per-CPU变量
为什么需要per-CPU变量
假设系统中有4个cpu, 同时有一个变量在各个CPU之间是共享的,每个cpu都有访问该变量的权限。
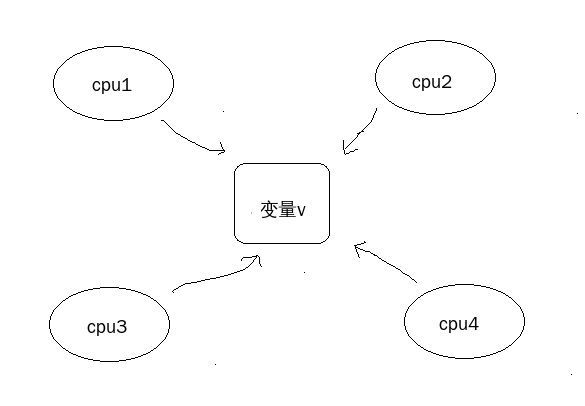
当cpu1在改变变量v的值的时候,cpu2也需要改变变量v的值。这时候就会导致变量v的值不正确。这时候机智的你就会说,在cpu1访问变量v的时候可以使用原子操作加锁,cpu2访问变量v的时候需要等待。可是机智的是否考虑过加锁对性能的影响,原子操作对cpu是极耗cpu的。
再考虑一种情况,现在高速的cpu都带有高速缓冲cache。它介于cpu和主存之间,主要作用是加快cpu的访问速度。因为主存的访问速度相比cpu读写比较慢,在之间引入cache之后,当CPU调用大量数据时,就可避开内存直接从缓存中调用,从而加快读取速度。
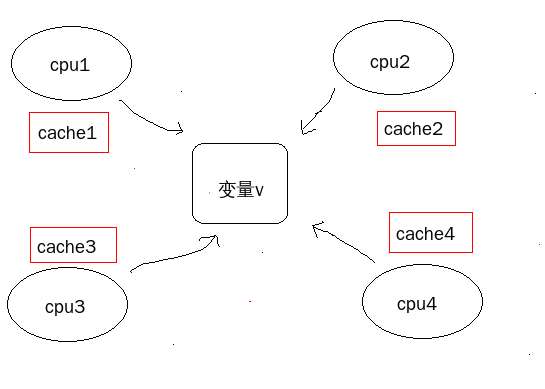
比如cpu1对变量v操作子后,变量v的值就发生了变化。而cpu2, cpu3, cpu4的cache中的值还是以前的值,所以这时候就需要将cpu2, cpu3, cpu4的cache中的值变为无效的,当cpu2读取变量v的时候就需要从内存中读取v。所以当某一个cpu对共享数据v做操作后,比较对其余的cache做无效操作,这也是对性能有所损耗的。
所以,就引入了per-cpu变量。
什么是per-CPU变量
per-CPU变量是linux系统一个非常有趣的特性,它为系统中的每个处理器都分配了该变量的副本。这样做的好处是,在多处理器系统中,当处理器操作属于它的变量副本时,不需要考虑与其他处理器的竞争的问题,同时该副本还可以充分利用处理器本地的硬件缓冲cache来提供访问速度。
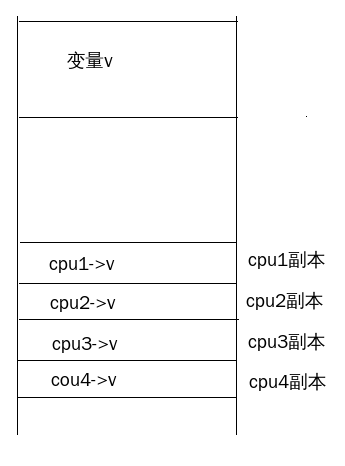
per-CPU按照存储变量的空间来源分为静态per-CPU变量和动态per-CPU变量,前者的存储空间是在代码编译时静态分配的,而后者的存储空间则是在代码的执行期间动态分配的。
静态per-CPU变量声明和定义
声明DECLARE_PER_CPU宏:
<include/linux/percpu-defs.h>
----------------------------------------------------------------
#define DECLARE_PER_CPU(type, name) \
DECLARE_PER_CPU_SECTION(type, name, "")
#define DECLARE_PER_CPU_SECTION(type, name, sec) \
extern __PCPU_ATTRS(sec) __typeof__(type) name
#define __PCPU_ATTRS(sec) \
__percpu __attribute__((section(PER_CPU_BASE_SECTION sec))) \
PER_CPU_ATTRIBUTES
<include/asm-generic/percpu.h>
-----------------------------------------------------
#ifndef PER_CPU_BASE_SECTION
#ifdef CONFIG_SMP
#define PER_CPU_BASE_SECTION ".data..percpu"
#else
#define PER_CPU_BASE_SECTION ".data"
#endif
#endif
对上的宏定义DECLARE_PER_CPU使用例子: DECLARE_PER_CPU(int, val)来详细说明。
DECLARE_PER_CPUT(int, val)
-> DECLARE_PER_CPU_SECTION(int, val, "")
-> extern __PCPU_ATTRS("") __typeof__(int) val
-> extern __percpu __attribute__((section(".data..percpu"))) int val
从上面的分析可以看出,该宏在源代码中声明了__percpu int val变量,该变量放在一个名为”.data..percpu”的section中。
定义DEFINE_PER_CPU宏:
<include/linux/percpu-defs.h>
----------------------------------------------------------------
#define DEFINE_PER_CPU(type, name) \
DEFINE_PER_CPU_SECTION(type, name, "")
#define DEFINE_PER_CPU_SECTION(type, name, sec) \
__PCPU_ATTRS(sec) PER_CPU_DEF_ATTRIBUTES \
__typeof__(type) name
#ifndef PER_CPU_DEF_ATTRIBUTES
#define PER_CPU_DEF_ATTRIBUTES
#endif
| 声明和定义 | 解释 |
|---|---|
| DECALRE_PER_CPU(type, name)/DEFINE_PER_CPU(type, name) | 普通的per-CPU声明和定义 |
| DECLARE_PER_CPU_FIRST(type, name)/DEFINE_PER_CPU_FIRST(type, name) | 该per-CPU变量会在整个serction的最前面,所谓的first |
| DECLARE_PER_CPU_SHARED_ALIGNED(type, name)/DEFINE_PER_CPU_SHARED_ALIGNED(type, name) | 该per-CPU在SMP系统下会对齐到cache line,在UP系统下不需要对齐 |
| DECLARE_PER_CPU_ALIGNED(type, name)/DEFINE_PER_CPU_ALIGNED(type, name) | 在SMP和UP系统都对齐到cache line |
| DECLARE_PER_CPU_PAGE_ALIGNED(type, name)/DEFINE_PER_CPU_PAGE_ALIGNED(type, name) | 该per-CPU变量必须页对齐 |
| DECLARE_PER_CPU_READ_MOSTLY(type, name)/DEFINE_PER_CPU_READ_MOSTLY(type, name) | 该per-CPU变量必须是read mostly |
静态per-CPU变量的链接脚本
在上一节per-CPU变量的声明和定义中,可以看到最后的变量都是存在一个”.data..percpu”段中。
. = ALIGN((1 << 12));
.data..percpu : AT(ADDR(.data..percpu) - 0)
{
__per_cpu_load = .;
__per_cpu_start = .;
*(.data..percpu..first) . = ALIGN((1 << 12));
*(.data..percpu..page_aligned) . = ALIGN(64);
*(.data..percpu..read_mostly) . = ALIGN(64);
*(.data..percpu)
*(.data..percpu..shared_aligned)
__per_cpu_end = .;
}
可见,内核在编译链接的时候会把所有静态定义的per-CPU变量统一放到”.data..percpu”section中。链接器生成__per_cpu_start和__per_cpu_end两个变量表示该section的起始和结束地址。
动态分配per-CPU变量
- 分配函数
#define alloc_percpu(type) \
(typeof(type) __percpu *)__alloc_percpu(sizeof(type), \
__alignof__(type))
根据类型type,分配per-CPU变量
- 释放函数
void free_percpu(void __percpu *ptr)
释放ptr所指向的per-CPU变量。
使用静态per-CPU变量
因为per-CPU不能像一般的变量那样访问,必须使用内核提供的函数:
#define get_cpu_var(var) \
(*({ \
preempt_disable(); \
this_cpu_ptr(&var); \
}))
#define put_cpu_var(var) \
do { \
(void)&(var); \
preempt_enable(); \
} while (0)
机智的你可能会问,为什么还需要关闭抢占,因为对于per-CPU来说已经是单处理器了。但是机智的你没有想到的是,在cpu访问per-CPU的时候,突然系统发生了一次紧急抢占,这时候cpu还在处理per-CPU变量,一旦被抢占了cpu资源,可能当前进程会换出处理器。所以关闭抢走还是必要的。
如果需要访问其他处理器的副本,可以使用函数per_cpu(var, cpu)
#define per_cpu(var, cpu) (*per_cpu_ptr(&(var), cpu))
使用动态per-CPU变量
#define get_cpu_ptr(var) \
({ \
preempt_disable(); \
this_cpu_ptr(var); \
})
#define put_cpu_ptr(var) \
do { \
(void)(var); \
preempt_enable(); \
} while (0)
#define per_cpu_ptr(ptr, cpu) ({ (void)(cpu); VERIFY_PERCPU_PTR(ptr); })
以上get_cpu_ptr和put_cpu_ptr是在有抢占的情况下,需要关闭抢占使用。
而per_cpu_ptr(ptr, cpu)是根据per cpu变量的地址和cpu number,返回指定CPU number上该per cpu变量的地址。
per-CPU变量的更多相关文章
- linux内核中的每cpu变量
一.linux中的每cpu变量 看linux内核代码的时候,会发现大量的per_cpu(name, cpu),get_cpu_var(name)等出现cpu字眼的语句.从语句的意思可以看出是要使用与当 ...
- 每CPU变量
最好的同步技术是把设计不需要同步的临界资源放在首位,这是一种思维方法,因为每一种显式的同步原语都有不容忽视的性能开销.最简单也是最重要的同步技术包括把内核变量或数据结构声明为每CPU变量(per-cp ...
- linux内核同步之每CPU变量、原子操作、内存屏障、自旋锁【转】
转自:http://blog.csdn.net/goodluckwhh/article/details/9005585 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 一每 ...
- linux:cpu 每-CPU 的变量
每-CPU 的变量 每-CPU 变量是一个有趣的 2.6 内核的特性. 当你创建一个每-CPU变量, 系统中每个处理器获得它自己的这个变量拷贝. 这个可能象一个想做的奇怪的事情, 但是它有自己的优点. ...
- linux 每-CPU 的变量
每-CPU 变量是一个有趣的 2.6 内核的特性. 当你创建一个每-CPU 变量, 系统中每个处理 器获得它自己的这个变量拷贝. 这个可能象一个想做的奇怪的事情, 但是它有自己的优点. 存取每-CPU ...
- Intel 80x86 Linux Kernel Interrupt(中断)、Interrupt Priority、Interrupt nesting、Prohibit Things Whthin CPU In The Interrupt Off State
目录 . 引言 . Linux 中断的概念 . 中断处理流程 . Linux 中断相关的源代码分析 . Linux 硬件中断 . Linux 软中断 . 中断优先级 . CPU在关中断状态下编程要注意 ...
- Linux内核同步机制之(二):Per-CPU变量
转自:http://www.wowotech.net/linux_kenrel/per-cpu.html 一.源由:为何引入Per-CPU变量? 1.lock bus带来的性能问题 在ARM平台上,A ...
- xv6中存储cpu和进程信息的技巧
xv6是一个支持多处理器的Unix-like操作系统, 近日阅读源码时发现xv6在记录当前CPU和进程状态时非常tricky 首先,上代码: extern struct cpu cpus[NCPU]; ...
- 激活第一个CPU
回到start_kernel,559行,boot_cpu_init函数,跟start_kernel位于同一文件: 494static void __init boot_cpu_init(void) 4 ...
随机推荐
- dedecms搜索模板,使用{dede:list}标签调用自定义字段不显示(空白)
前几天使用织梦做一个搜索功能,正常使用{dede:list}调用自定义内容模型中的自定义字段,代码如下:(自定义字段的调用可以参考:http://www.dede58.com/a/dedejq/523 ...
- laravel的消息队列剖析
laravel的消息队列剖析 这篇来自于看到朋友转的58沈剑的一篇文章:1分钟实现"延迟消息"功能 在实际工作中也不止遇见过一次这个问题,我在想着以前是怎么处理的呢?我记得当初在上 ...
- Service Fabric部署笔记
使用 x509 证书时报错 Thumbprint contains invalid characters 原因是在 windows 证书管理器复制指纹的时候,在指纹字符串开头有不显示的字符,粘贴到 j ...
- Linux设备驱动之IIO子系统——IIO框架及IIO数据结构
由于需要对ADC进行驱动设计,因此学习了一下Linux驱动的IIO子系统.本文翻译自<Linux Device Drivers Development >--John Madieu,本人水 ...
- Spring Boot 路由
多路由指向同一个方法 @GetMapping(value = {"/login","/index"}) 访问http://127.0.0.1/index 和 h ...
- 【java 多线程】多线程并发同步问题及解决方法
一.线程并发同步概念 线程同步其核心就在于一个“同”.所谓“同”就是协同.协助.配合,“同步”就是协同步调昨,也就是按照预定的先后顺序进行运行,即“你先,我等, 你做完,我再做”. 线程同步,就是当线 ...
- Linux 进程管理工具 supervisord 安装及使用
Supervisor是用Python实现的一款非常实用的进程管理工具 1.安装过程非常简单 安装python 安装meld3-0.6.8.tar.gz 安装supervisor-3.0a12.tar. ...
- ASP.NET MVC ETag & Cache等优化方法
背景 最近有一个项目是用SmartAdmin + Jquery + EasyUI 一个ASP.NET MVC5的项目,一直存在一个性能问题,加载速度比较慢,第一次加载需要(在没有cache的情况下)需 ...
- springboot2.0.3源码篇 - 自动配置的实现,发现也不是那么复杂
前言 开心一刻 女儿: “妈妈,你这么漂亮,当年怎么嫁给了爸爸呢?” 妈妈: “当年你爸不是穷嘛!‘ 女儿: “穷你还嫁给他!” 妈妈: “那时候刚刚毕业参加工作,领导对我说,他是我的扶贫对象,我年轻 ...
- .Net语言 APP开发平台——Smobiler学习日志:在手机应用中开发蛛网表格
最前面的话:Smobiler是一个在VS环境中使用.Net语言来开发APP的开发平台,也许比Xamarin更方便 样式一 一.目标样式 我们要实现上图中的效果,需要如下的操作: 1.从工具栏上的”Sm ...