360 数科实践:JanusGraph 到 NebulaGraph 迁移
摘要:在本文中 360 数科的周鹏详细讲解了业务从 JanusGraph 迁移到 Nebula Graph 带来的性能提升,在机器资源不到之前 JanusGraph 配置三分之一的情况下,业务性能提升至少 20 倍。

本文作者系 360 数科开发工程师:周鹏
迁移背景
我们之前图数据用的是单机版的 AgensGraph, 后面因为单机带来的性能限制问题,迁移到了分布式数据库 JanusGraph,详细的迁移信息可以看我之前的一篇文章《百亿级图数据JanusGraph迁移之旅》。但是随着数据量和业务调用量的增加,新的问题又出现了——单次查询的耗时很高个别业务场景已经到了 10s,数据量稍微多点,逻辑复杂点的查询耗时也在 2~3s 左右,这严重影响了整个业务流程的性能和相关业务的发展。
JanusGraph 的架构决定了单次耗时高,核心的原因在于它的存储依赖外部,自身不能很好地控制外部存储,我们生产环境用的便是 HBase 集群,这导致所有的查询没法下推到存储层进行处理,只能把数据从 HBase 查询到 JanusGraph Server 内存再做相应的过滤。
举个例子,查询一层关联关系年龄大于 50 岁的用户,如果一层关联有 1,000 人,年龄大于 50 岁的只有 2 个人。介于 JanusGraph 查询请求发送到 HBase 时做不了一层关联顶点属性的过滤,我们不得不通过并发请求去查询 HBase 获取这 1,000 人的顶点属性,再在 JanusGraph Server 的内存做过滤,最后返回给客户端满足条件的 2 个用户。
这样做的问题就是磁盘 IO、网络 IO 浪费很大,而且查询返回的大多数据在而后查的查询并未用到。我们生产环境用的 HBase 为 19 台高配 SSD 服务器的,具体的网络 IO、磁盘 IO 使用情况如下图:
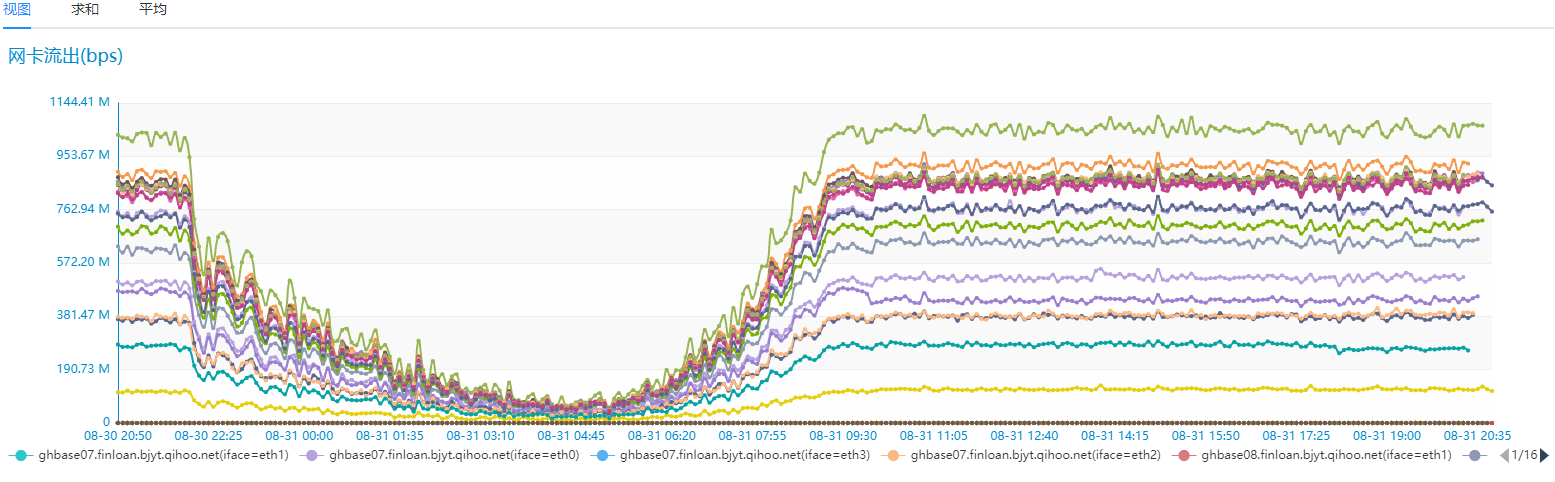
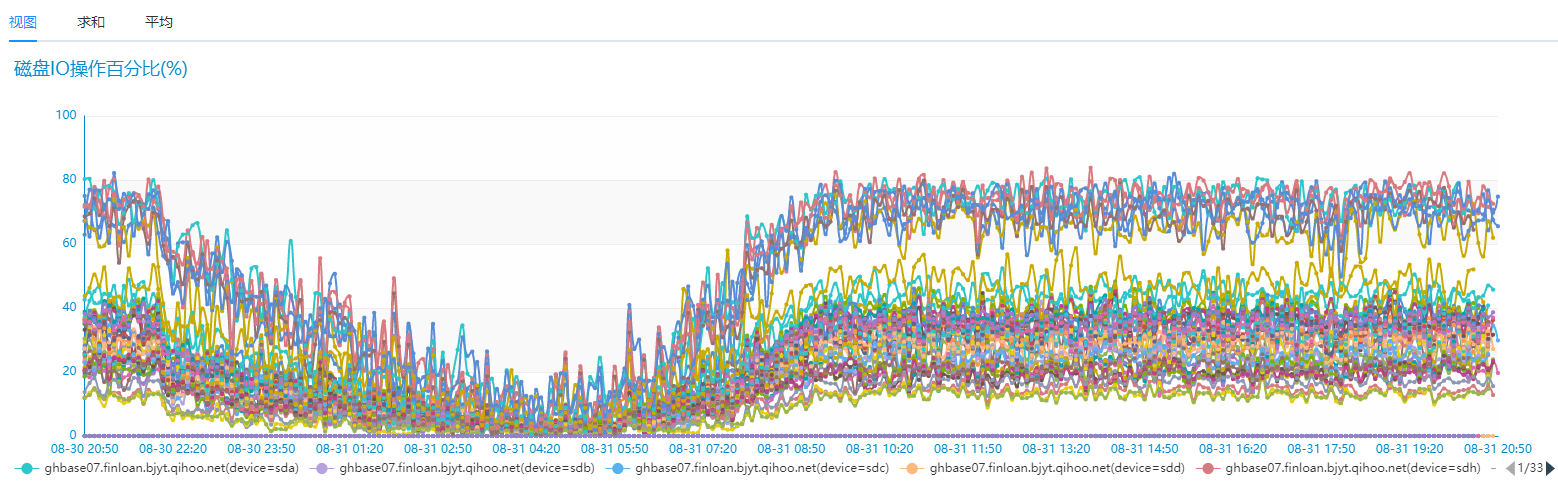
我们对比相同的业务场景,但是只有 6 台相同配置的 SSD 服务器 Nebua Graph 的磁盘 IO 和网络 IO 情况如下:
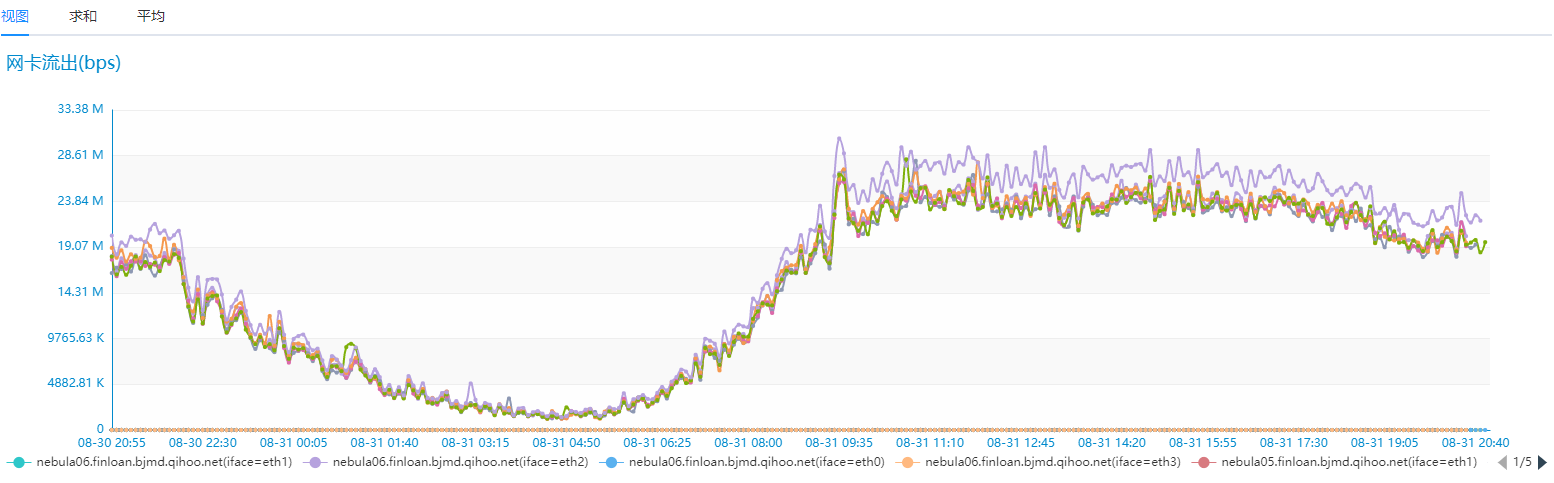
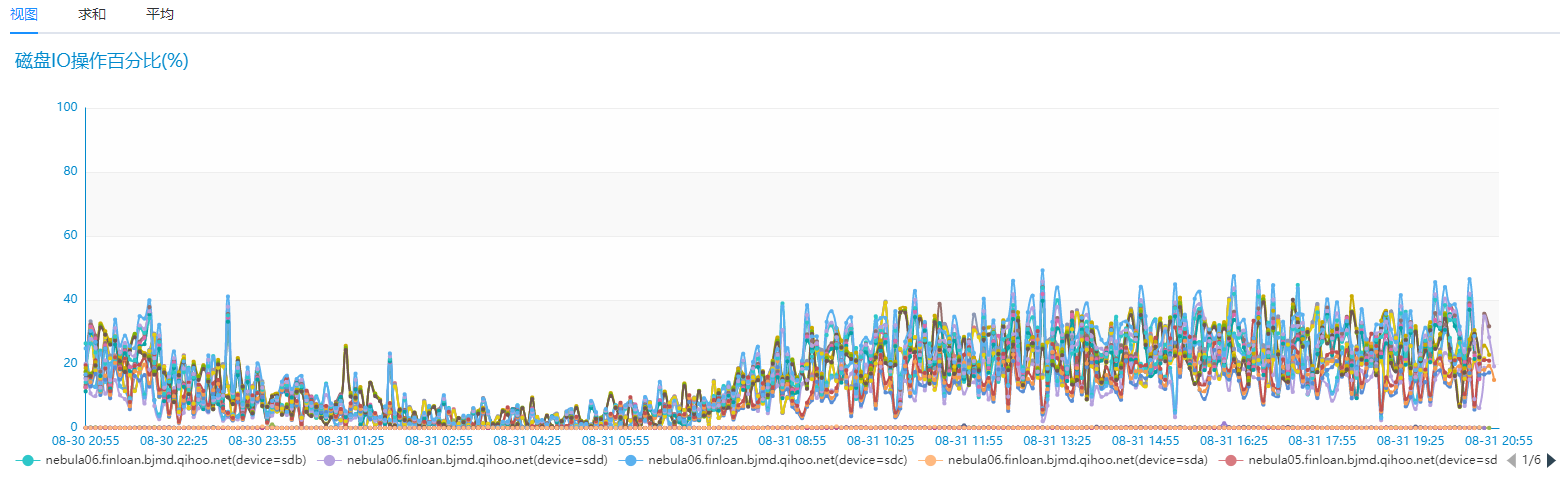
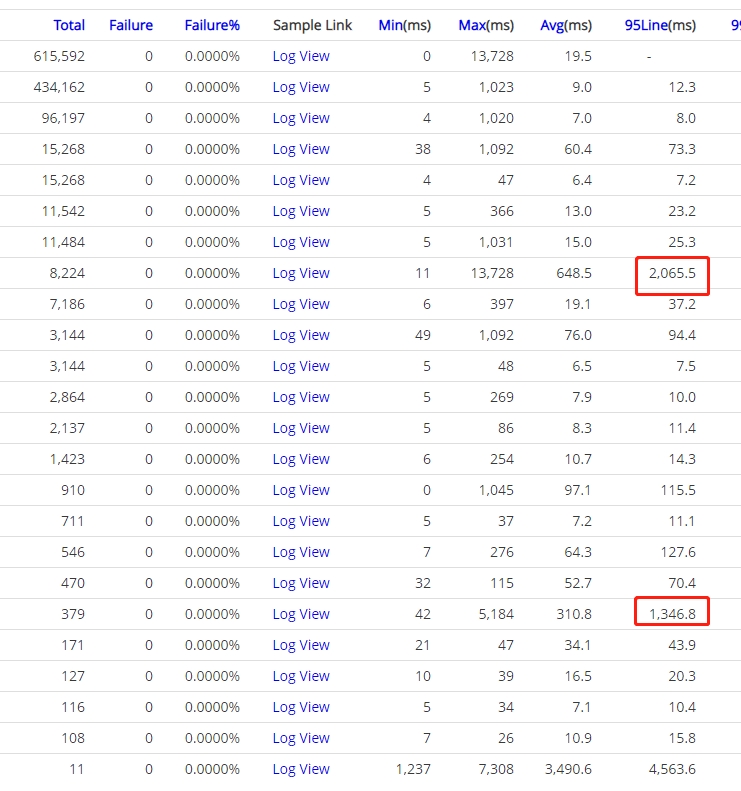
Nebula Graph 性能确实优秀太多,而且是在机器资源只有之前 Hbase 集群 30% 的情况下。我们再来看下业务场景下的耗时情况,之前业务场景中查询耗时需要 2~3s 情况的在 Nebula Graph 这边 100ms 左右返回了,之前需要 10~20s 情况的业务场景现在也基本在 2s 就能返回,并且平均耗时也基本在 500ms 左右就能搞定,性能提升至少 20 倍以上
就冲上面的这些数据,如果你还在用 JanusGraph,就应该立马把这篇文章转发给你的领导,并立个项开始迁移到 Nebua Graph
历史数据迁移
数据迁移这块,因为我们的数据量比较大,20 亿左右的顶点,200 亿左右的边,好在 Nebula Graph 提供 Spark 导入工具——Spark Writer,整个数据导入过程还算比较流畅。这里有个可分享经验,当时使用 Spark 导入工具采用异步方式导入导致了不少 error,稍微改下导入方式换成同步写入就没问题了。另外一个经验是关于 Spark 的,如果导入的数据量比较大,对应的 partitions 需要设置大一点,我们就设置过 8w 个 patitions。如果你设置的 partitions 比较小,单个 partition 的数据量便会比较大,容易导致 Spark 任务 OOM Fail。
查询调优
我们现在生产环境 Nebula Graph 用的是 1.0 的版本,生产环境上 ID 生产我们用的是 hash 函数, uuid 导入数据会很慢,后面官方也不会再支持 uuid。
在我们的生产环境主要参数调优配置如下,主要是 nebula-storage 需要调优
# The default reserved bytes for one batch operation
--rocksdb_batch_size=4096
# The default block cache size used in BlockBasedTable.
# The unit is MB. 我们生产服务器内存为128G
--rocksdb_block_cache=44024
############## rocksdb Options ##############
--rocksdb_disable_wal=true
# rocksdb DBOptions in json, each name and value of option is a string, given as "option_name":"option_value" separated by comma
--rocksdb_db_options={"max_subcompactions":"3","max_background_jobs":"3"}
# rocksdb ColumnFamilyOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_column_family_options={"disable_auto_compactions":"false","write_buffer_size":"67108864","max_write_buffer_number":"4","max_bytes_for_level_base":"268435456"}
# rocksdb BlockBasedTableOptions in json, each name and value of option is string, given as "option_name":"option_value" separated by comma
--rocksdb_block_based_table_options={"block_size":"8192"}
--max_handlers_per_req=10
--heartbeat_interval_secs=10
# 新添加参数
--raft_rpc_timeout_ms=5000
--raft_heartbeat_interval_secs=10
--wal_ttl=14400
--max_batch_size=512
# 参数配置减小内存使用
--enable_partitioned_index_filter=true
--max_edge_returned_per_vertex=10000
Linux 机器的调优主要就是把服务的 swap 关闭掉,开启后会因为磁盘 IO 影响查询性能。另外关于 minor compact 和 major compact 调优,我们生产环境是开启 minor compact 关闭 major compact。关闭 major compact 主要是因为这个操作很占磁盘 IO,并且很难通过线程数(--rocksdb_db_options={"max_subcompactions":"3","max_background_jobs":"3"})控制,后续 Nebula Graph 官方有计划优化这块。
最后,来重点提下 max_edge_returned_per_vertex 这个参数,能想到这个参数 Nebula Graph 不愧是图数据行业的老司机——我们之前的图查询一直受到超级节点的困扰,线上环境如果查询遇到这种关联几百万数据的超级节点能直接把 JanusGraph 的 HBase 集群查崩掉(我们生产环境出现过几次)。之前在查询 JanusGraph 的 Gremlin 语句上加各种 limit 限制都没能很好的解决这个问题,在 Nebula Graph 有了这个 max_edge_returned_per_vertex 参数,数据在最底层存储层直接做了过滤,生产环境就不会再有这种超级节点的困扰,就这一点就应该给 NebulaGraph 一个 FIVE STAR !
本文首发于 Nebula Graph 论坛,阅读本文的你有任何疑问,欢迎前往论坛和作者进行讨论,原帖传送门:https://discuss.nebula-graph.com.cn/t/topic/1172
360 数科实践:JanusGraph 到 NebulaGraph 迁移的更多相关文章
- Qihoo 360 altas 实践
Qihoo 360 altas 实践 简介 Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目.它在MySQL官方推出的MySQL-Prox ...
- Cassandra 在 360 的实践与改进
分享嘉宾:王锋 奇虎360 技术总监 文章整理:王彦 内容来源:Cassandra Meetup 出品平台:DataFunTalk 注:欢迎转载,转载请留言. 导读:2010年,Dropbox 在线云 ...
- Laravel 实践之路: 数据库迁移与数据填充
数据库迁移实际上就是对数据库库表的结构变化做版本控制,之前对数据库库表结构做修改的方式比较原始,比如说对某张库表新增了一个字段,都是直接在库表中执行alter table xxx add .. 的方式 ...
- 数据库实践丨使用MTK迁移Mysql源库后主键自增列导致数据无法插入问题
摘要:用户使用Mogdb 2.0.1版本进行业务上线测试,发现在插入数据时,应用日志中提示primary key冲突,用户自查业务SQL没有问题,接到通知后,招手处理故障. 本文分享自华为云社区< ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- Nebula Graph 的 Ansible 实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow & 看大厂图数据库技术实践 背景 在 Nebula-Graph 的日常测试中,我们会经常在 ...
- PB级大规模Elasticsearch集群运维与调优实践
导语 | 腾讯云Elasticsearch 被广泛应用于日志实时分析.结构化数据分析.全文检索等场景中,本文将以情景植入的方式,向大家介绍与腾讯云客户合作过程中遇到的各种典型问题,以及相应的解决思路与 ...
- PB级大规模Elasticsearch集群运维与调优实践【>>戳文章免费体验Elasticsearch服务30天】
[活动]Elasticsearch Service免费体验馆>> Elasticsearch Service自建迁移特惠政策>>Elasticsearch Service新用户 ...
- PB 级大规模 Elasticsearch 集群运维与调优实践
PB 级大规模 Elasticsearch 集群运维与调优实践 https://mp.weixin.qq.com/s/PDyHT9IuRij20JBgbPTjFA | 导语 腾讯云 Elasticse ...
- 用POLARDB构建客到智能餐饮系统实践
在新零售成为大趋势的今天,餐饮行业也加入到这一浪潮之中.智能餐饮系统将帮助餐饮行业从多个维度提升自己的运营能力和收益,而打造智能餐饮系统SaaS化能力也成为了目前的一个热点.本文中果仁软件联合创始人& ...
随机推荐
- vite按需加载element-plus,减少项目体积,你必须学会
1.在项目中安装 $ npm install element-plus --save $ yarn add element-plus $ pnpm install element-plus 2.安装对 ...
- vue中sync的使用原来这么简单
sync的使用场景 有些时候子组件需要修改父组件传递过来的prop, 要去改变父组件的状态的时候就需要使用aync 看见这里有些同学可能会问?? 不是说不可以修改父组件传递到子组件的值吗? 为啥要修改 ...
- MySQL【一】基本使用----超详细教学
相关文章: win10下MySQL安装教程(MySql-8.0.26超级详细)_丨汀.的博客-CSDN博客 1.RDBMS(Relational Databases Management System ...
- 2.0 熟悉CheatEngine修改器
Cheat Engine 一般简称为CE,它是一款功能强大的开源内存修改工具,其主要功能包括.内存扫描.十六进制编辑器.动态调试功能于一体,且该工具自身附带了脚本工具,可以用它很方便的生成自己的脚本窗 ...
- 驱动开发:运用VAD隐藏R3内存思路
在进程的_EPROCESS中有一个_RTL_AVL_TREE类型的VadRoot成员,它是一个存放进程内存块的二叉树结构,如果我们找到了这个二叉树中我们想要隐藏的内存,直接将这个内存在二叉树中抹去,其 ...
- .NetCore 三种生命周期注入方式
.NetCore彻底诠释了"万物皆可注入"这句话的含义,在.NetCore中到处可见注入的使用.因此core中也提供了三种注入方式的使用,分别是: AddTransient:每次请 ...
- 利用ogg实现oracle到kafka的增量数据实时同步
前言 ogg即Oracle GoldenGate是Oracle的同步工具,本文讲如何配置ogg以实现Oracle数据库增量数据实时同步到kafka中,其中同步消息格式为json. 下面是我的源端和目标 ...
- 【译】发布 .NET Aspire 预览版 2(二)
原文 | Damian Edwards 翻译 | 郑子铭 组件更新 组件包现在有单独的图标 大多数 Aspire 组件的 NuGet 包现在都具有代表性图标,以便在 NuGet 包管理器对话框中更轻松 ...
- 【译】我为 .NET 开发人员准备的 2023 年 Visual Studio 10 大新功能
原文 | James Montemagno 翻译 | 郑子铭 Visual Studio 2022 在 2023 年发布了许多令人难以置信的功能,为 .NET 开发人员提供了大量新工具来提高他们的工作 ...
- Python OS.mkdirs与OS.makedirs的区别
os.mkdir只创建最外层目录,如果创建多级目录,报错"FileNotFoundError: [WinError 3] 系统找不到指定的路径".目录存在报错. os.makedi ...