Python+SVM
# !/usr/bin/env python
# encoding: utf-8
# SVM算法 支持向量机
from sklearn import svm
import numpy as np
from sklearn import model_selection
import matplotlib.pyplot as plt
import matplotlib as mpl
from matplotlib import colors from sklearn.datasets import load_iris # (1)加载数据集数据
iris = load_iris()
# 样本数据150*4二维数据,代表150个样本,每个样本4个属性分别为花瓣和花萼的长、宽
data = iris.data
#(2)将原始数据集划分成训练集和测试集
X=data # 数据集合
x=X[:,2:4]# 在X中取后面两列作为特征 花瓣长度和花瓣宽度
x=X[:,0:2]# 在X中取前面两列作为特征 花萼长度和花萼宽度
y = iris.target # 对应的标签
x_train,x_test,y_train,y_test=model_selection.train_test_split(x,y,random_state=0,test_size=0.25)# 这个函数x只能够取两个 可能是因为坐标系是平面的关系??
# 用train_test_split将数据随机分为训练集和测试集,测试集占总数据的30%(test_size=0.3),random_state是随机数种子
# 参数解释:
# x:train_data:所要划分的样本特征集。
# y:train_target:所要划分的样本结果。
# test_size:样本占比,如果是整数的话就是样本的数量。
# random_state:是随机数的种子。
# (随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
# 随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。)
#(3)搭建模型,训练SVM分类器
classifier=svm.SVC(kernel='rbf',gamma=0.2,decision_function_shape='ovo',C=1)
# C越大,相当于惩罚松弛变量,希望松弛变量接近0,即对误分类的惩罚增大,趋向于对训练集全分对的情况,这样对训练集测试时准确率很高,但泛化能力弱。
# C值小,对误分类的惩罚减小,允许容错,将他们当成噪声点,泛化能力较强
# kernel='linear'时,为线性核函数,C越大分类效果越好,但有可能会过拟合(defaul C=1)。
# kernel='rbf'(default)时,为高斯核函数,gamma值越小,分类界面越连续;gamma值越大,分类界面越“散”,分类效果越好,但有可能会过拟合。
# decision_function_shape='ovo'时,为one v one分类问题,即将类别两两之间进行划分,用二分类的方法模拟多分类的结果。
# decision_function_shape='ovr'时,为one v rest分类问题,即一个类别与其他类别进行划分。
#开始训练
classifier.fit(x_train,y_train.ravel())
#调用ravel()函数将矩阵转变成一维数组
#(ravel()函数与flatten()的区别)
# 两者所要实现的功能是一致的(将多维数组降为一维),
# 两者的区别在于返回拷贝(copy)还是返回视图(view),
# numpy.flatten() 返回一份拷贝,对拷贝所做的修改不会影响(reflects)原始矩阵,
# 而numpy.ravel()返回的是视图(view),会影响(reflects)原始矩阵。
def show_accuracy(y_hat,y_train,str):
pass
#(4)计算svm分类器的准确率
print("SVM-输出训练集的准确率为:",classifier.score(x_train,y_train))
y_hat=classifier.predict(x_train)
show_accuracy(y_hat,y_train,'训练集')
print("SVM-输出测试集的准确率为:",classifier.score(x_test,y_test))
y_hat=classifier.predict(x_test)
show_accuracy(y_hat,y_test,'测试集')
# (5)绘制图像
# 1.确定坐标轴范围,x,y轴分别表示两个特征
x1_min, x1_max = x[:, 0].min(), x[:, 0].max() # 第0列的范围 x[:, 0] ":"表示所有行,0表示第1列
x2_min, x2_max = x[:, 1].min(), x[:, 1].max() # 第1列的范围 x[:, 0] ":"表示所有行,1表示第2列
x1, x2 = np.mgrid[x1_min:x1_max:200j, x2_min:x2_max:200j] # 生成网格采样点(用meshgrid函数生成两个网格矩阵X1和X2)
grid_test = np.stack((x1.flat, x2.flat), axis=1)
# 测试点,再通过stack()函数,axis=1,生成测试点
# .flat 将矩阵转变成一维数组 (与ravel()的区别:flatten:返回的是拷贝 grid_hat = classifier.predict(grid_test) # 预测分类值
grid_hat = grid_hat.reshape(x1.shape) # 使之与输入的形状相同
# 2.指定默认字体
mpl.rcParams['font.sans-serif'] = [u'SimHei']
mpl.rcParams['axes.unicode_minus'] = False
# 3.绘制
cm_light = mpl.colors.ListedColormap(['#A0FFA0', '#FFA0A0', '#A0A0FF'])
cm_dark = mpl.colors.ListedColormap(['g', 'r', 'b'])
alpha=0.8
# 预测值的显示
plt.pcolormesh(x1, x2, grid_hat, shading='auto', cmap=cm_light)
plt.plot(x[:, 0], x[:, 1], 'o', alpha=alpha, color='red', markeredgecolor='k')
# 圈中测试集样本
plt.scatter(x_test[:, 0], x_test[:, 1], s=120, facecolors='none', zorder=10)
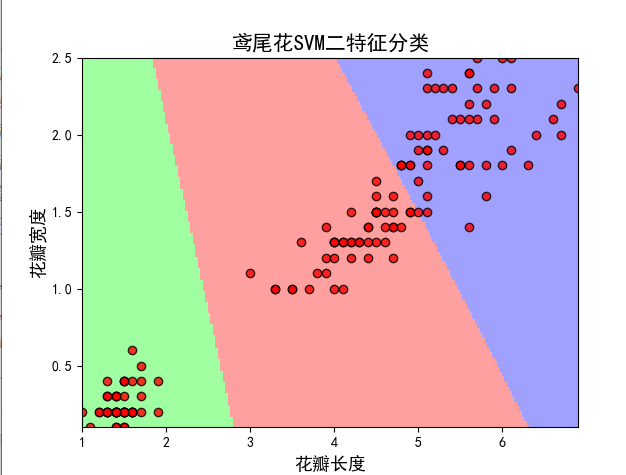
plt.xlabel(u'花瓣长度', fontsize=13)
plt.ylabel(u'花瓣宽度', fontsize=13)
plt.xlim(x1_min, x1_max)
plt.ylim(x2_min, x2_max)
plt.title(u'鸢尾花SVM二特征分类', fontsize=15)
plt.show()
前面两列:

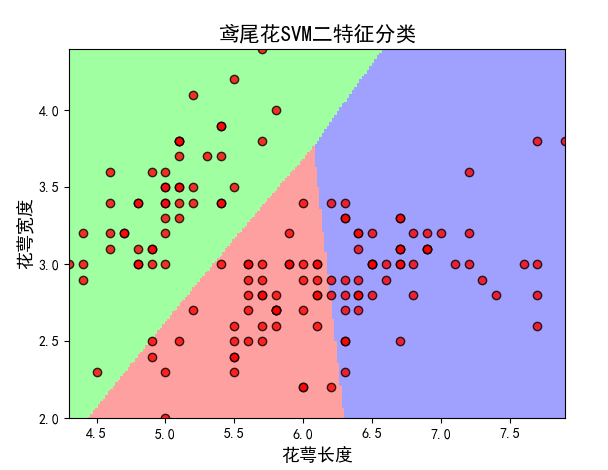
后面两列:

Python+SVM的更多相关文章
- 基于Python使用SVM识别简单的字符验证码的完整代码开源分享
关键字:Python,SVM,字符验证码,机器学习,验证码识别 1 概述 基于Python使用SVM识别简单的验证字符串的完整代码开源分享. 因为目前有了更厉害的新技术来解决这类问题了,但是本文作 ...
- 基于SVM的python简单实现验证码识别
验证码识别是一个适合入门机器学习的项目,之前用knn 做过一个很简单的,这次用svm来实现.svm直接用了开源的库libsvm.验证码选的比较简单,代码也写得略乱,大家看看就好. 1. 爬取验证码图片 ...
- 字符型图片验证码识别完整过程及Python实现
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- LibSVM for Python 使用
经历手写SVM的惨烈教训(还是太年轻)之后,我决定使用工具箱/第三方库 Python libsvm的GitHub仓库 LibSVM是开源的SVM实现,支持C, C++, Java,Python , R ...
- python之基于libsvm识别数字验证码
1. 参考 字符型图片验证码识别完整过程及Python实现 2.图片预处理和手动分类 (1)分析图片 from PIL import Image img = Image.open('nums/ttt. ...
- 完整的验证码识别流程基于svm(若是想提升,可优化)
字符型图片验证码识别完整过程及Python实现 首先很感觉这篇文章的作者,将这篇文章写的这么好.我呢,也是拿来学习,觉得太好,所以忍不住就进行了转载. 因为我个人现在手上也有个验证码识别的项目,只是难 ...
- python 验证码 高阶验证
python 验证码 高阶验证 标签: 验证码python 2016-08-19 15:07 1267人阅读 评论(1) 收藏 举报 分类: 其他(33) 目录(?)[+] 字符型图片验证 ...
- 字符识别Python实现 图片验证码识别
字符型图片验证码识别完整过程及Python实现 1 摘要 验证码是目前互联网上非常常见也是非常重要的一个事物,充当着很多系统的 防火墙 功能,但是随时OCR技术的发展,验证码暴露出来的安全问题也越 ...
- python的一些配置
昨天西邮的学友让我看一段python svm的输入文件格式,但是我打开很久不用的pycharm后发觉python包早已过时.于是搜了一下教程,看来python也得同时补习了 另外,机器学习还需要装很多 ...
- libsvm的安装,数据格式,常见错误,grid.py参数选择,c-SVC过程,libsvm参数解释,svm训练数据,libsvm的使用详解,SVM核函数的选择
直接conda install libsvm安装的不完整,缺几个.py文件. 第一种安装方法: 下载:http://www.csie.ntu.edu.tw/~cjlin/cgi-bin/libsvm. ...
随机推荐
- oracle 19c rpm 个性化配置安装
简单来说就是: 1.安装preinstall : oracle-database-preinstall-19c-1.0-1.el7.x86_64.rpm 2.安装 ee : oracl ...
- 解决连接MySQL,报错10061,系统错误5
mysql登录不上去,报错10061,百度后得,mysql服务未启动.. 方法一.选择dos窗口命令行打开mysql 输入代码 net start mysql 报错,如图所示.系统错误 5 解决办法: ...
- 【转载】Linux虚拟化KVM-Qemu分析(八)之virtio初探
原文信息 作者:LoyenWang 出处:https://www.cnblogs.com/LoyenWang/ 公众号:LoyenWang 版权:本文版权归作者和博客园共有 转载:欢迎转载,但未经作者 ...
- 用 perfcollect 洞察 Linux 上.NET程序 CPU爆高
一:背景 1. 讲故事 如果要分析 Linux上的 .NET程序 CPU 爆高,按以往的个性我肯定是抓个 dump 下来做事后分析,这种分析模式虽然不重但也不轻,还需要一定的底层知识,那有没有傻瓜式的 ...
- 订单逆向履约系统的建模与 PaaS 化落地实践
导读 本文重点介绍了京东零售电商业务在订单逆向履约上面的最佳技术实践,京东零售快退平台承接了零售几乎所有售前逆向拦截和退款业务,并在长期的业务和技术探索中沉淀了丰富的业务场景设计方案.架构设计经验,既 ...
- 2023-07-20:假设一共有M个车库,编号1~M,时间点从早到晚是从1~T, 一共有N个记录,每一条记录如下{a, b, c}, 表示一辆车在b时间点进入a车库,在c时间点从a车库出去, 一共有K
2023-07-20:假设一共有M个车库,编号1 ~ M,时间点从早到晚是从1 ~ T, 一共有N个记录,每一条记录如下{a, b, c}, 表示一辆车在b时间点进入a车库,在c时间点从a车库出去, ...
- SAP ABAP 使用GENIOS求解线性规划问题的简单例子
主要内容来自Operations Research & ABAP ,结合我遇到的需求,做了一些修改. 需求:有BOX1和BOX2两种箱子,分别能包装不同数量的A物料和B物料,给出若干数量的A, ...
- EntityCleanFramework
EF几乎是按照领域的概念诞生,它可以和Clean结合(ECF是我新想出的名字).ECF 是为了统一业务架构开发方式,也可以说成在 微服务架构 中服务的通用开发方式.当有了统一开发方式后,协作将更上一层 ...
- Java源代码是如何编译,加载到内存中的?
1.前言 相信许多开发同学看过<深入理解java虚拟机>,也阅读过java虚拟机规范,书籍和文档给人的感觉不够直观,本文从一个简单的例子来看看jvm是如何工作的吧. 本文所有操作均在mac ...
- SpringMVC配置web.xml文件详解(列举常用的配置)
常用的web.xml的配置 1.Spring 框架解决字符串编码问题:过滤器 CharacterEncodingFilter(filter-name) 2.在web.xml配置监听器ContextLo ...