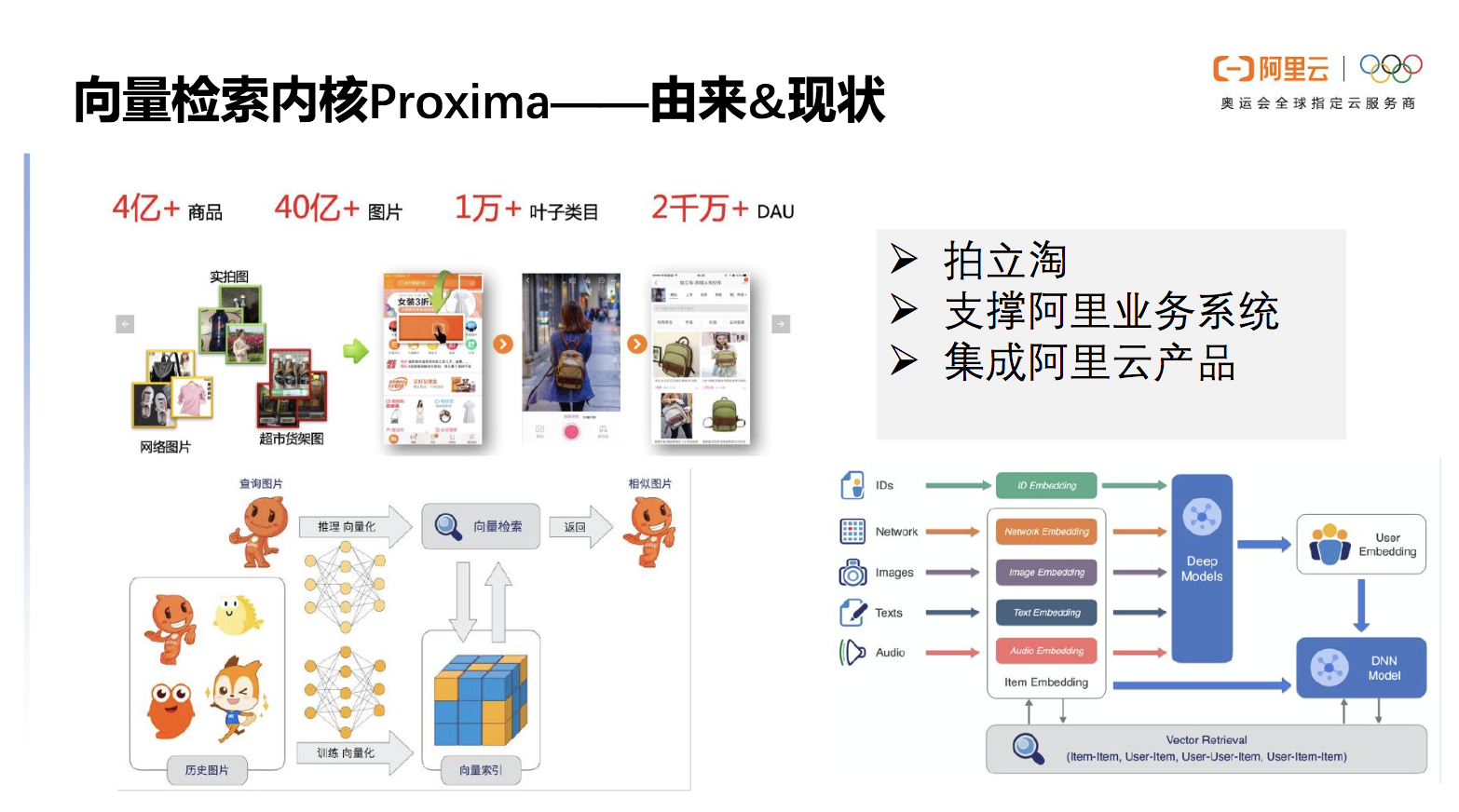
图3 Proxima 为阿里云产品及系统提供向量检索能力
2、Proxima 功能特色
Proxima内核拥有清晰的分层架构,它定义了一套完善抽象的向量检索的接口,不同的索引通过统一的接口投出能力。Proxima底层实现了一套跨平台的抽象以及指令优化的库,在具体的向量计算中发挥很大的优化作用。上层提供不同的向量索引的实现,包括Proxima自研的向量,由此可见这是一套合理科学的结构。
单机大规模是Proxima的一大功能,对内存与磁盘的平衡使用能让单机大规模达到10亿的级别。Proxima极其注重高性能,它将SIMD技术利用到了极致,对磁盘数据结构精细设计使得在构建性能上能达到同类开源库几倍的超越。
Proxima也同样支持异构计算,针对淘宝推荐搜索类似的高吞吐低延迟场景也进行了深度优化,才能以一个较小的计算资源耗费支持创世纪大规模的洪峰考验。流式更新也是Proxima的一大特点,将内存的数据结构映射到磁盘的数据结构,通过内存磁盘的映射工作让Proxima能够从0到1构建大规模索引,以达到实时更新、实时查询、实时落盘。以上都是与开源软件相比,Proxima独特的优势。
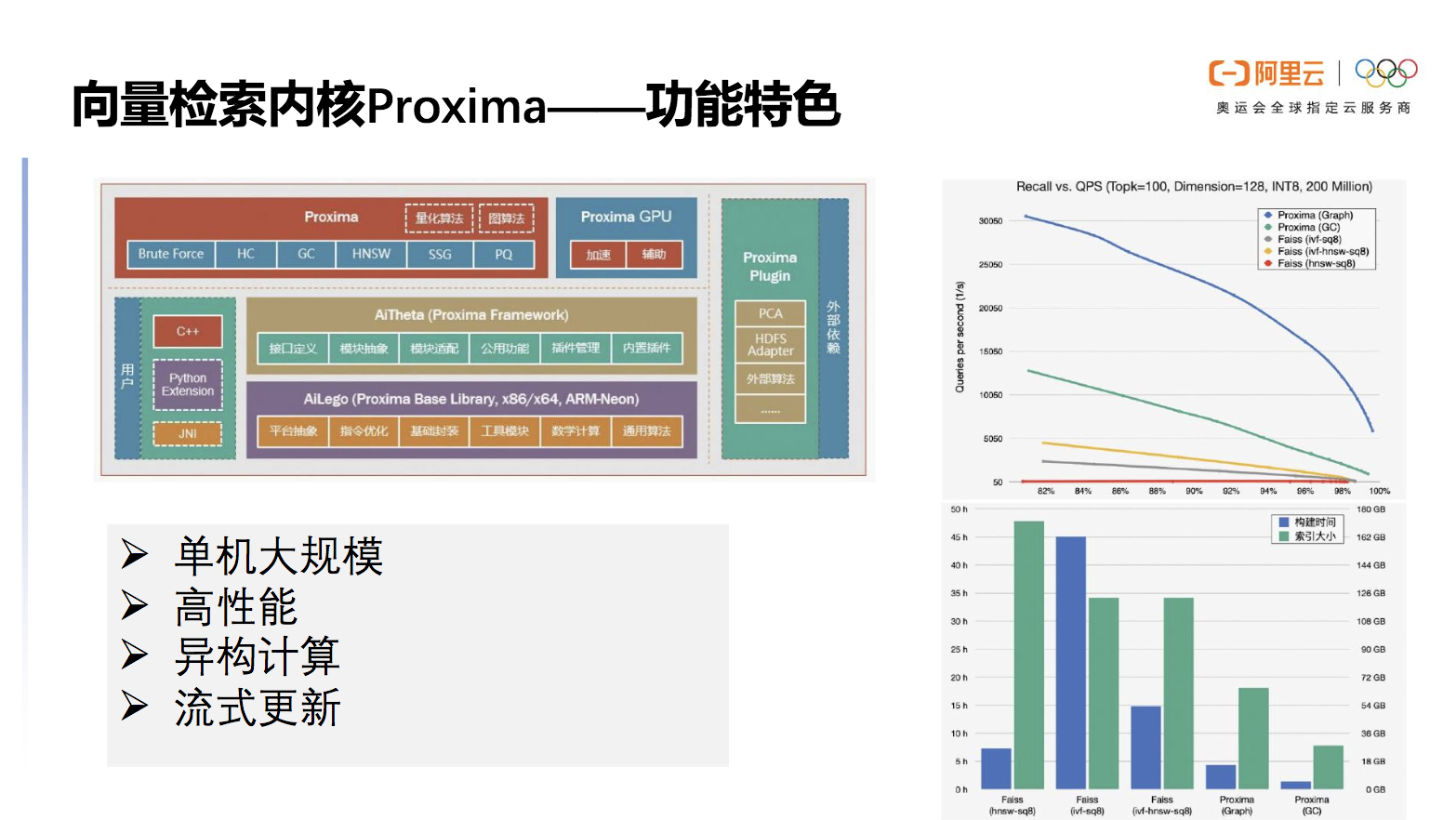
图4 Proxima 具有单机大规模、高性能、异构计算、流式更新等主要功能
服务化引擎-Proxima SE
1、Proxima SE 架构
服务化引擎Proxima SE它将支撑淘宝业务级别的Proxima内核引擎的核心能力逐步提取出来,以开箱即用的方式服务于客户。
下图右侧展示了Proxima SE的软件架构 ,外部接收到非结构化数据后,通过模型推理产生的向量被插入到数据库或者直接写到SE当中,插入到数据库的部分会通过SE的组件将数据同步到SE当中,接受KNN实现Query 查询,并返回Result Set。
图中展现了Proxima SE 的内部架构,collection在向量中对应的是数据库表,segment存储了对应的column,每个column都有自己的存储与实现,比如针对向量索引的存储。
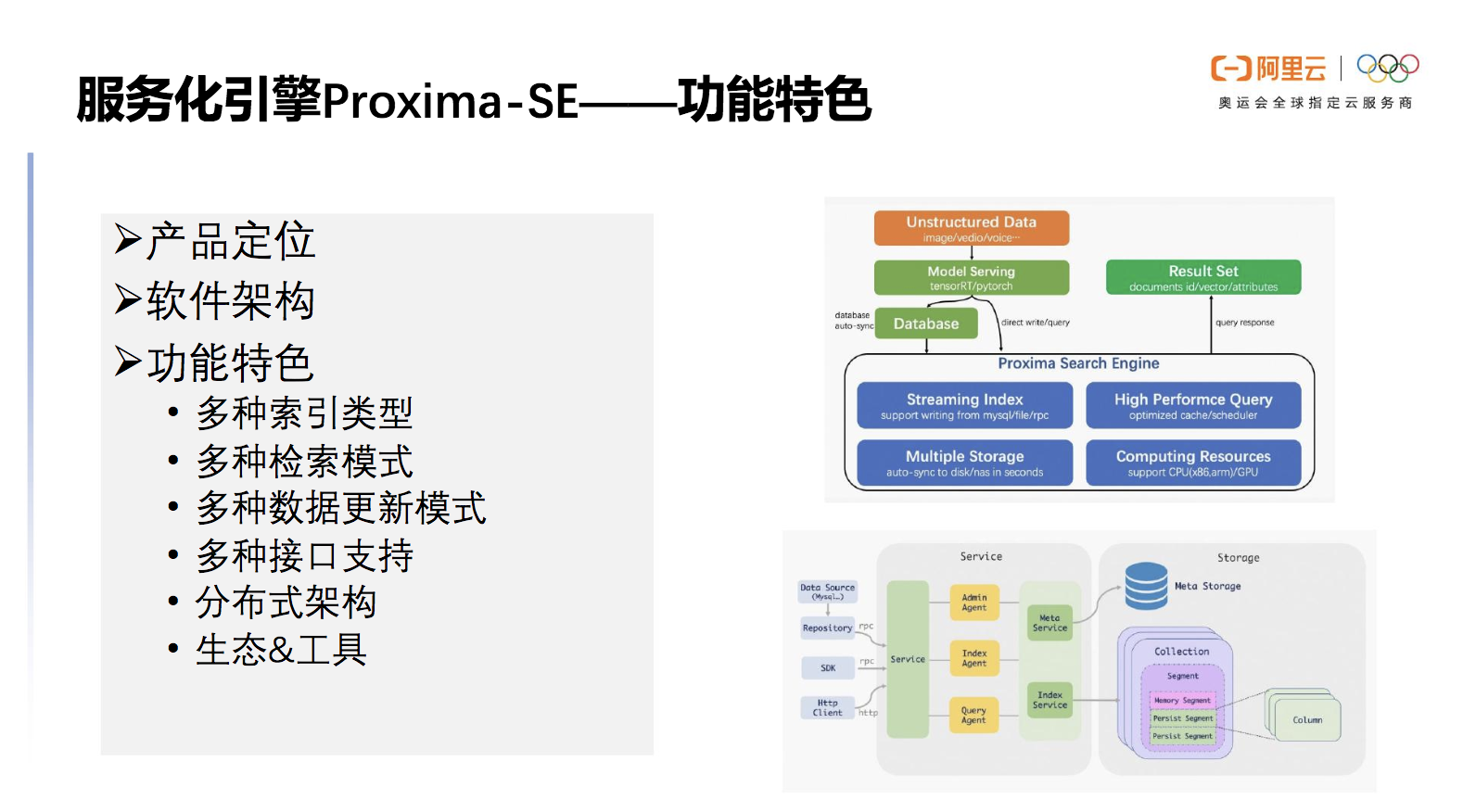
图5 Proxima SE 架构示意图
2、Proxima SE功能特色
多种索引类型
Proxima SE拥有多种索引类型以满足不同场景的需要。首先是向量索引,HNSW是常见也最被广泛使用的图索引类型。OSWG是Proxima团队自研的一种图算法,能够解决HNSW在频繁的update与delete场景下数据膨胀的问题。QC是高性能的量化聚类,存储优势较大但召回率逊色。向量数据类型支持浮点型、整型、Binary,距离计算支持欧式距离、内积距离,通过不同类型搭配可以满足多种场景的具体需求。
倒排索引类似于数据库的二级索引,对整型或者字符串列可以建立倒排索引以加快检索速度。正排索引可以认为是数据库中的普通列,支持各种精度的整型、浮点型以及字符串。由此可见,Proxima SE充分支持多种索引类型。
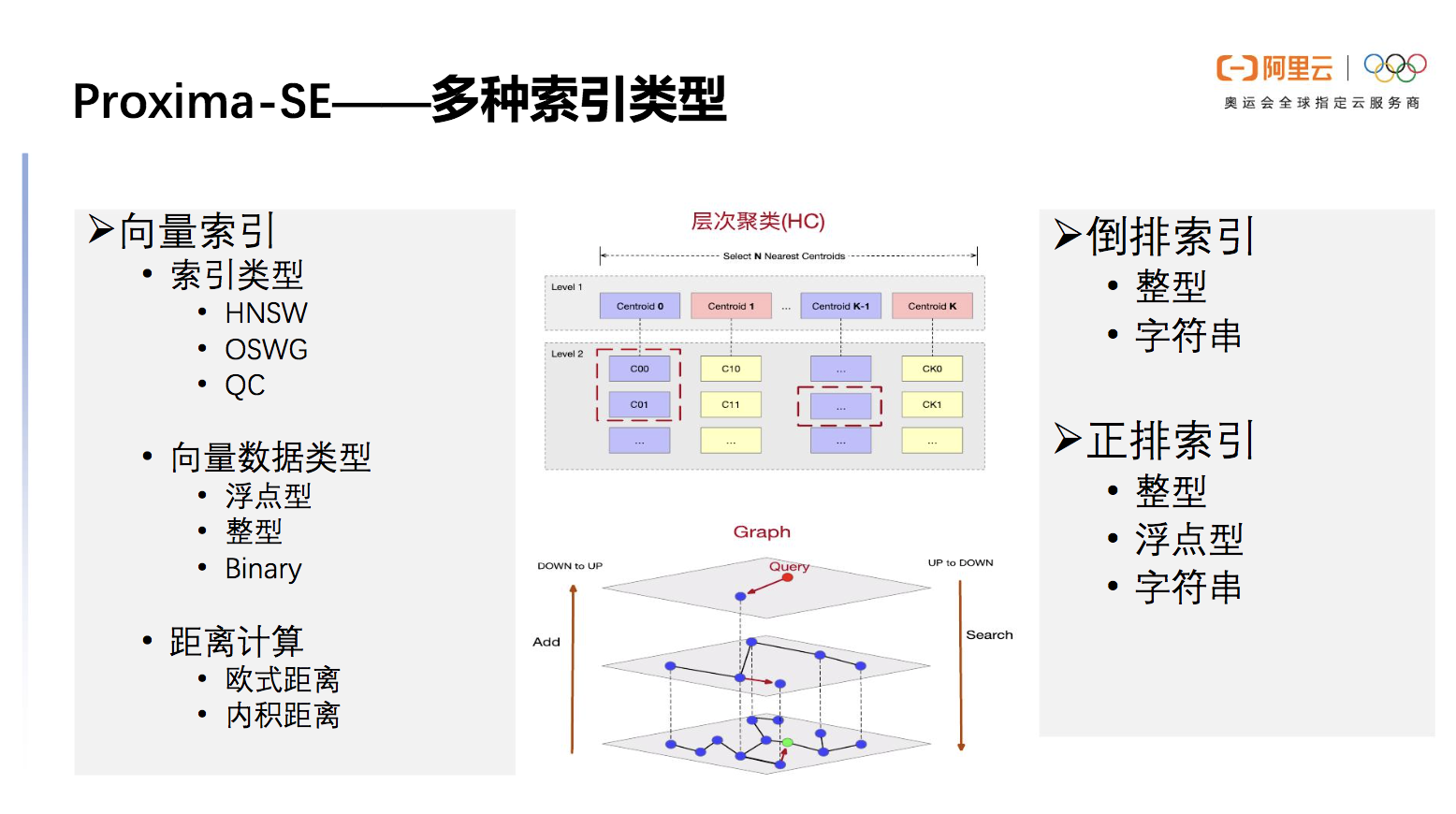
图6 Proxima SE 支持多种类型索引
多种数据更新模式
Proxima SE 的数据更新模式灵活多样,根据不同的场景适配。
旁路同步模式:是将向量数据存储在MySQL数据库中,再通过组件将数据库的向量数据同步在Proxima SE中。
流式直写模式:将Proxima SE当作一个数据库,针对提供的SDK将向量原始数据写到SE当中,在此过程中Proxima SE来保证存储与可靠性。
离线全量模式:如果我们已经有准备好的向量数据,可以通过indexbuilder工具一次性将向量数据构成向量索引,通过Proxima SE 直接拉起进行查询。
批增量模式:主要支持更新模式,考虑到用户场景里可能会周期性地产生一些数据,通过indexbuilder将它构建成一套索引,以追加的方式加载在Proxima SE中再去进行检索。
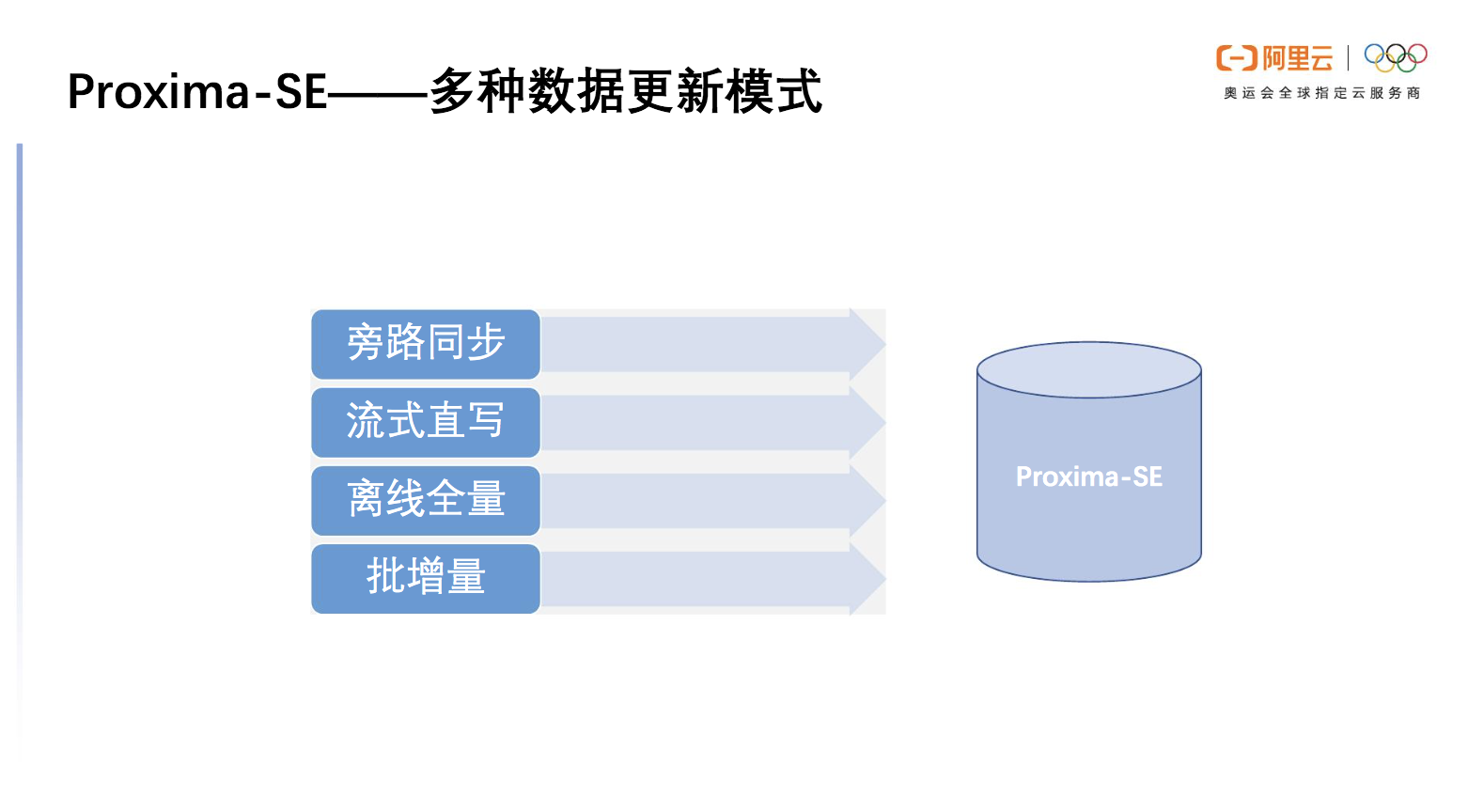
图7 Proxima SE 支持多种数据更新模式
多种检索模式
Proxima SE在检索模式上下了很大功夫。首先Proxima SE在检索中需要指定检索条件,我们支持向量、倒排、正排条件,支持多个条件的AND/OR/()组合也是一大特色,这样就可以构建一个比较复杂的条件满足多样需求。
边检索边过滤是Proxima SE默认的过滤方式,在特殊情况下如果大部分节点不满足过滤条件,就不能满足性能,为此我们设计了检索后置过滤的能力,我们可以先指定一个较大的KNN的top key,再对召回结果集中进行过滤从而筛选出满足条件的结果,由此保证性能。
除此之外,在某些场景下我们根据倒排的条件评估结果集的大概规模,如果这个规模小于某一阈值则可以直接用倒排继续检索,通过暴力计算距离的模式拿到最终的结果。事实证明在倒排暴力检索优化的场景下的性能优势优于向量检索。
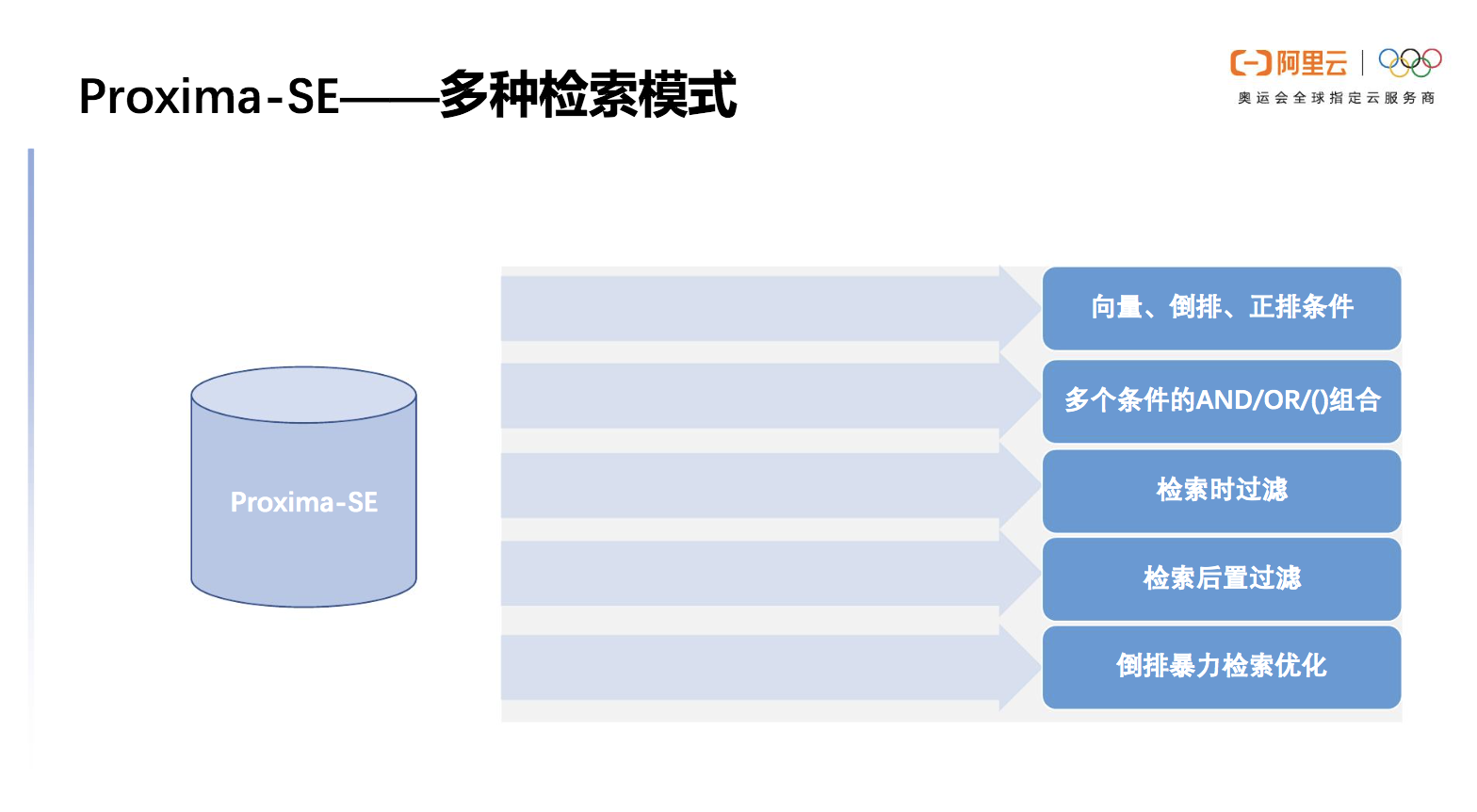
图8 Proxima SE 支持多种检索模式
多种接口支持
Proxima SE在应用型方面也做了很多工作,提供很多的接口支持。首先在调用接口上支持多语言SDK,如python、java等,也可以通过HTTP直接进行访问,快速检索其中的数据。
传输协议支持流行的gRPC以及Restful API的形式。请求数据格式上主要是以JSON为接口,输出不同的query相关属性,为了支持数据库的生态我们也做了SQL集成以方便用户使用。
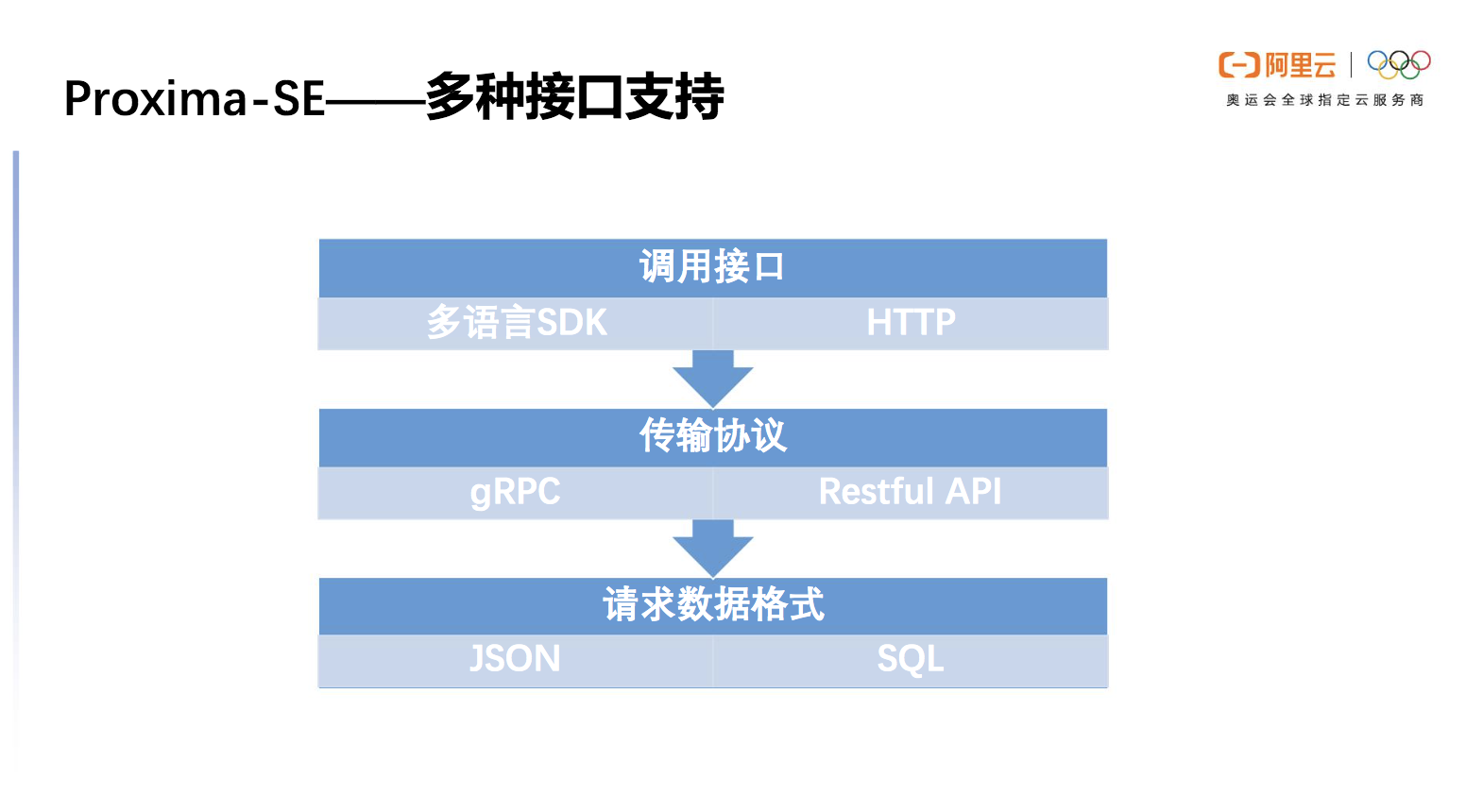
图9 Proxima SE 支持多种接口
分布式架构
Proxima SE的分布式架构支持面向百亿到千亿超大规模向量检索,整体上是收纳性架构,可以部署在K8s中实现自动化部署运维,也可以方便部署在任何一个支持K8s的云环境中。分布式架构的功能与特色如下图所示。
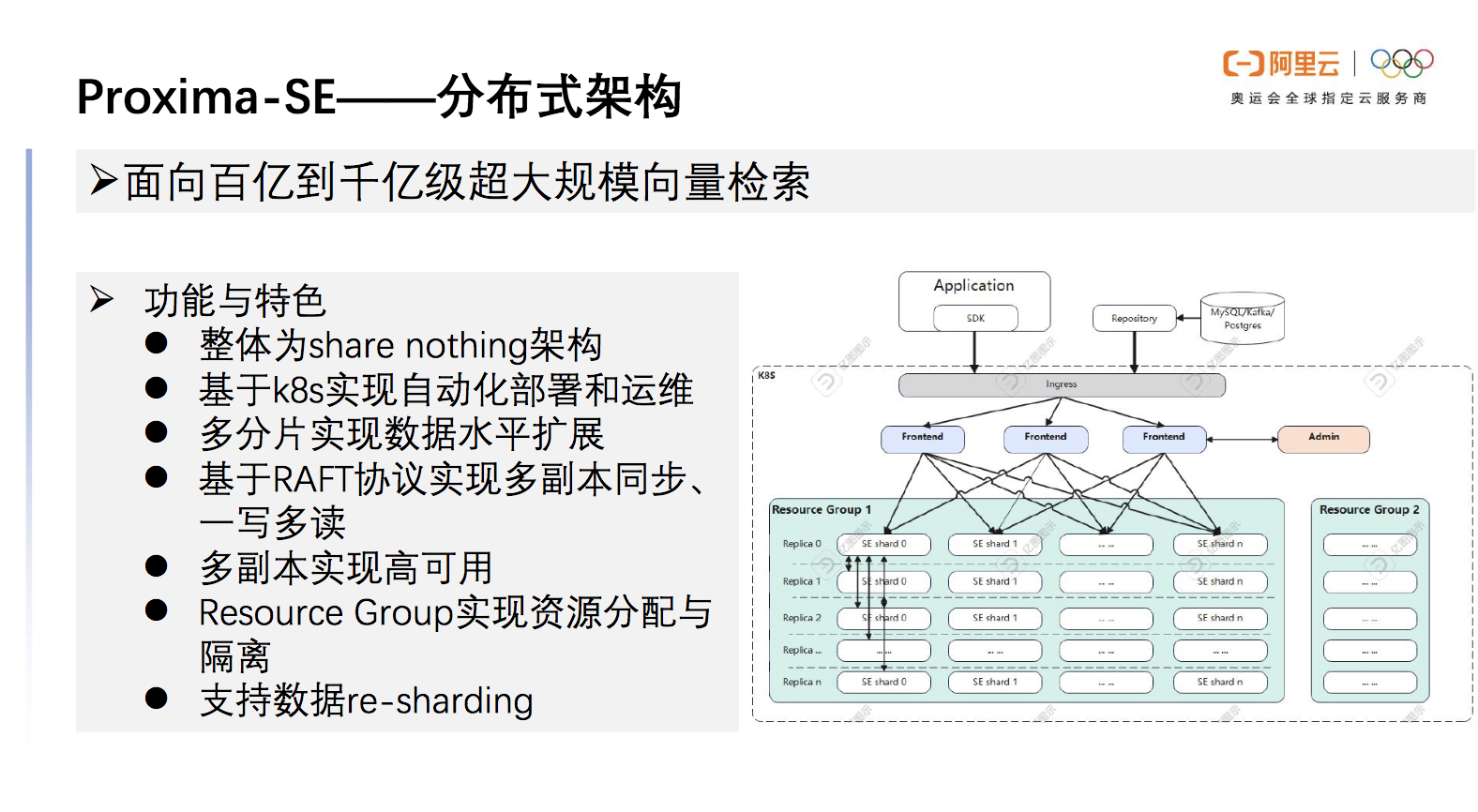
图10 Proxima SE 分布式架构的功能与特色
生态&工具
数据同步组件Repository,可以支持从不同的数据库中同步向量数据,目前支持MySQL、PG以及kafka,未来将支持更多的数据库版本。
监控报警工具有bvar、Prometheus&Grafana,用户可以清晰的看到Proxima SE内部使用及资源占用的情况。除此之外,Proxima SE自带离线构建与批量导入的工具。

图11Proxima SE 支持数据库生态与工具
2、案例分享
Proxima SE 拥有线上线下的多个项目经验,历经时间与业务的打磨,拥有服务外部客户的能力。
线上是以人工智能与机器学习为代表的图搜与地址标准化。图像搜索(Image Search)是一款用于图片间相似性检索的平台型产品。图像搜索以深度学习和机器视觉为核心,提取图片内容特征、建立图像搜索引擎,可广泛应用于拍照购物、商品推荐、版权保护等场景。地址标准化(Address Purification)是一站式闭环地址数据处理和服务平台产品。
图12 Proxima SE 代表使用案例
Proxima SE 已经开放试用,目前提供线上服务PAI-EAS以及软件化版本两种方式,欢迎大家使用体验它的功能特色!我今天的分享就到这里,谢谢大家。
- 线上服务PAI-EAS:https://help.aliyun.com/document_detail/462062.html
- 软件化版本下载方式:https://www.yuque.com/proxima-se/document/user_guide
点击查看本场直播视频回放与PPT资料
视频回放:https://www.modb.pro/video/7522
PPT:https://www.modb.pro/doc/82262
墨天轮技术社区正在举办【有奖问卷|墨天轮2022年数据库大调查】活动,诚邀各位朋友参与!只要以【账号登录状态】提交问卷即可获得奖励,更有机会获得大疆DJI无人机、VIP年卡、电脑支架等奖品。邀请好友填写还可以领取现金奖励!期待大家的参与!
墨天轮沙龙 | Proxima 刘方:阿里巴巴大规模向量检索实时服务化引擎 Proxima SE的更多相关文章
- 阿里巴巴大规模神龙裸金属 Kubernetes 集群运维实践
作者 | 姚捷(喽哥)阿里云容器平台集群管理高级技术专家 本文节选自<不一样的 双11 技术:阿里巴巴经济体云原生实践>一书,点击即可完成下载. 导读:值得阿里巴巴技术人骄傲的是 2019 ...
- 大规模字符串检索-压缩trie树
本文使用压缩trie树实现字符串检索的功能.首先将字符串通过编码转化为二进制串,随后将二进制串插入到trie树中,在插入过程中同时实现压缩的功能. 字符编码采用Huffman,但最终测试发现不采用Hu ...
- 大规模向量相似度计算方法(Google在07年发表的文章)
转载请注明出处:http://www.cnblogs.com/zz-boy/p/3648878.html 更多精彩文章在:http://www.cnblogs.com/zz-boy/ 最近看了Goog ...
- 阿里巴巴下一代云分析型数据库AnalyticDB入选Forrester Wave™ 云数仓评估报告 解读
前言近期, 全球权威IT咨询机构Forrester发布"The Forrester WaveTM: CloudData Warehouse Q4 2018"研究报告,阿里巴巴分析型 ...
- Elasticsearch大规模时序索引如何治理和规划
什么是时序索引? 其主要特点体现在两个方面, 一存,以时间为轴,数据只有增加,没有变更,并且必须包含timestamp(日期时间,名称随意)字段,其作用和意义要大于数据的id字段,常见的数据比如我们通 ...
- 阿里巴巴FastJSON使用实例
1. 什么是fastjson? fastjson是阿里巴巴的开源JSON解析库,它可以解析JSON格式的字符串,支持将Java Bean序列化为JSON字符串,也可以从JSON字符串反序列化到Ja ...
- 阿里巴巴分布式数据库服务DRDS研发历程
淘宝TDDL研发历史和背景 分布式关系型数据库服务(Distribute Relational Database Service,简称DRDS)是一种水平拆分.可平滑扩缩容.读写分离的在线分布式数据库 ...
- (阿里巴巴)数据库连接池——Druid (未完持续更新)
Java程序很大一部分要操作数据库,为了提高性能操作数据库的时候,有不得不使用数据库连接池.数据库连接池有很多选择,c3p.dhcp.proxool等,druid作为一名后起之秀,凭借其出色的性能,也 ...
- 阿里巴巴 Kubernetes 应用管理实践中的经验与教训
作者 | 孙健波(阿里巴巴技术专家).赵钰莹 导读:云原生时代,Kubernetes 的重要性日益凸显.然而,大多数互联网公司在 Kubernetes 上的探索并非想象中顺利,Kubernetes 自 ...
- zz独家专访AI大神贾扬清:我为什么选择加入阿里巴巴?
独家专访AI大神贾扬清:我为什么选择加入阿里巴巴? Natalie.Cai 拥有的都是侥幸,失去的都是人生 关注她 5 人赞同了该文章 本文由 「AI前线」原创,原文链接:独家专访AI大神贾扬清:我 ...
随机推荐
- Snipaste截图工具-测试工程师强推
Snipaste主要功能是截图和贴图,网上下载直接安装即可. 个人认为Snipaste比其它截图好用的点: 快捷键简单.Snipaste只需按F1截图,不会和其它截图工具的快捷键冲突 贴图功能.贴图功 ...
- 15、Spring之基于xml的声明式事务
阅读本文前,建议先阅读Spring之基于注解的声明式事务 15.1.环境搭建 创建名为spring_transaction_xml的新module,过程参考13.1节 15.1.1.配置打包方式和依赖 ...
- 【Layui】05 进度条 Progress
文档地址: https://www.layui.com/doc/element/progress.html 演示案例: <div class="layui-progress" ...
- OSS简单文件上传和本地存储上传
网站的文件上传方法 本地存储上传 // 本地存储方式 MultipartFile接受文件 @PostMapping("/save") public Result save(Stri ...
- 读《Simple statistical gradient-following algorithms for connectionist reinforcement learning》论文 提出Reinforce算法的论文
<Simple statistical gradient-following algorithms for connectionist reinforcement learning>发表于 ...
- Illegal key size or default parameters 解决方案
1.背景 在做aes加密时,报错 Illegal key size or default parameters...有的jdk版本报错,有的不报错,原因在于: jdk 或jre\lib\securit ...
- sublime 快速生成html基础代码
一.快速生成HTML5的头部信息的步骤: 1.Ctrl + N,新建一个文档: 2.Ctrl + Shift + P,打开命令模式,再输入 sshtml 进行模糊匹配,将语法切换到html模式: 3. ...
- [COCI 2023/2024 #3] Slučajna Cesta 题解
前言 期望套期望,很有意思.来一发考场首 A,近 \(\Theta(n)\) 的算法. 题目链接:洛谷. 题意简述 一棵树,每条边随机设有方向.对于所有 \(i\),从 \(i\) 开始随机游走,直到 ...
- QTreeWidget绑定QTabWidget
QTreeWidget绑定QTabWidget 本文仅供本人知识总结使用,所以内容会比较浅显,不喜勿喷. 文章目录 QTreeWidget绑定QTabWidget 一.通过treeWidget路径配合 ...
- 使用 AWS CLI 管理 EC2
EC2 EC2 是 AWS 的云服务器服务 EC2: Elastic Compute Cloud 创建实例 选择一个系统镜像(AMI): AMI(Amazon Machine Image)定义了启动实 ...