记一次,使用python实现一键在爱发电发布带图片的动态
1、背景
本人喜欢转载一些youtube上的视频到b站上面,然后就会有些观众想要视频的封面,那我总不可能一个一个发吧,太麻烦了。故打算将资源发布到爱发电上面。但是爱发电却没有公开对应的api,只能自己动手了呀。
2、思路
发布一条动态,抓包看看调用了哪些api
写代码仿照其中的参数调用api
封装起来,增加易用性
3、发布一条动态,抓包看看调用了哪些api
3.1、发布动态
首先,发布动态长这个样子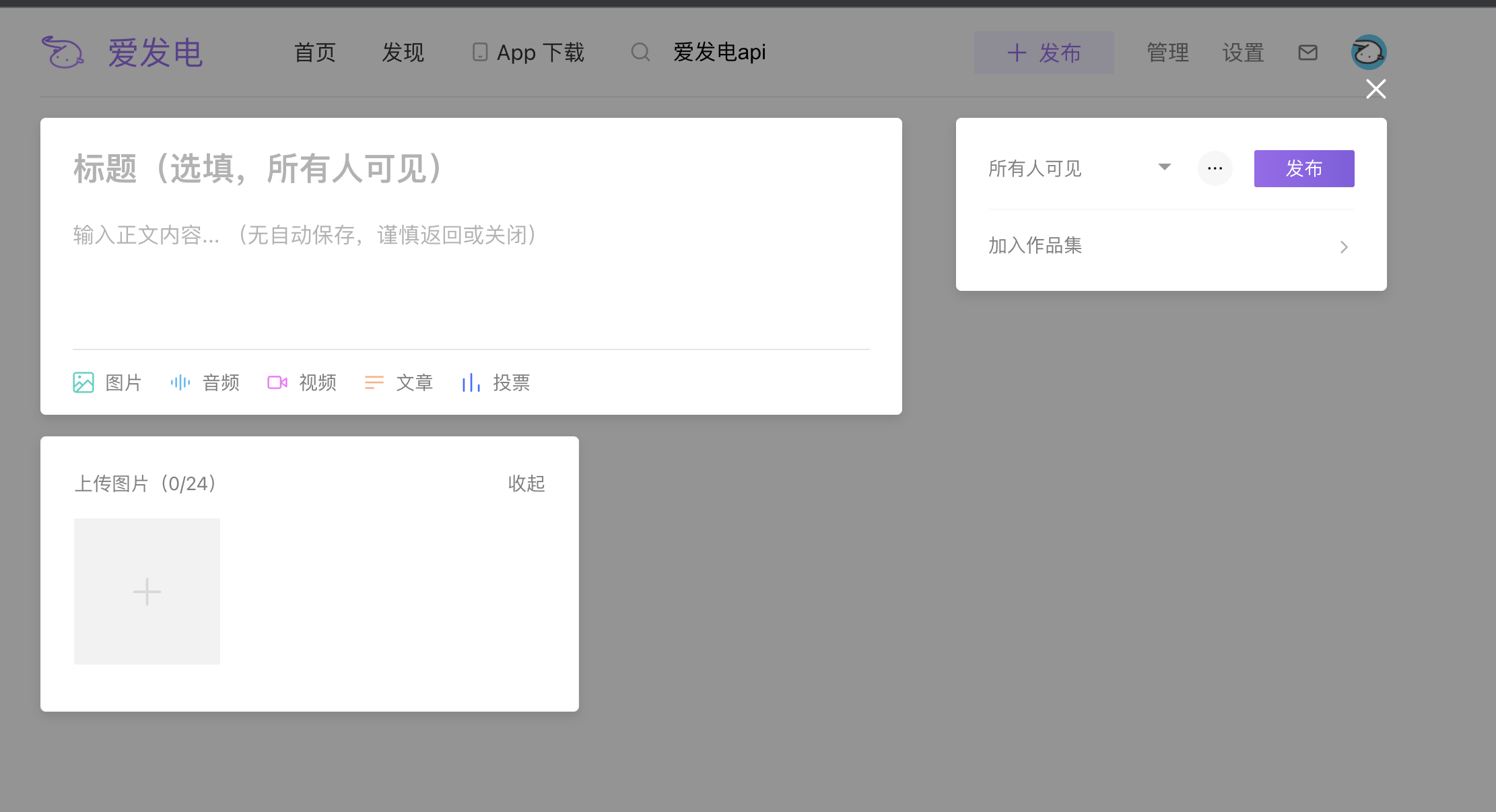
这里我们直接发布一条动态
3.2、抓包
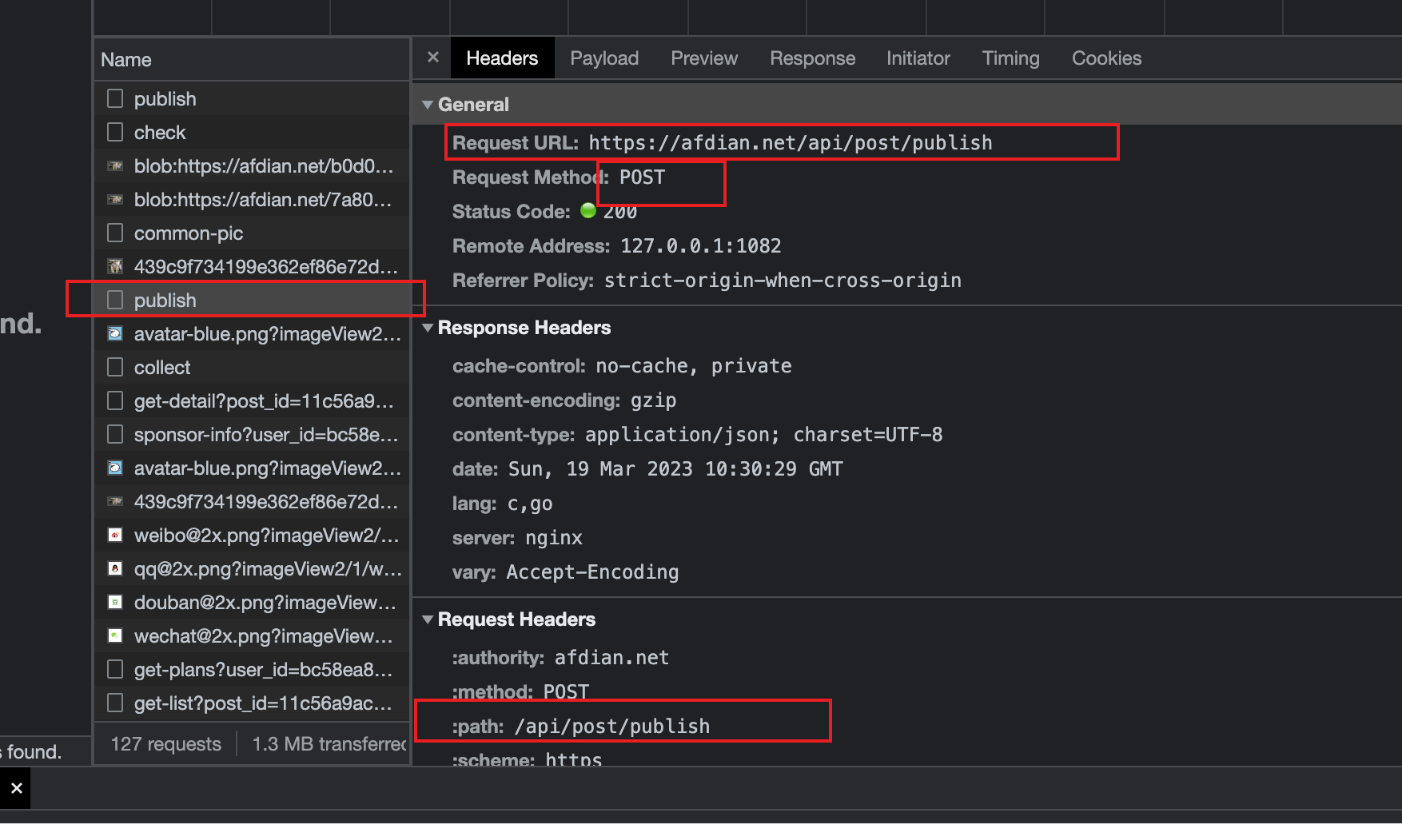
可以看到这个发布动态的请求地址为:https://afdian.net/api/post/publish,接下来我们看看我们的请求体是什么
可以看到这个表单挺简单的,但是有一个不太对劲的情况,就是字段"pics"的值不是我上传的地址的值("./img.jpg"),所以我猜,在调用api/post/publish接口前肯定调用了某个接口,将本地的图片转换成上图的链接,然后再拼接到上图中的字段"pics"中一起提交
3.3、抓取本地图片转换成爱发电链接的api
在发布动态的界面直接点击上传图片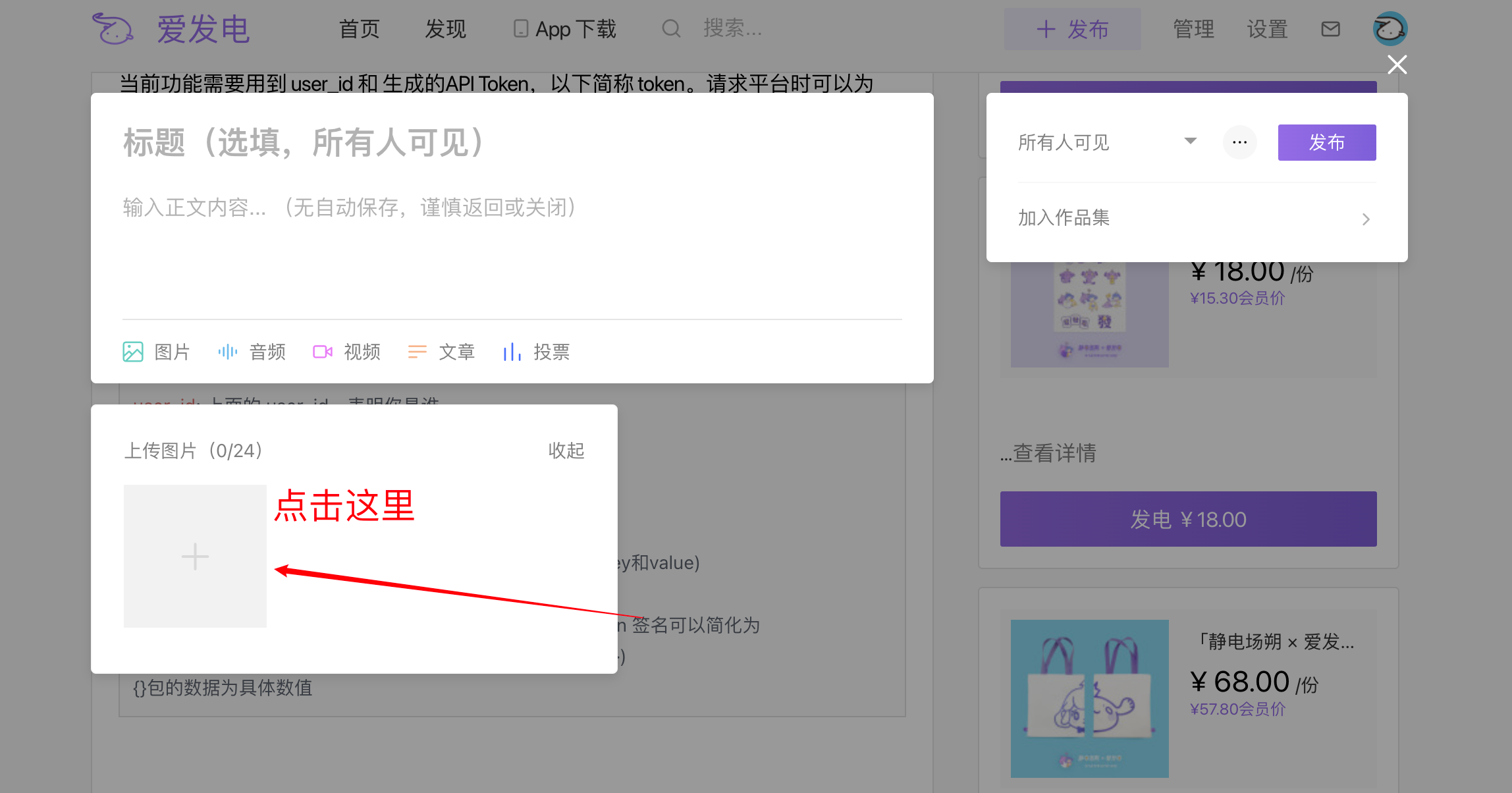
选择好图片,加载完毕之后,你就可以看见,调用了一个接口api/upload/common-pic,到这里我还没有点击发布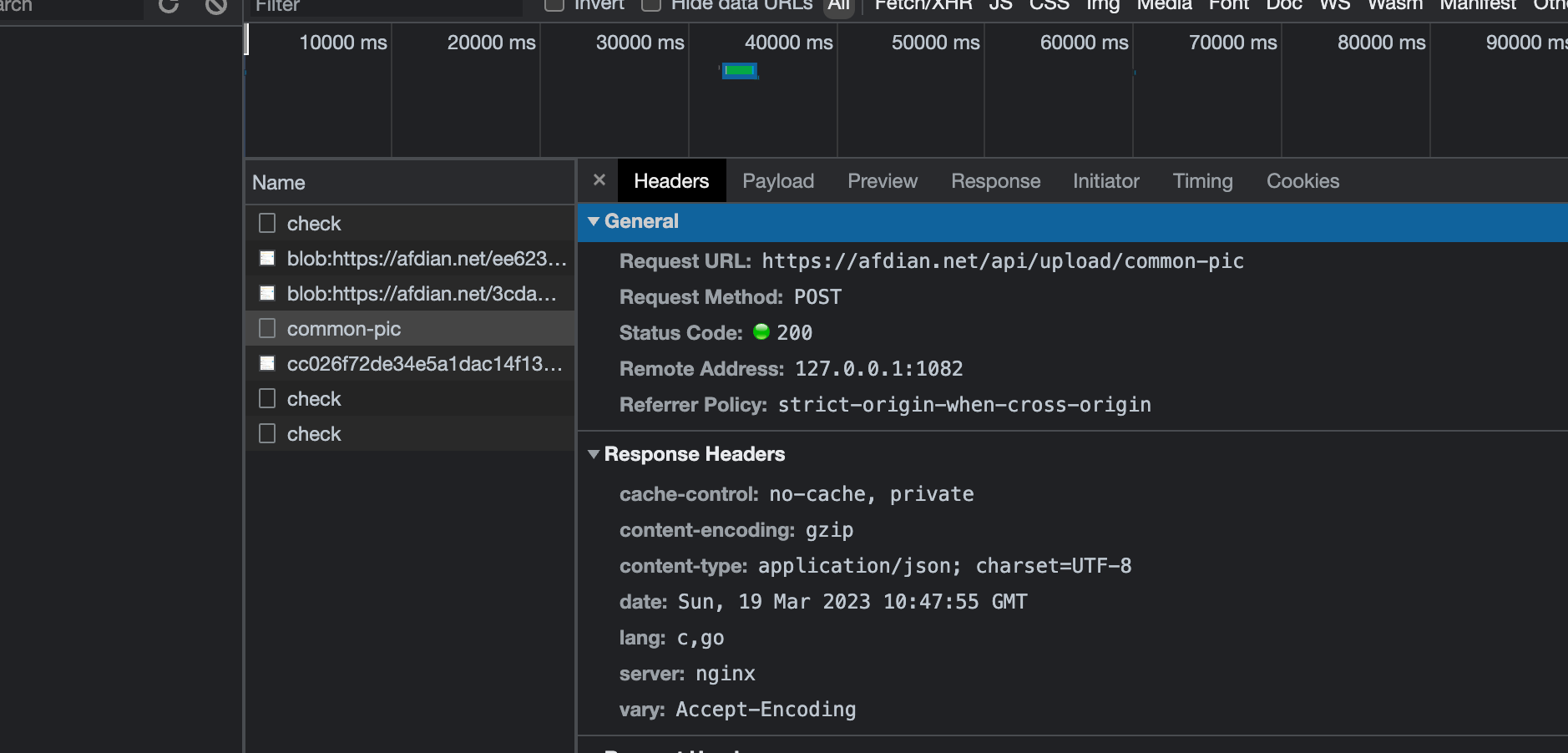

可以看到的确是和猜想的一样,在提交发布动态的表单前,先提交图片,获取到图片的链接之后,再拼接到发布动态的表单,进行发布
3.4、总结
到这里我们可以知道,一个完整的发布动态流程包括两个部分
1、将本地图片转换成一个官方链接,对应api(/upload/common-pic)
2、将表单中的信息(包括上面提到的链接)进行发布,对应api(/post/publish)
4、代码实现
首先我们初步选定了技术为python + request库
补充:代码中cookies你登陆爱发电后直接按F12,随便点几下有发送请求的按钮,然后在request中翻翻就可以看见了
4.1、将本地图片转换成爱发电官方链接
4.1.1、前期分析
我们先来看看我们需要模拟的request请求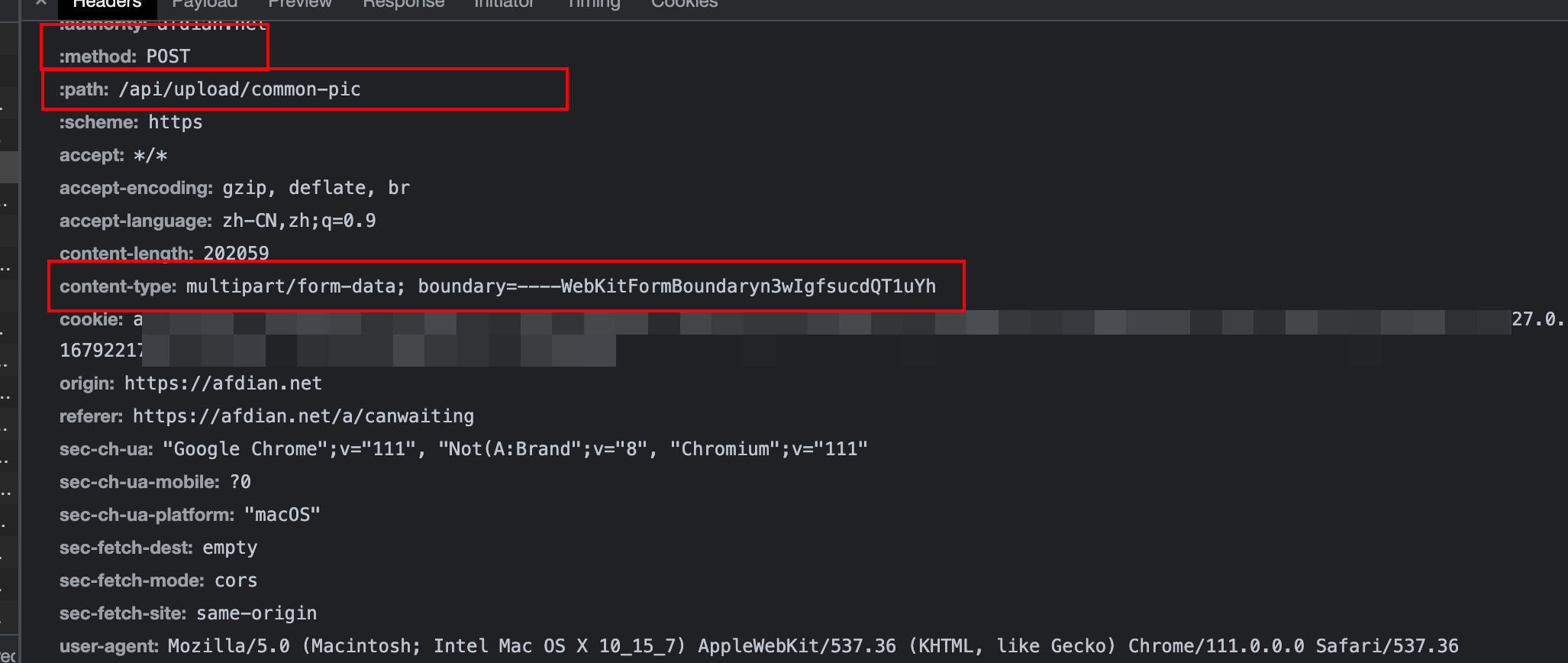
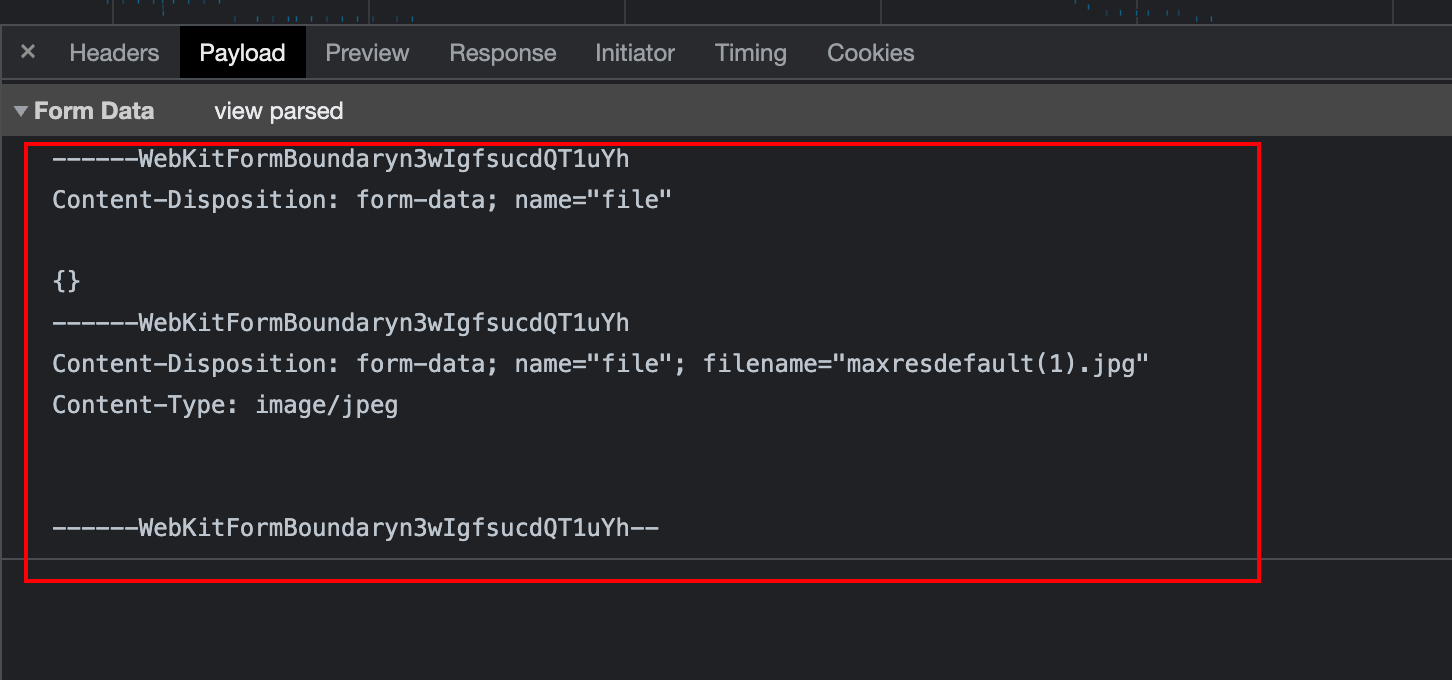
上网搜了一下,这里大概的意思就是爱发电的这个接口需要的content-type是比较少见的类型:multipart/form-data
然后第二张图就是我这次上传的数据的数据体
参考:https://www.jianshu.com/p/902452189ca9,这个给了我大概的思路,request库对于这种类型的支持不是太好,需要借助库requests_toolbelt。然后因为我的数据是文件类型,而该博客中的是文本,所以不能直接照搬
参考:https://www.cnblogs.com/yoyoketang/p/8024039.html,https://pypi.org/project/requests-toolbelt/终于把代码写出来了
4.1.2、代码
import requests
from requests_toolbelt import MultipartEncoder
# 1、初始化需要的数据,包括目标网址、请求头、cookies、图片路径等信息
url = 'https://afdian.net/api/upload/common-pic'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
cookies = {
'auth_token': 'xxxx',
'_gid':'xxxx',
'_ga_6STWKR7T9E': 'xxxx',
'_ga': 'xxxx'
}
img_path = 'img.jpg'
# 2、使用 MultipartEncoder 创建文件上传的 payload
file_payload = {
"name":"file",
"filename":img_path,
'file':(img_path,open(img_path,'rb'))
}
m = MultipartEncoder(file_payload)
# 3、补充头
headers['Content-Type'] = m.content_type # multipart/form-data;boundary=29cf7f1b13584a73a6630a738be8274a
# 4、发送请求
response = requests.post(url, headers=headers, data = m, cookies=cookies)
# 5、输出响应内容
print(response.text)

注意:这里我开启了转义,实际上我们需要的也是转义后的数据,不过到现在我还没进行处理
值得一提的是,我还没有进行“发布”呢,返回的链接就可以直接打开了,按道理来说,可以用作图床,但是不知道爱发电会不会进行检测,类似上传了的图片在多久没进行发布就会删除。不过,还是不要用作图床了,厚道一点,毕竟爱发电
4.1.3、进一步封装
因为我们需要的是这个官方链接,所以,这里我对此进行封装成一个函数
import json
import requests
from requests_toolbelt import MultipartEncoder
# 参数:图片地址
# 返回:官方链接
def get_link(img_path):
# 1、初始化需要的数据,包括目标网址、请求头、cookies、图片路径等信息
url = 'https://afdian.net/api/upload/common-pic'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
cookies = {
'auth_token': 'xxxx',
'_gid':'xxxx',
'_ga_6STWKR7T9E': 'xxxx',
'_ga': 'xxxx'
}
# 2、使用 MultipartEncoder 创建文件上传的 payload
file_payload = {
"name":"file",
"filename":img_path,
'file':(img_path,open(img_path,'rb'))
}
m = MultipartEncoder(file_payload)
# 3、补充头
headers['Content-Type'] = m.content_type # multipart/form-data; boundary=29cf7f1b13584a73a6630a738be8274a
# 4、发送请求
response = requests.post(url, headers=headers, data = m, cookies=cookies)
response.encoding = "unicode_escape" # 将utf-8 转换成 unicode
# 5、返回响应内容
# 5.1、将响应内容转换成json
response_json = json.loads(response.text)
# 5.2、返回想要的字段link
link = response_json['link']
return link
if __name__ == "__main__":
img_path = "img.jpg"
link = get_link(img_path)
print(link)
'''
输出:
https://pic1.afdiancdn.com/user/bc58exxxxxxx2540025c377/common/5239daxxxxxxxxxx80_h720_s117.jpg
'''
4.2、发布动态
4.2.1、前期分析
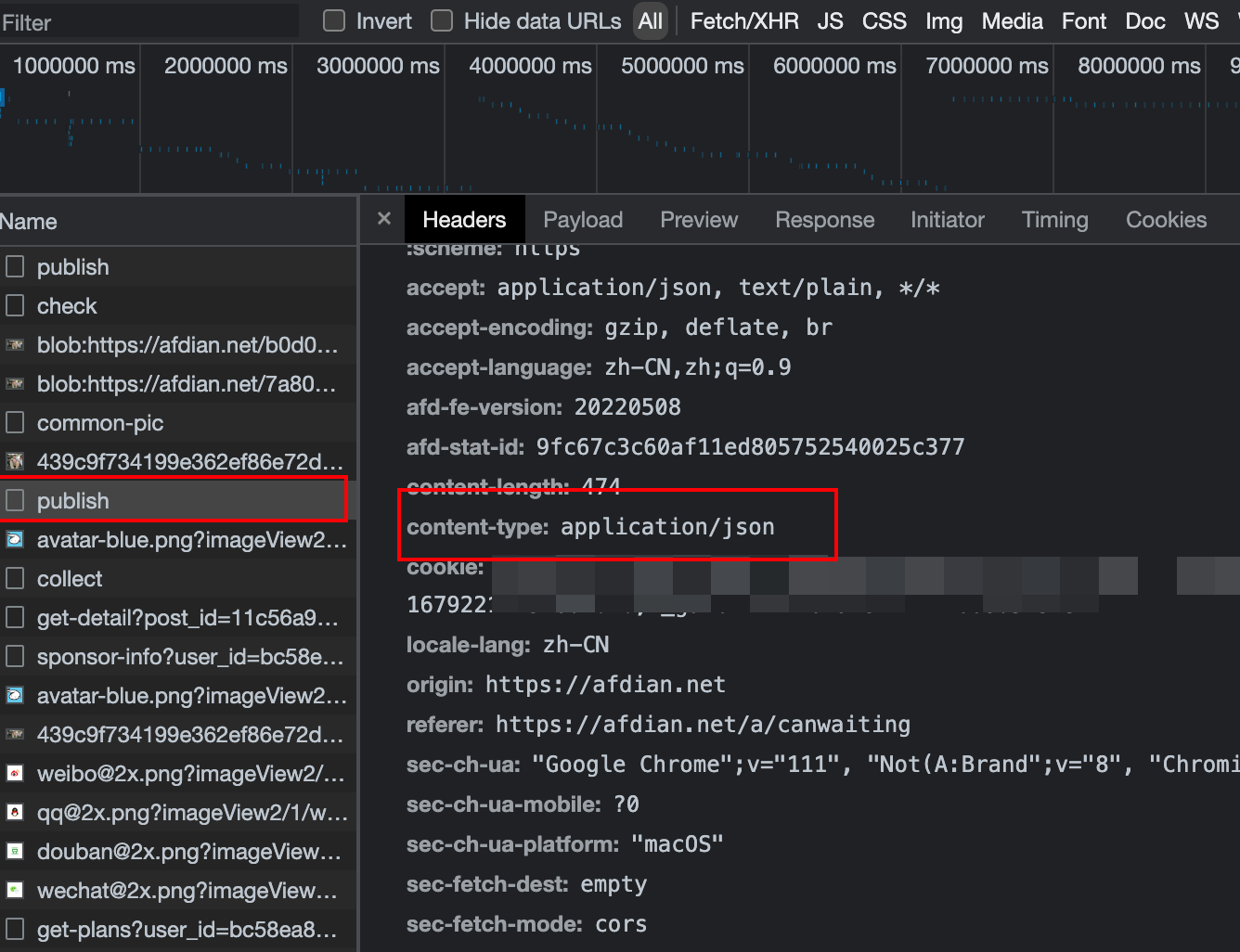
可以看到这里是json类型的数据,对应的数据字段太多,这里就不一一展示,等下在代码中你就知道了
4.2.2、代码
import json
import requests
from requests_toolbelt import MultipartEncoder
# 参数:图片地址
# 返回:官方链接
def get_link(img_path):
# 1、初始化需要的数据,包括目标网址、请求头、cookies、图片路径等信息
url = 'https://afdian.net/api/upload/common-pic'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
cookies = {
'auth_token': 'xxxx',
'_gid':'xxxx',
'_ga_6STWKR7T9E': 'xxxx',
'_ga': 'xxxx'
}
# 2、使用 MultipartEncoder 创建文件上传的 payload
file_payload = {
"name":"file",
"filename":img_path,
'file':(img_path,open(img_path,'rb'))
}
m = MultipartEncoder(file_payload)
# 3、补充头
headers['Content-Type'] = m.content_type # multipart/form-data; boundary=29cf7f1b13584a73a6630a738be8274a
# 4、发送请求
response = requests.post(url, headers=headers, data = m, cookies=cookies)
response.encoding = "unicode_escape" # 将utf-8 转换成 unicode
# 5、返回响应内容
# 5.1、将响应内容转换成json
response_json = json.loads(response.text)
# 5.2、返回想要的字段link
link = response_json['link']
return link
# 发布函数
# 传入:一个字典类型的数据,包含:标题、内容、图片链接
# 返回:响应数据
def publish(publish_data):
# 1、初始化需要的数据,包括目标网址、请求头、cookies、请求数据等信息
url = 'https://afdian.net/api/post/publish'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36'}
cookies = {
'auth_token': 'xxxx',
'_gid':'xxxx',
'_ga_6STWKR7T9E': 'xxxx',
'_ga': 'xxxx'
}
title = publish_data['title']
content = publish_data['content']
link = publish_data['link']
data_dict = {
"post_id":"",
"vote_id":"",
"cate":"normal",
"title":title,
"content":content,
"pics":link,
"is_public":"1",
"min_price":"0",
"audio":"",
"video":"",
"audio_thumb":"",
"video_thumb":"",
"type":"0",
"cover":"",
"group_id":"",
"is_feed":"0",
"plan_ids":"",
"album_ids":"",
"attachment":"[]",
"timing":"",
"optype":"publish",
"preview_text":""
}
# 4、发送请求
response = requests.post(url, headers=headers, data = data_dict, cookies=cookies)
# 5、返回响应内容
response.encoding = "unicode_escape" # 将utf-8 转换成 unicode
return response.text
if __name__ == "__main__":
img_path = "img.jpg"
link = get_link(img_path)
publish_data = {
"title" : "标题测试",
"content" : "内容测试",
"link" : link
}
rep = publish(publish_data)
print(rep)
4.2.3、成功
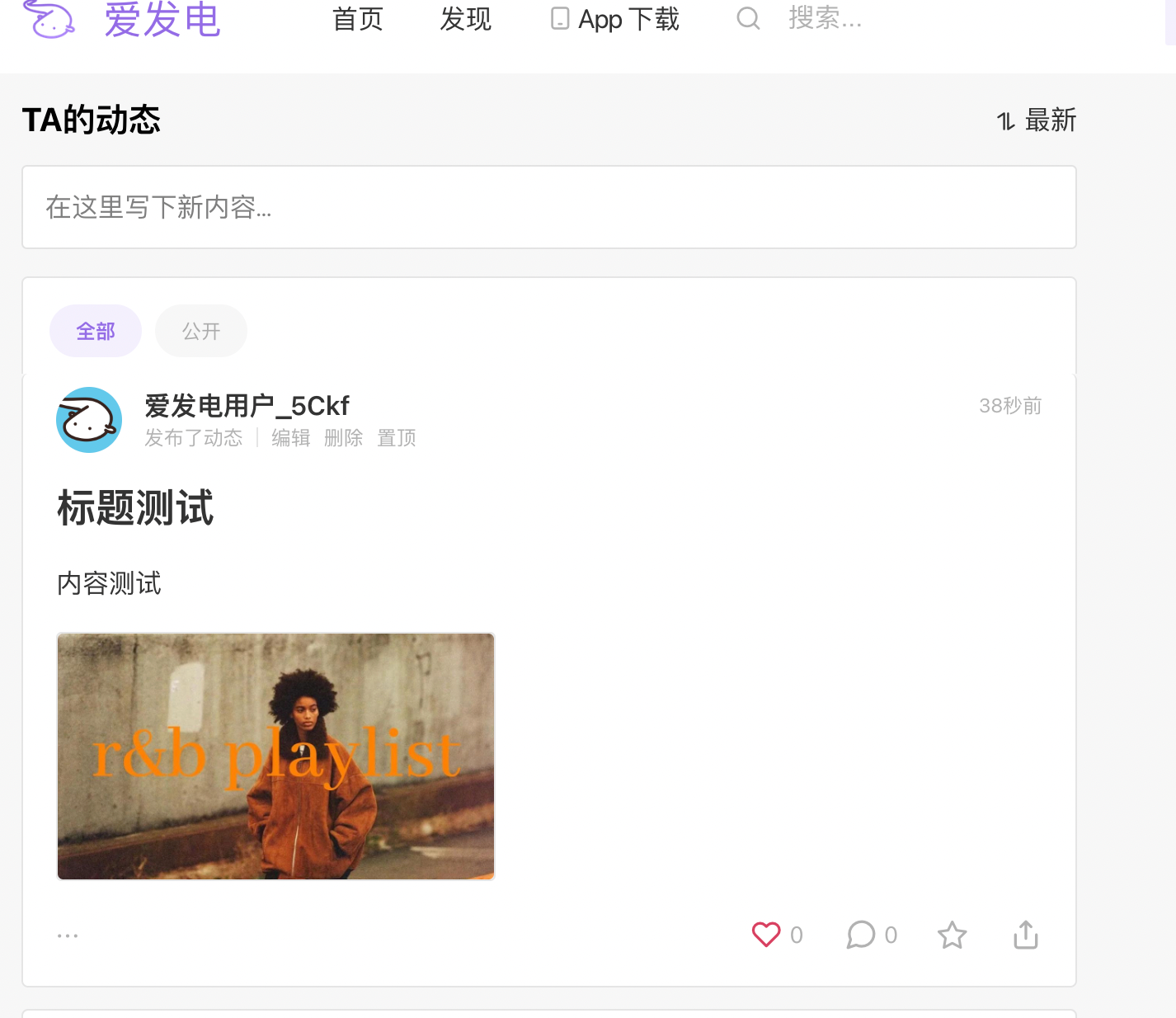
5、总结
5.1、完整代码 Github地址
https://github.com/Canwaiting/afdian-api
5.2、总结
写完这篇博文,自己也学到了不少,这是我写的最长的一篇博客,本来是当作记录自己思路的草稿,写着写着,整理整理,就发出来了。还有很多可以优化的地方,例如每个字段,我也没搞清具体是什么回事,还有上传多张图片要怎么办等等
记一次,使用python实现一键在爱发电发布带图片的动态的更多相关文章
- 记一次用python 的ConfigParser读取配置文件编码报错
记一次用python 的ConfigParser读取配置文件编码报错 ...... raise MissingSectionHeaderError(fpname, lineno, line)Confi ...
- [python爬虫] Selenium定向爬取海量精美图片及搜索引擎杂谈
我自认为这是自己写过博客中一篇比较优秀的文章,同时也是在深夜凌晨2点满怀着激情和愉悦之心完成的.首先通过这篇文章,你能学到以下几点: 1.可以了解Python简单爬取图片的一些思路和方法 ...
- 记一次数据库调优过程(IIS发过来SQLSERVER 的FETCH API_CURSOR语句是神马?)
记一次数据库调优过程(IIS发过来SQLSERVER 的FETCH API_CURSOR语句是神马?) 前几天帮客户优化一个数据库,那个数据库的大小是6G 这麽小的数据库按道理不会有太大的性能问题的, ...
- python连续爬取多个网页的图片分别保存到不同的文件夹
python连续爬取多个网页的图片分别保存到不同的文件夹 作者:vpoet mail:vpoet_sir@163.com #coding:utf-8 import urllib import ur ...
- Python中使用Flask、MongoDB搭建简易图片服务器
主要介绍了Python中使用Flask.MongoDB搭建简易图片服务器,本文是一个详细完整的教程,需要的朋友可以参考下 1.前期准备 通过 pip 或 easy_install 安装了 pymong ...
- python模块之imghdr(识别不同格式的图片文件)
# -*- coding: utf-8 -*- #python 27 #xiaodeng #python模块之imghdr(识别不同格式的图片文件) import imghdr '''>> ...
- Python(三) PIL, Image生成验证图片
Python(三) PIL, Image生成验证图片 安装好PIL,开始使用. 在PyCharm中新建一个文件:PIL_Test1.py 1 # PIL 应用练习 2 # 3 # import PIL ...
- *** Python版一键安装脚本
本脚本适用环境:系统支持:CentOS 6,7,Debian,Ubuntu内存要求:≥128M日期:2018 年 02 月 07 日 关于本脚本:一键安装 Python 版 *** 的最新版.友情提示 ...
- 【2020Python修炼记3】初识Python,你需要知道哪些(一)
一.编程语言简介 机器语言 计算机能直接理解的就是二进制指令,所以机器语言就是直接用二进制编程,这意味着机器语言是直接操作硬件的,因此机器语言属于低级语言, 此处的低级指的是底层.贴近计算机硬件(贴近 ...
- python模块一键安装
利用bat文件 在不懂电脑的小白电脑上一键安装你python环境所需要的模块(你想让她一个个安装,你会疯的) 先新建一个txt文件,把你需要安装的模块和版本号写进去: 然后再新建一个txt文件 然后把 ...
随机推荐
- 使用MyBatis时需要注意到的事情------执行添加、修改和删除操作时,一定要记得提交事务
今天在重写添加操作代码时,发现自己写的代码没有任何报错,使用断点进行查询,发现一切正常,但是注册使用的数据就是无法添加到数据库里面 然后就去之前看过的视频里面去找错误,就发现这样一个小细节: 在视频里 ...
- Windows 系统下怎么获取 UDP 本机地址
Windows 系统下怎么获取 UDP 本机地址 我们知道 UDP 获取远端地址非常简单,通常接口 recvfrom 就可以直接获取到远端的地址和端口:如果获取 UDP 的本机地址就需要点特殊处理了, ...
- 基于深度学习的智能PCB板缺陷检测系统(Python+清新界面+数据集)
摘要:智能PCB板缺陷检测系统用于智能检测工业印刷电路板(PCB)常见缺陷,自动化标注.记录和保存缺陷位置和类型,以辅助电路板的质检.本文详细介绍智能PCB板缺陷检测系统,在介绍算法原理的同时,给出P ...
- SpringBoot——配置嵌入式 Servlet容器
更多内容,前往 IT-BLOG 一.如何定制和修改Servlet容器的相关配置 前言:SpringBoot 在Web 环境下,默认使用的是 Tomact 作为嵌入式的 Servlet容器: [1]修 ...
- 全网最详细中英文ChatGPT-GPT-4示例文档-从0到1快速入门计算时间复杂度应用——官网推荐的48种最佳应用场景(附python/node.js/curl命令源代码,小白也能学)
目录 Introduce 简介 setting 设置 Prompt 提示 Sample response 回复样本 API request 接口请求 python接口请求示例 node.js接口请求示 ...
- Java 安全指南
Java 安全指南 后台类 I. 代码实现 1.1 数据持久化 1.1.1[必须]SQL语句默认使用预编译并绑定变量 Web后台系统应默认使用预编译绑定变量的形式创建sql语句,保持查询语句和数据相分 ...
- flutter---->阿里云oss的插件
目前为止,阿里云官方并没有dart版本的oss sdk,所以才开发了这个插件flutter_oss_aliyun提供对oss sdk的支持. flutter_oss_aliyun 一个访问阿里云oss ...
- SHA-256 简介及 C# 和 js 实现【加密知多少系列】
〇.简介 SHA-256 是 SHA-2 下细分出的一种算法.截止目前(2023-03)未出现"碰撞"案例,被视为是绝对安全的加密算法之一. SHA-2(安全散列算法 2:Secu ...
- THM-被动侦察和主动侦查
被动与主动侦察 在计算机系统和网络出现之前,孙子兵法在孙子兵法中教导说:"知己知彼,必胜不疑." 如果您扮演攻击者的角色,则需要收集有关目标系统的信息.如果你扮演防御者的角色,你需 ...
- [ElasticSearch]修改开源安全组件Search Guard-6 用户密码
ES有很多的安全组件可用,例如: X-pack,Sarch Guard.但目前开源免费的,仅Search Guard. 1 前置条件 Elastic Search 6 服务安装成功,且成功运行. ES ...