1 小时 SQL 极速入门(一)
前几天,我在论坛溜达。看到一个人发帖说
做了6年的企业级开发,总是被互联网行业的人认为没技术含量,不就是CRUD么
先解释下 CRUD 是什么。CRUD 就是我们常说的增删改查(Create,Retrieve,Update,Delete)
其实,对这个问题,我也思考过。我们所有的业务流程,最终都会抽象出数据模型,保存到数据库中。把业务之间的联系抽象成数据库中表与表,字段与字段之间的联系。实际上,企业的各种系统,在技术层面上确实是在 CRUD。
不过话说回来了,互联网的系统不是 CRUD 吗?只不过 CRUD 的姿势不同罢了,互联网可能是面对高并发的 CRUD, 我们是面对的是复杂业务流程的 CRUD。这些业务逻辑还需要一定的行业积淀才能捋清楚。所以在企业级开发上业务和技术基本是五五开,业务比重甚至要大于技术。
所以,今天我们就花很短的时间,来学学简单的 SQL.了解下 CRUD 的姿势。
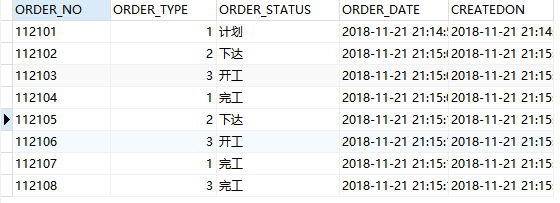
假如我们有下面一个订单表 ORDER_HEADER,不要在意表里的数据,为了方便说明,瞎填的。
查询
查询是我们平日使用最多的,下面着重说一下:
查询使用 SELECT 关键字,基本结构如下
SELECT <列名> FROM <表名> WHERE <条件>
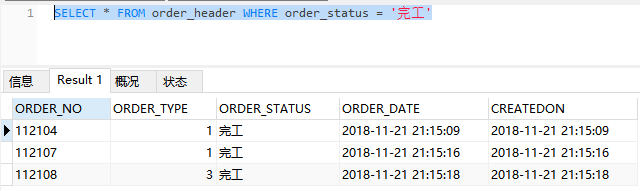
假如我们想查找所有已经完工的订单信息,那么 SQL 怎么写呢?
SELECT * FROM order_header WHERE order_status = '完工'
执行后会看到我们需要的结果
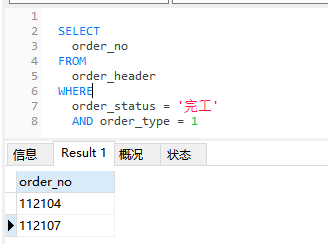
SELECT * 代表查询所有列,一般我们会关注我们需要的字段,比如我们要找到订单类型为 1 的并且完工的订单号,我们可以这么写
SELECT order_no FROM order_header WHERE order_status = '完工' AND order_type = 1
我们可以看到只有下面两个符合条件的订单号被选中。在写 SQL 中我们要尽量避免 SELECT * ,我们需要哪个字段就取哪个字段,可以节省 SQL 查询的时间。
如果要查询订单类型为 1 的或者处于下达状态的订单,SQL 怎么写呢?
SELECT order_no FROM order_header WHERE order_type = 1 OR order_status = '下达'
如果要查找开工,下达和完工状态的订单,我们可以用 IN 关键字
SELECT
order_no,
order_type,
order_status
FROM
order_header
WHERE
order_status IN ( '开工', '完工', '下达' )
除了 IN 我们可以使用 LIKE 进行模糊查询,比如我们要查询订单状态中包含 “工” 的所有订单
SELECT order_no FROM order_header WHERE order_status LIKE '%工%'
这里的 "%" 表示通配符,"%工"表示以工结尾的所有匹配,"工%"表示以工开头的所有匹配。
此外,我们可以用 NOT IN , NOT LIKE 来取相反的逻辑。
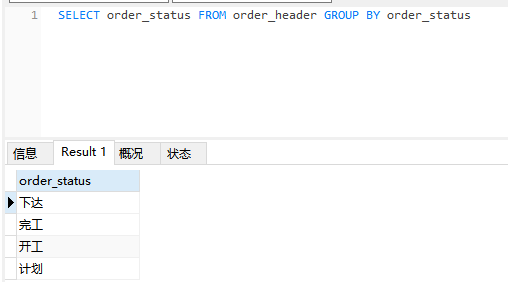
通过 GROUP BY 可以进行分组,比如我们按照订单状态来分组,就可以很方便的查看当前有几种状态的订单
SELECT order_status FROM order_header GROUP BY order_status
结果如下图
如果我们想看到每个分组中有多少订单,那个我们可以使用 COUNT() 函数
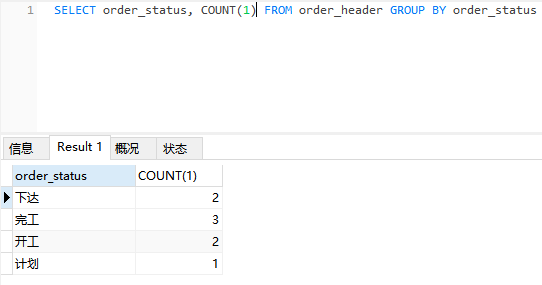
SELECT order_status, COUNT(1) FROM order_header GROUP BY order_status
结果如下图,可以看到每个分组中订单的数量。除了COUNT(),还有 MAX(),MIN(),SUM()等函数
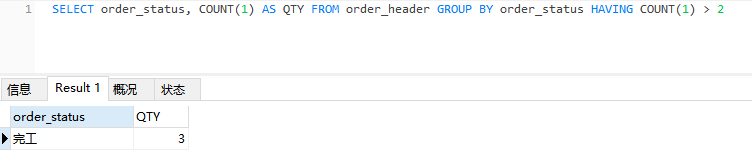
如果我们只想看到数量大于 2 的分组,该怎么写?
SELECT order_status, COUNT(1) FROM order_header GROUP BY order_status HAVING COUNT(1) > 2
可以看到,只有数量大于2的分组被查到了。
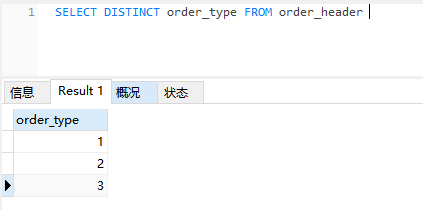
如果仅仅想去重,比如想知道总共有几种订单类型,那么我们只需要对此列用 DISTINCT 即可。
SELECT DISTINCT order_type FROM order_header
结果中的订单类型列已经被去重了。
CASE WHEN ,有时我们会需要简单的判断逻辑,就可以用 CASE WHEN 了。比如我们想让 订单类型为1 的表示生产订单,订单类型为2 的表示更改订单,订单类型为3 的表示废弃订单。那么我们可以这么写
SELECT
order_no,
order_type,
order_status,
CASE
WHEN order_type = 1 THEN '生产订单'
WHEN order_type = 2 THEN '更改订单'
WHEN order_type = 3 THEN '废弃订单'
ELSE '未知类型'
END AS type_desc
FROM
order_header
结果如下图

子查询,有时候我们需要从一个结果集中再次查找,就会用到子查询。比如下面这样写
SELECT
order_no,
type_desc
FROM
(
SELECT
order_no,
order_type,
order_status,
CASE
WHEN order_type = 1 THEN '生产订单'
WHEN order_type = 2 THEN '更改订单'
WHEN order_type = 3 THEN '废弃订单'
ELSE '未知类型'
END AS type_desc
FROM
order_header
) t
下节课我们说一下 连接查询和常用到的分析函数,在企业中,单表查询情况是很少的,要关联查询。
插入数据
插入数据我们使用 INSERT 语句
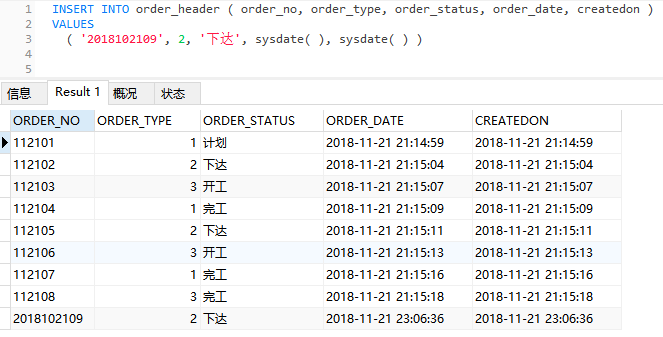
INSERT INTO order_header ( order_no, order_type, order_status, order_date, createdon )
VALUES
( '2018102109', 2, '下达', sysdate( ), sysdate( ) )
看到,最下面就是我们新插入的一行
更新数据
更新数据使用 UPDATE 语句,我们更新一下刚才插入的数据的订单号
UPDATE order_header SET order_no = '112109' WHERE order_no = '2018102109'
我们把 订单号为'2018102109'的一行数据更新为了'112109',在update时一定要写好 WHERE 条件,如果没有 WHERE 条件,会更新表中所有数据。
删除数据
我们删除刚才加入的一条数据
DELETE FROM order_header WHERE order_no = '112109'
运行后,订单号为'112109'的订单就被删除了,DELETE 时同样要写好 WHERE 条件,如果没有 WHERE 条件,会删除表中所有数据。
下节重点说说 多表连接,常用分析函数。不要走开哦。
1 小时 SQL 极速入门(一)的更多相关文章
- 1 小时 SQL 极速入门(三)——分析函数
1 小时 SQL 极速入门 前面两篇我们从 SQL 的最基础语法讲起,到表联结多表查询. 大家可以点击链接查看 1 小时 SQL 极速入门(一) 1 小时 SQL 极速入门(二) 今天我们讲一些在做报 ...
- 1 小时 SQL 极速入门(二)
上篇我们说了 SQL 的基本语法,掌握了这些基本语法后,我们可以对单表进行查询及计算分析.但是一个大的系统,往往会有数十上百张表,而业务关系又错综复杂.我们要查的数据往往在好几张表中,而要从多张表中来 ...
- 每篇半小时1天入门MongoDB——2.MongoDB环境变量配置和Shell操作
上一篇:每篇半小时1天入门MongoDB——1.MongoDB介绍和安装 配置环境变量 Win10系统为例 右键单击“此电脑”——属性——高级系统设置——高级——环境变量,添加C:\Program F ...
- 《Python黑客编程之极速入门》正式开课
玄魂 玄魂工作室 今天 之前开启了一个<Python黑客编程>的系列,后来中断了,内容当时设置的比较宽,不太适合入门.现在将其拆分成两个系列<Python黑客编程之极速入门>和 ...
- SQL查询入门(下篇)
SQL查询入门(下篇) 文章转自:http://www.cnblogs.com/CareySon/archive/2011/05/18/2049727.html 引言 在前两篇文章中,对于单表查询 ...
- Python 极速入门指南
前言 转载于本人博客. 面向有编程经验者的极速入门指南. 大部分内容简化于 W3School,翻译不一定准确,因此标注了英文. 包括代码一共两万字符左右,预计阅读时间一小时. 目前我的博客长文显示效果 ...
- 1.SQL语句入门
--SQL语句入门-- --1.sql语言是解释语言 --2.它不区分大小写 --3.没有"",所有字符或者字符串都使用''包含 --4.sql里面也有类似于c#的运算符 -- 算 ...
- SQL 存储过程入门(事务)(四)
SQL 存储过程入门(事务)(四) 本篇我们来讲一下事务处理技术. 为什么要使用事务呢,事务有什么用呢,举个例子. 假设我们现在有个业务,当做成功某件事情的时候要向2张表中插入数据,A表,B表,我 ...
- sql xml 入门
/*sql xml 入门: --by jinjazz --http://blog.csdn.net/jinjazz 1.xml: 能认识元素.属性和值 ...
随机推荐
- psutil(搬运,一个月后稍后修改)
psutil是一个跨平台库,能够轻松实现获取系统运行的进程和系统利用率(包括CPU.内存.磁盘.网络等)信息.它主要用来做系统监控,性能分析,进程管理 安装:pip install psutil 1. ...
- 强大而灵活的的Html解析器——Html Agility Pack
一.概述 Html Agility Pack 简称HAP,是一个强大而灵活的解析Html DOM的.Net类库. 二.官方链接 官网:http://html-agility-pack.net/ NuG ...
- 用Python写一个zip文件的密码破解程序
最近在读<python绝技:运用python成为顶级黑客>一书,文中有如何运用Python中zipfile自带的方法破解zip文件.短短的十几行代码就将一个程序实现了.下面给出书中所用的代 ...
- python批量重命名【截取文件名前六个字符 】
#!/usr/bin/python # -*- coding: UTF-8 -*- import os, sys # 打开文件 path = "/home/landv/Desktop/l/& ...
- C#学习-显式接口
显式的接口实现解决了命名冲突问题. 在使用显式的接口实现方式时,需要注意以下几个问题. 若显式实现接口,方法不能使用任何访问修饰符,显式实现的成员都默认为私有: 现式实现的成员默认是私有的,所以这些成 ...
- MonkeyFest2018Guangzhou
MonkeyFest 是一个一年一度由全球Microsoft Xamarin开发者发起的全球性社区活动,主旨推广在云计算.人工智能.大数据.移动开发等技术. 跨平台技术移动开发(卢建晖) .NET C ...
- 推荐学习git
龙恩博客http://www.cnblogs.com/tugenhua0707/p/4050072.html#!comments git命令大全https://www.jqhtml.com/8235. ...
- 从外面更新unity需要用的题库
unity中必须要有Plugins文件夹以及dll文件官方dll文件下载链接: https://archive.codeplex.com/?p=exceldatareader using System ...
- Tomcat映射路径
打开tomcat安装包,在config目录下修改server.xml文件: 在<Host>标签中添加: <Context path="" docBase=&quo ...
- scala_2
一.scala类 . 在java中程序的入口是main方法->定义在class中 在scala中程序的入口是main方法->定义在object对象中 案例一: class People { ...