HanLP — 词性标注
词性(Part-Of-Speech,POS)指的是单词的语法分类,也称为词类。同一个类别的词语具有相似的语法性质
所有词性的集合称为词性标注集。
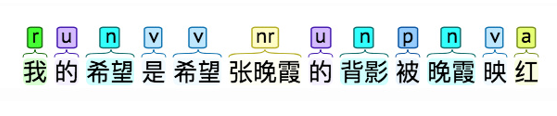
词性的用处
当下游应用遇到OOV时,可以通过OOV的词性猜测用法词性也可以直接用于抽取一些信息,比如抽取所有描述特定商品的形容词等
词性标注
词性标注指的是为句子中每个单词预测一个词性标签的任务
- 汉语中一个单词多个词性的现象很常见(称作兼类词)
- OOV是任何自然语言处理任务的难题
词性标注模型
联合模型
同时进行多个任务的模型称为联合模型(joint model)
商 B-名词
品 E-名词
和 S-连词
服 B-名词
务 E-名词
流水线式
中文分词语料库远远多于词性标注语料库
实际工程上通常在大型分词语料库上训练分词器
然后与小型词性标注语料库上的词性标注模型灵活组合为一个异源的流水线式词法分析器
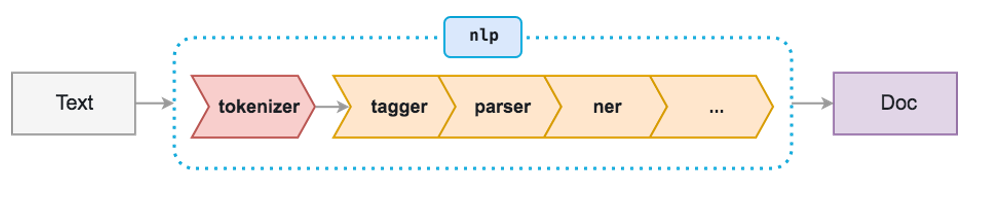
词性标注语料库与标注集
目前还没有一个被广泛接受的汉语词性划分标准
本节选取其中一些授权宽松,容易获得的语料库作为案例,介绍其规模、标注集等特点
《人民日报》语料库与PKU标注集
语料库中的一句样例为:
1997年/t 12月/t 31日/t 午夜/t ,/w 聚集/v 在/p 日本/ns 东京/ns 增上寺/ns 的/u 善男信女/i 放飞/v 气球/n ,/w 祈祷/v 新年/t 好运/n 。
国家语委语料库与863标注集
国家语言文字工作委员会建设的大型语料库
国家语委语料库的标注规范《信息处理用现代汉语词类标记集规范》在2006年成为国家标准
其词类体系分为20个一级类、29个二级类
《诛仙》语料库与CTB标注集
哈工大张梅山老师公开了网络小说《诛仙》上的标注语料
远处/NN ,/PU 小竹峰/NR 诸/DT 人/NN 处/NN ,/PU 陆雪琪/NR 缓缓/AD 从/P 张小凡/NR 身上/NN 收回/VV 目光/NN ,/PU 落到/VV 了/AS 前方/NN 碧瑶/NR 的/DEG 身上/NN ,/PU 默默/AD 端详/VV 著/AS 她/PN 。/PU
《诛仙》语料库采用的标注集与CTB(Chinese Treebank,中文树库)相同,一共33种词类
序列标注模型应用于词性标注
HanLP中词性标注由POSTagger接口提供
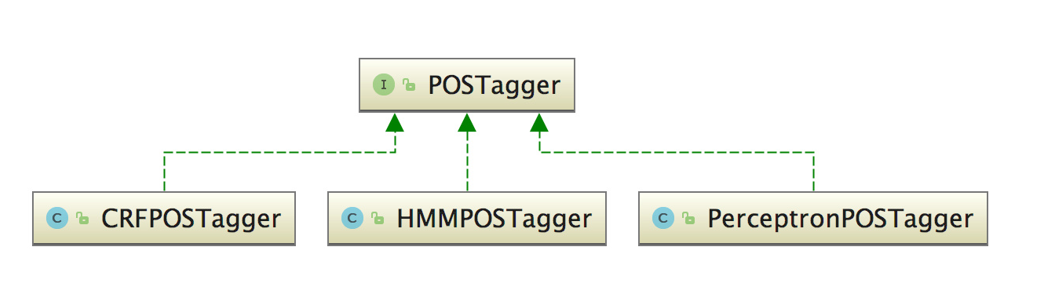
基于隐马尔可夫模型的词性标注
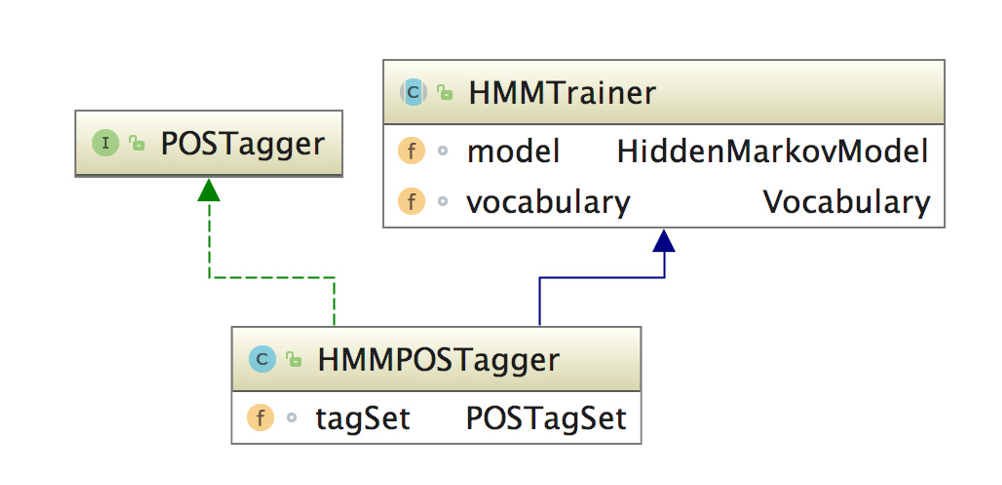
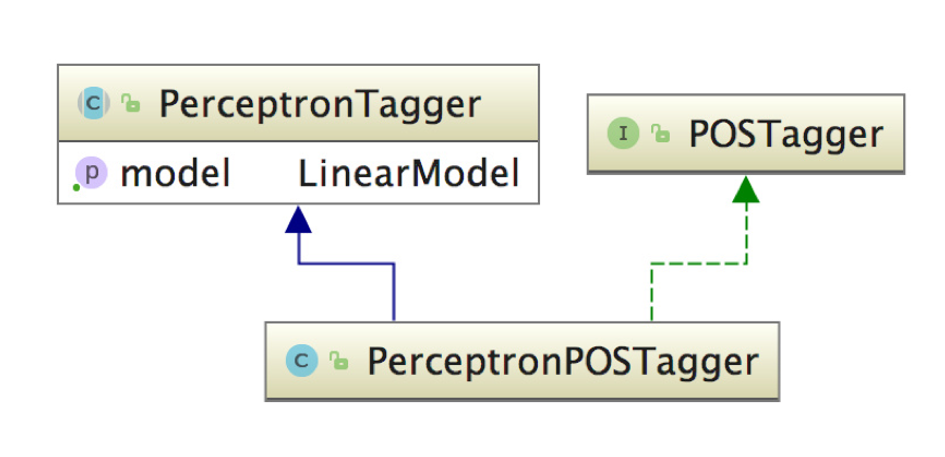
基于感知机的词性标注
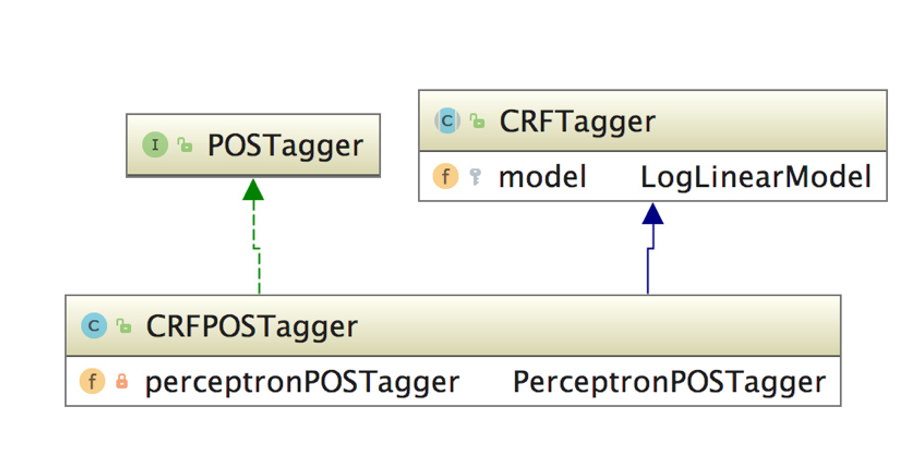
基于条件随机场的词性标注
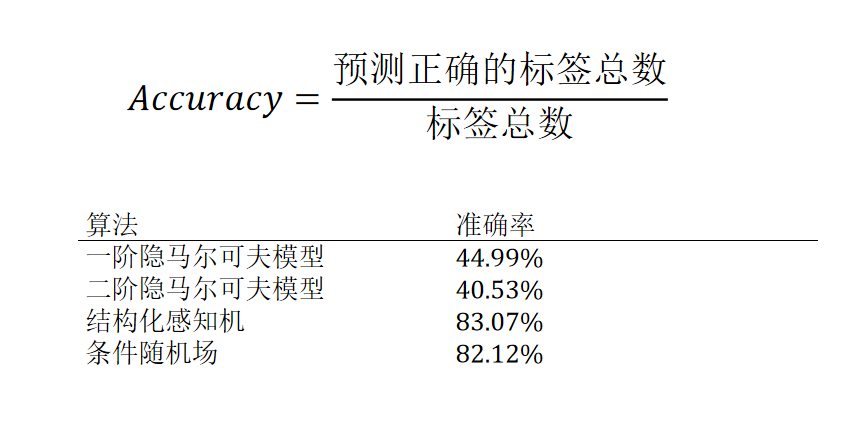
词性标注评测
自定义词性
在工程上,许多用户希望将特定的一些词语打上自定义的标签,称为自定义词性
朴素实现
规则系统,用户将自己关心的词语以及自定义词性以词典的形式交给HanLP挂载
CustomDictionary.insert("苹果", "手机品牌 1")CustomDictionary.insert("iPhone X", "手机型号 1")analyzer = PerceptronLexicalAnalyzer()analyzer.enableCustomDictionaryForcing(True)print(analyzer.analyze("你们苹果iPhone X保修吗?"))print(analyzer.analyze("多吃苹果有益健康"))
你们/r 苹果/手机品牌 iPhone X/手机型号 保修/v 吗/y ?/w
多/ad 吃/v 苹果/手机品牌 有益健康/i
标注语料
PerceptronPOSTagger posTagger = trainPerceptronPOS(ZHUXIAN); // 训练AbstractLexicalAnalyzer analyzer = new AbstractLexicalAnalyzer(new PerceptronSegmenter(), posTagger); // 包装System.out.println(analyzer.analyze("陆雪琪的天琊神剑不做丝毫退避,直冲而上,瞬间,这两道奇光异宝撞到了一起。")); // 分词+标注
陆雪琪/NR 的/DEG 天琊神剑/NN 不/AD 做/VV 丝毫/NN 退避/VV ,/PU 直冲/VV 而/MSP 上/VV ,/PU 瞬间/NN ,/PU 这/DT 两/CD 道/M 奇光/NN 异宝/NN 撞/VV 到/VV 了/AS 一起/AD 。/PU
总结
隐马尔可夫模型、感知机和条件随机场三种词性标注器
为了实现自定义词性
依靠词典匹配虽然简单但非常死板,只能用于一词一义的情况
如果涉及兼类词,标注一份领域语料才是正确做法
HanLP — 词性标注的更多相关文章
- 自然语言15.1_Part of Speech Tagging 词性标注
QQ:231469242 欢迎喜欢nltk朋友交流 https://en.wikipedia.org/wiki/Part-of-speech_tagging In corpus linguistics ...
- HanLP自然语言处理包介绍
支持中文分词(N-最短路分词.CRF分词.索引分词.用户自定义词典.词性标注),命名实体识别(中国人名.音译人名.日本人名.地名.实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换, ...
- HanLP分词命名实体提取详解
HanLP分词命名实体提取详解 分享一篇大神的关于hanlp分词命名实体提取的经验文章,文章中分享的内容略有一段时间(使用的hanlp版本比较老),最新一版的hanlp已经出来了,也可以去看看新版 ...
- pyhanlp 中文词性标注与分词简介
pyhanlp 中文词性标注与分词简介 pyhanlp实现的分词器有很多,同时pyhanlp获取hanlp中分词器也有两种方式 第一种是直接从封装好的hanlp类中获取,这种获取方式一共可以获取五种分 ...
- HanLP自然语言处理包开源(包含源码)
支持中文分词(N-最短路分词.CRF分词.索引分词.用户自定义词典.词性标注),命名实体识别(中国人名.音译人名.日本人名.地名.实体机构名识别),关键词提取,自动摘要,短语提取,拼音转换,简繁转换, ...
- python之NLP词性标注
1.知识点 包括中文和英文的词性标注主要使用的库是nltk和jiaba 2.代码 # coding = utf-8 import nltk from nltk.corpus import stopwo ...
- 常用中文分词工具分词&词性标注简单应用(jieba、pyhanlp、pkuseg、foolnltk、thulac、snownlp、nlpir)
1.jieba分词&词性标注 import jieba import jieba.posseg as posseg txt1 =''' 文本一: 人民网华盛顿3月28日电(记者郑琪)据美国约翰 ...
- pyhanlp 停用词与用户自定义词典功能详解
hanlp的词典模式 之前我们看了hanlp的词性标注,现在我们就要使用自定义词典与停用词功能了,首先关于HanLP的词性标注方式具体请看HanLP词性标注集. 其核心词典形式如下: 自定义词典 自定 ...
- Python分词工具——pyhanlp
本文为本人学习pyhanlp的笔记,大多知识点来源于GitHubhttps://github.com/hankcs/HanLP/blob/master/README.md,文中的demo代码来源于该G ...
- HanLP 自然语言处理 for nodejs
HanLP 自然语言处理 for nodejs ·支持中文分词(N-最短路分词.CRF分词.索引分词.用户自定义词典.词性标注),命名实体识别(中国人名.音译人名.日本人名.地名.实体机构名识别),关 ...
随机推荐
- 例题 5-7 丑数(Ugly Numbers,UVa 136)
题意: 丑数是一些因子只有2,3,5的数.数列1,2,3,4,5,6,8,9,10,12,15--写出了从小到大的前11个丑数,1属于丑数.现在请你编写程序,找出第1500个丑数是什么. 思路: 如果 ...
- 安全情报 | Pypi再现窃密攻击投毒
概述 悬镜安全自研的开源组件投毒检测平台通过对主流开源软件仓库(包括Pypi.NPM.Ruby等)发布的组件包进行持续性监控和自动化代码安全分析,同时结合专家安全经验复审,能够及时发现组件包投毒事件并 ...
- token原理分析
- C语言基础之第一个C程序
前言 在开始学习 C 语言的基础知识之前,我们需要学习如何编写.编译和运行第一个 C 程序. 要编写第一个 C 程序,打开 C 控制台并编写以下代码,我这里直接使用vs2022进行代码的编写: #in ...
- zookeeper 集群环境搭建及集群选举及数据同步机制
本文为博主原创,未经允许不得转载: 目录: 1. 分别创建3个data目录用于存储各节点数据 2. 编写myid文件 3. 编写配置文件 4.分别启动 5.分别查看状态 6. 检查集群复制情况 ...
- MySQL的SQL优化常用30种方法[转]
MySQL的SQL优化常用30种方法 1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中使用!=或< ...
- 分享这位大神的WPF界面设计系列视频
本文结构: 前言 视频详情 搬运详情 总结 4.1 国内推荐WPF资源 4.2 B站是学习的天堂 4.3 去外面看看 4.4 个人给C/S同学建议 1. 前言 今天介绍油管上一个大佬发的WPF设计系列 ...
- [转帖]max_allowed_packet 与 SQL 长度的关系
https://www.oceanbase.com/knowledge-base/oceanbase-database-1000000000210013 适用版本:V2.1.x.V2.2.x.V3.1 ...
- [转帖]如何理解 kernel.pid_max & kernel.threads-max & vm.max_map_count
https://www.cnblogs.com/apink/p/15728381.html 背景说明 运行环境信息,Kubernetes + docker .应用系统java程序 问题描述 首先从Ku ...
- SQLServer解决deadlock问题的一个场景
SQLServer解决deadlock问题的一个场景 背景 公司产品出现过很多次dead lock 跟研发讨论了很久, 都没有具体的解决思路 但是这边知道了一个SQLServer数据库上面计划100% ...