神经网络入门篇:详解随机初始化(Random+Initialization)
当训练神经网络时,权重随机初始化是很重要的。对于逻辑回归,把权重初始化为0当然也是可以的。但是对于一个神经网络,如果把权重或者参数都初始化为0,那么梯度下降将不会起作用。
来看看这是为什么。
有两个输入特征,\(n^{[0]} = 2\),2个隐藏层单元\(n^{[1]}\)就等于2。
因此与一个隐藏层相关的矩阵,或者说\(W^{[1]}\)是2*2的矩阵,假设把它初始化为0的2*2矩阵,\(b^{[1]}\)也等于 \([0\;0]^T\),把偏置项\(b\)初始化为0是合理的,但是把\(w\)初始化为0就有问题了。
那这个问题如果按照这样初始化的话,总是会发现\(a_{1}^{[1]}\) 和 \(a_{2}^{[1]}\)相等,这个激活单元和这个激活单元就会一样。因为两个隐含单元计算同样的函数,当做反向传播计算时,这会导致\(\text{dz}_{1}^{[1]}\) 和 \(\text{dz}_{2}^{[1]}\)也会一样,对称这些隐含单元会初始化得一样,这样输出的权值也会一模一样,由此\(W^{[2]}\)等于\([0\;0]\);
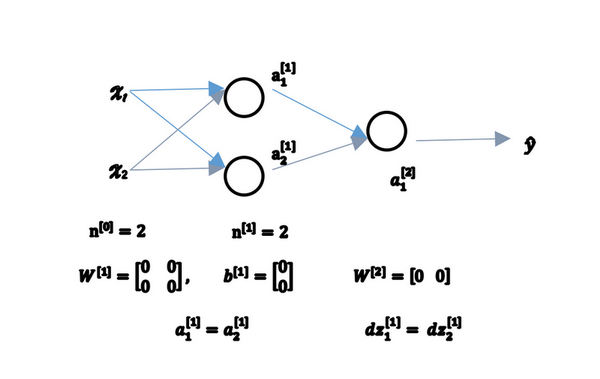
图1.11.1
但是如果这样初始化这个神经网络,那么这两个隐含单元就会完全一样,因此他们完全对称,也就意味着计算同样的函数,并且肯定的是最终经过每次训练的迭代,这两个隐含单元仍然是同一个函数,令人困惑。\(dW\)会是一个这样的矩阵,每一行有同样的值因此做权重更新把权重\(W^{[1]}\implies{W^{[1]}-adW}\)每次迭代后的\(W^{[1]}\),第一行等于第二行。
由此可以推导,如果把权重都初始化为0,那么由于隐含单元开始计算同一个函数,所有的隐含单元就会对输出单元有同样的影响。一次迭代后同样的表达式结果仍然是相同的,即隐含单元仍是对称的。通过推导,两次、三次、无论多少次迭代,不管训练网络多长时间,隐含单元仍然计算的是同样的函数。因此这种情况下超过1个隐含单元也没什么意义,因为他们计算同样的东西。当然更大的网络,比如有3个特征,还有相当多的隐含单元。
如果要初始化成0,由于所有的隐含单元都是对称的,无论运行梯度下降多久,他们一直计算同样的函数。这没有任何帮助,因为想要两个不同的隐含单元计算不同的函数,这个问题的解决方法就是随机初始化参数。应该这么做:把\(W^{[1]}\)设为np.random.randn(2,2)(生成高斯分布),通常再乘上一个小的数,比如0.01,这样把它初始化为很小的随机数。然后\(b\)没有这个对称的问题(叫做symmetry breaking problem),所以可以把 \(b\) 初始化为0,因为只要随机初始化\(W\)就有不同的隐含单元计算不同的东西,因此不会有symmetry breaking问题了。相似的,对于\(W^{[2]}\)可以随机初始化,\(b^{[2]}\)可以初始化为0。
\(W^{[1]} = np.random.randn(2,2)\;*\;0.01\;,\;b^{[1]} = np.zeros((2,1))\)
\(W^{[2]} = np.random.randn(2,2)\;*\;0.01\;,\;b^{[2]} = 0\)
也许会疑惑,这个常数从哪里来,为什么是0.01,而不是100或者1000。通常倾向于初始化为很小的随机数。因为如果用tanh或者sigmoid激活函数,或者说只在输出层有一个Sigmoid,如果(数值)波动太大,当计算激活值时\(z^{[1]} = W^{[1]}x + b^{[1]}\;,\;a^{[1]} = \sigma(z^{[1]})=g^{[1]}(z^{[1]})\)如果\(W\)很大,\(z\)就会很大或者很小,因此这种情况下很可能停在tanh/sigmoid函数的平坦的地方(见图3.8.2),这些地方梯度很小也就意味着梯度下降会很慢,因此学习也就很慢。
回顾一下:如果\(w\)很大,那么很可能最终停在(甚至在训练刚刚开始的时候)\(z\)很大的值,这会造成tanh/Sigmoid激活函数饱和在龟速的学习上,如果没有sigmoid/tanh激活函数在整个的神经网络里,就不成问题。但如果做二分类并且的输出单元是Sigmoid函数,那么不会想让初始参数太大,因此这就是为什么乘上0.01或者其他一些小数是合理的尝试。对于\(w^{[2]}\)一样,就是np.random.randn((1,2)),猜会是乘以0.01。
事实上有时有比0.01更好的常数,当训练一个只有一层隐藏层的网络时(这是相对浅的神经网络,没有太多的隐藏层),设为0.01可能也可以。但当训练一个非常非常深的神经网络,可能要试试0.01以外的常数。无论如何它通常都会是个相对小的数。
好了,看完神经网络入门篇。就已经知道如何建立一个一层的神经网络了,初始化参数,用前向传播预测,还有计算导数,结合反向传播用在梯度下降中。
神经网络入门篇:详解随机初始化(Random+Initialization)的更多相关文章
- PHP函数篇详解十进制、二进制、八进制和十六进制转换函数说明
PHP函数篇详解十进制.二进制.八进制和十六进制转换函数说明 作者: 字体:[增加 减小] 类型:转载 中文字符编码研究系列第一期,PHP函数篇详解十进制.二进制.八进制和十六进制互相转换函数说明 ...
- 走向DBA[MSSQL篇] 详解游标
原文:走向DBA[MSSQL篇] 详解游标 前篇回顾:上一篇虫子介绍了一些不常用的数据过滤方式,本篇详细介绍下游标. 概念 简单点说游标的作用就是存储一个结果集,并根据语法将这个结果集的数据逐条处理. ...
- java 日志体系(三)log4j从入门到详解
java 日志体系(三)log4j从入门到详解 一.Log4j 简介 在应用程序中添加日志记录总的来说基于三个目的: 监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作: 跟踪代 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- (十八)整合Nacos组件,环境搭建和入门案例详解
整合Nacos组件,环境搭建和入门案例详解 1.Nacos基础简介 1.1 关键特性 1.2 专业术语解释 1.3 Nacos生态圈 2.SpringBoot整合Nacos 2.1 新建配置 2.2 ...
- 【深度学习系列】手写数字识别卷积神经--卷积神经网络CNN原理详解(一)
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- 【深度学习系列】卷积神经网络CNN原理详解(一)——基本原理
上篇文章我们给出了用paddlepaddle来做手写数字识别的示例,并对网络结构进行到了调整,提高了识别的精度.有的同学表示不是很理解原理,为什么传统的机器学习算法,简单的神经网络(如多层感知机)都可 ...
- es6入门4--promise详解
可以说每个前端开发者都无法避免解决异步问题,尤其是当处理了某个异步调用A后,又要紧接着处理其它逻辑,而最直观的做法就是通过回调函数(当然事件派发也可以)处理,比如: 请求A(function (请求响 ...
- Django入门基础详解
本次使用django版本2.1.2 安装django 安装最新版本 pip install django 安装指定版本 pip install django==1.10.1 查看本机django版本 ...
- 日志处理(一) log4j 入门和详解(转)
log4j 入门. 详解 转自雪飘寒的文章 1. Log4j 简介 在应用程序中添加日志记录总的来说基于三 个目的: 监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作 ...
随机推荐
- RobotFrameWork环境搭建及使用
RF环境搭建 首先安装python并且配置python环境变量 pip install robotframework pip install robotframework-ride 生产桌面快捷方式 ...
- Cesium 概述 (二) 空间数据可视化
https://blog.csdn.net/happyduoduo1/article/details/51865811/
- 微服务项目使用RabbitMQ
微服务项目使用RabbitMQ 很久未用RabbitMQ了,根据网上的Demo,大多数是一个服务包含所有的生产者和消费者和配置,当自己去搭建服务的时候,还需要一些思考各种包的划分.无法无脑CV大法,所 ...
- nlp入门(五)隐马尔科夫模型
源码请到:自然语言处理练习: 学习自然语言处理时候写的一些代码 (gitee.com) 一.马尔科夫模型概念 1.1 马尔科夫模型:具有马尔可夫性质并以随机过程为基础的模型 1.2 马尔科夫性质:过去 ...
- 干掉 CRUD!这个API开发神器效率爆炸,无需定义MVC类!!
简介 magic-api 能够只通过 UI 界面就能完成简单常用的接口开发,能够支持市面上多数的关系性数据库,甚至还支持非关系性数据库 MongoDB. 通过 magic-api 提供的 UI 界面完 ...
- 如何通过关键词搜索API接口获取1688的商品详情
如果你是一位电商运营者或者是想要进行1688平台产品调研的人员,你可能需要借助API接口来获取你所需要的信息.在这篇文章中,我们将会讨论如何通过关键词搜索API接口获取1688的商品详情. 第一步:获 ...
- KRPANO 最新官方文档中文版(持续更新)
KRPano最新官方文档中文版分享,后续持续更新: http://docs.krpano.tech/ 本博文发表于:http://www.krpano.tech/archives/849 发布者:屠龙 ...
- 2023年Vue开发中的8个最佳工具
前言 Vue.js,一款当今非常流行的基于JavaScript的开源框架,旨在构建动态的可交互应用. Vue.js以其直观的语法和灵活的架构而广受全球开发者的欢迎和赞誉.随着时间的推移,Vue不断进化 ...
- MySQL实战实战系列 07 行锁功过:怎么减少行锁对性能的影响?
在上一篇文章中,我跟你介绍了 MySQL 的全局锁和表级锁,今天我们就来讲讲 MySQL 的行锁. MySQL 的行锁是在引擎层由各个引擎自己实现的.但并不是所有的引擎都支持行锁,比如 MyISAM ...
- PHPStudy hosts文件可能不存在或被阻止打开及同步hosts失败问题
在使用PHPStudy建站包时,有时会遇到同步hosts失败的问题,可能是因为hosts文件不存在或被阻止打开.这个问题通常可以通过以下几个步骤解决: 步骤一:检查hosts文件是否存在 首先,我们需 ...