FastDfs集群docker化部署
初识分布式文件系统FastDFS…
1.分布式与集群的区别
区别:集群是个物理形态,分布式是个工作方式。只要是一堆机器,就可以叫集群,他们是不是一起协作着干活,这个谁也不知道;一个程序或系统,只要运行在不同的机器上,就可以叫分布式,一般系统现在都是前后端分离,C/S架构、B/S架构,一般服务端部署在内部服务器,而客户端分布在各个用户的机器好比手机、PC机等,这样的系统也是分布式系统。集群一般是物理集中、统一管理的,而分布式系统则不强调这一点。
联系:将一个应用程序拆分成多个功能模块或节点(分布式)后,可以对每一个功能模块或节点用集群的方式来部署,从而达到提升应用程序的整体性能以及高可用的优点。
1.1. 分布式概述
可以将分布式理解为,将某一个应用程序,拆分成多个模块来部署,各个模块负责不同的功能;分布式的优点是细化了应用程序的功能模块,同时也减轻了一个完整的应用程序部署在一台服务器上的负担,用了分布式拆分后,就相当于把一个应用程序的多个功能分配到多台服务器上去处理了。
1.2.集群概述
集群的意思就是将一个应用程序,部署到多台服务器上面,然后在这些服务器的前面通过负载均衡服务器来择优选择哪一台服务器去执行;集群的优点就是当其中的一个服务器宕机了,其他服务器可以接上继续工作;将应用程序部署在多台服务器时,也提供了数据的吞吐量。
2.FastDFS简介
FastDFS是由淘宝的余庆先生所开发,是一个轻量级、高性能的开源分布式文件系统,用纯C语言开发,包括文件存储、文件同步、文件访问(上传、下载)、存取负载均衡、在线扩容、相同内容只存储一份等功能,适合有大容量存储需求的应用或系统。做分布式系统开发时,其中要解决的一个问题就是图片、音视频、文件共享的问题,分布式文件系统正好可以解决这个需求。同类的分布式文件系统有谷歌的GFS、HDFS(Hadoop)、TFS(淘宝)等,特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务。
FastDFS 系统有三个角色:跟踪服务器(Tracker Server)、存储服务器(Storage Server)和客户端(Client)。
Tracker Server:跟踪服务器,主要做调度工作,起到均衡的作用;负责管理所有的 storage server和 group,每个 storage 在启动后会连接 Tracker,告知自己所属 group 等信息,并保持周期性心跳。
Storage Server:存储服务器,主要提供容量和备份服务;以 group 为单位,每个 group 内可以有多台 storage server,数据互为备份。
Client:客户端,上传下载数据的服务器,也就是我们自己的项目所部署在的服务器。

2.1. FastDFS的存储策略
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷可以由一台或多台存储服务器组成,一个卷下的存储服务器中的文件都是相同的,卷中的多台存储服务器起到了冗余备份和负载均衡的作用。
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
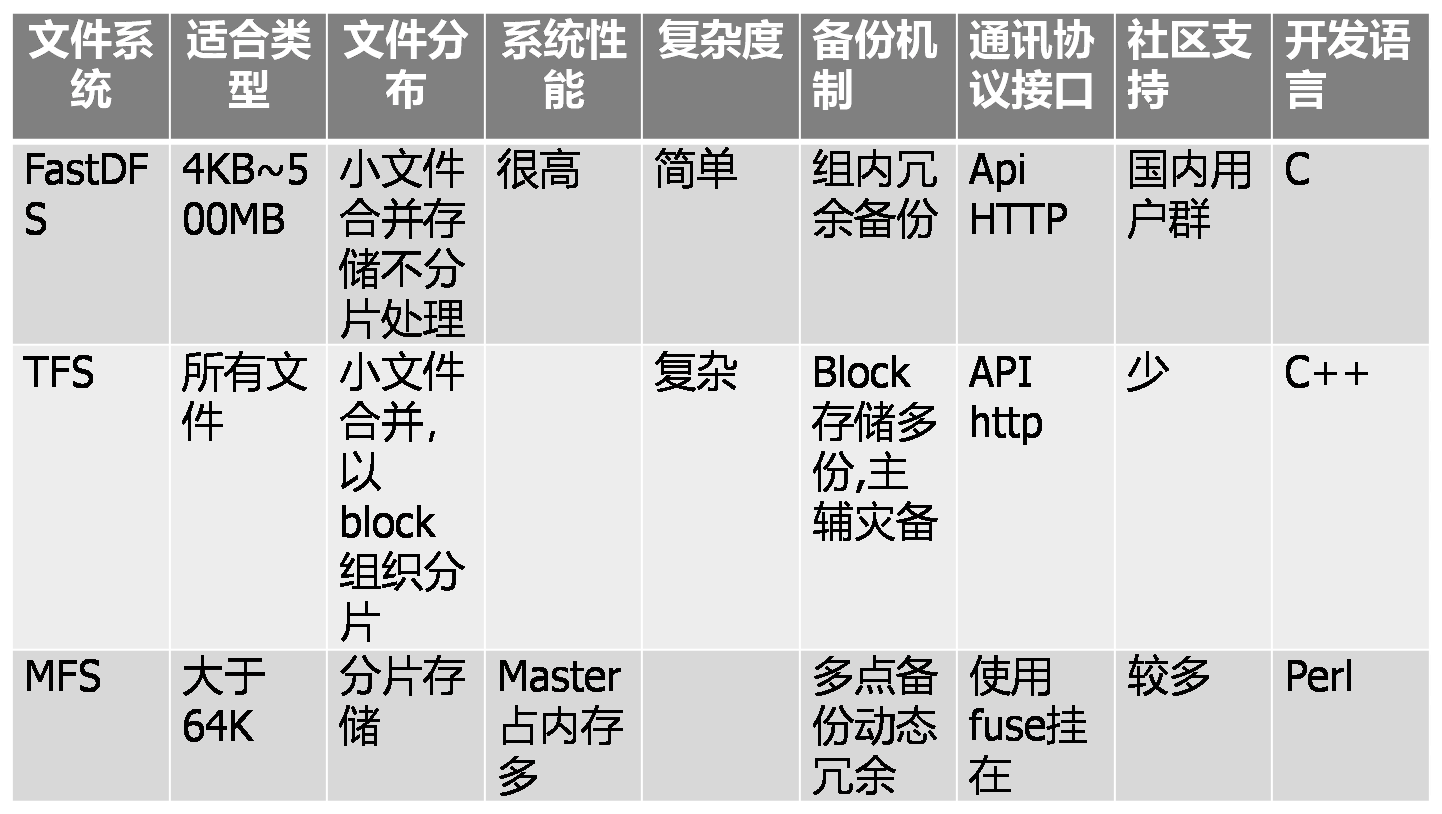
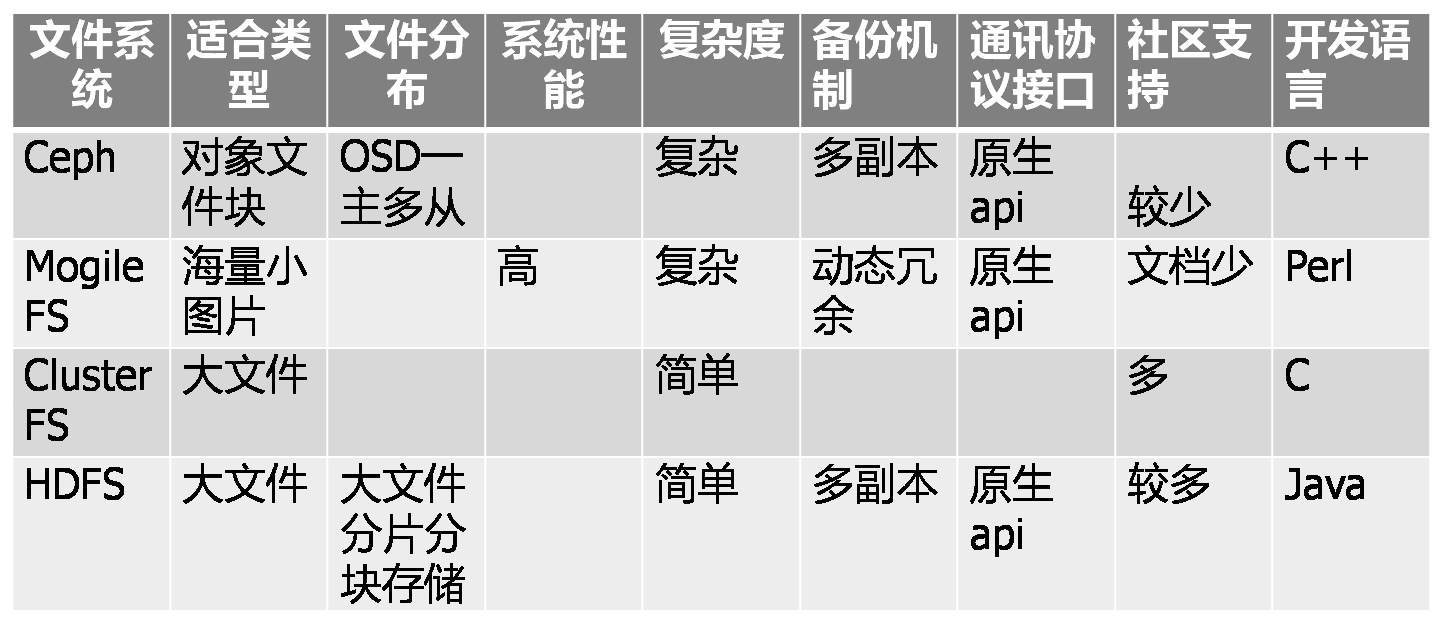
2.2. FastDFS与其他文件系统的对比
2.2.1. 与单机文件系统的对比

2.2.2. 与其他文件系统的对比
2.3. FastDFS文件上传流程
FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
Storage Server会定期的向Tracker Server发送自己的存储信息。当Tracker Server Cluster中的Tracker Server不止一个时,各个Tracker之间的关系是对等的,所以客户端上传时可以选择任意一个Tracker。当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。
如图:
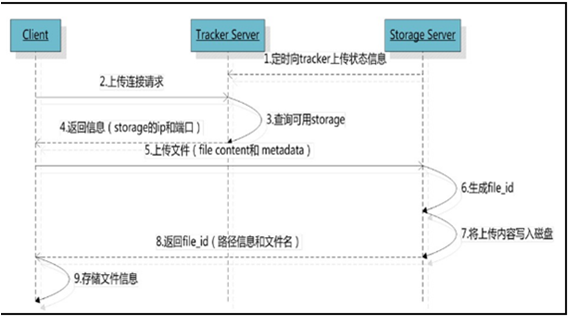
简单总结一下:
1、client询问tracker上传到的storage,不需要附加参数;
2、tracker返回一台可用的storage;
3、client直接和storage通讯完成文件上传。
2.4. FastDFS的文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
2.5. FastDFS的文件下载
客户端uploadfile成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。
如图:
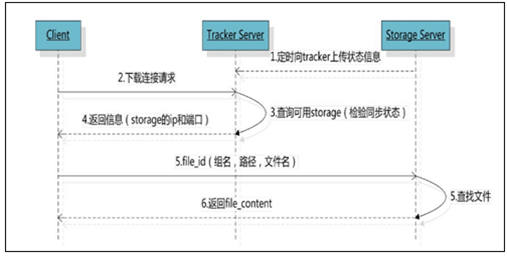
跟upload file一样,在downloadfile时客户端可以选择任意tracker server。tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。
简单总结一下:
1、client询问tracker下载文件的storage,参数为文件标识(组名和文件名);
2、tracker返回一台可用的storage;
3、client直接和storage通讯完成文件下载。
3. FastDFS Docker化集群搭建部署
3.1.准备工作
1)所有机器均能连接外网
2)已安装docker
3)关闭防火墙或防火墙开放对下面要使用的端口(端口在fastdfs集群启动前开放即可)
3.2.搭建步骤
1) 码云上下载该fastdfs_in_docker文件包 链接:https://gitee.com/zjg23/fastdfs_in_docker(文件内含文件如下)
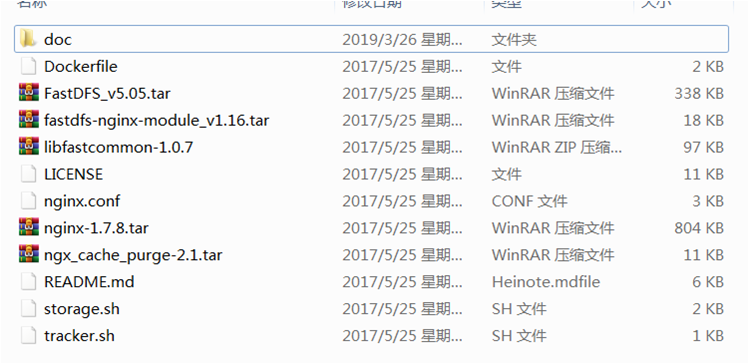
2)将fastdfs_in_docker文件通过xftp传输到所有机器的/home/fastdfs目录下,并创建storage tracker目录。
$ mkdir –p /home/fastdfs/{storage,tracker}(指令方式)
192.168.1.9(tracker服务器)
192.168.1.7(storage服务器)
192.168.1.2(storage服务器)
如下图:
3)(每台机器)进入到fastdfs_in_docker文件目录,并执行docker build指令构建镜像fastdfs镜像。
$docker build -t unionman/fastdfs:2.0 .
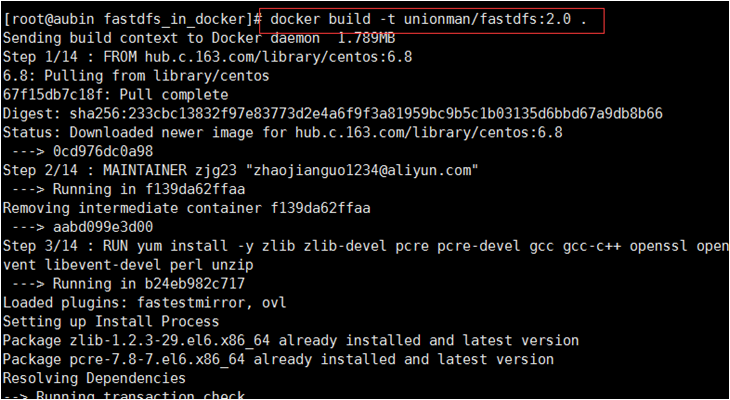
此过程耗时会比较长,耐心等待。
4)如下图可以见到,已经成功构建镜像。

过docker images 指令查看当前已构建的镜像。
$docker images

5)接下来,在192.168.1.9上运行容器 部署tracker服务器。
$ docker run -d --name fdfs_tracker -v /home/fastdfs/tracker:/export/fastdfs/tracker --net=host -e TRACKER_BASE_PATH=/export/fastdfs/tracker -e TRACKER_PORT=22123 unionman/fastdfs:2.0 sh /usr/local/src/tracker.sh
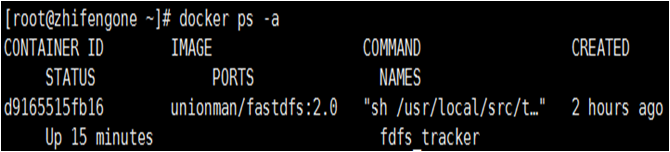
成功运行容器后,通过docker ps指令查看正在运行的容器状态及容器id。可以看到,tracker容器已经搭建好了。
$docker ps -a
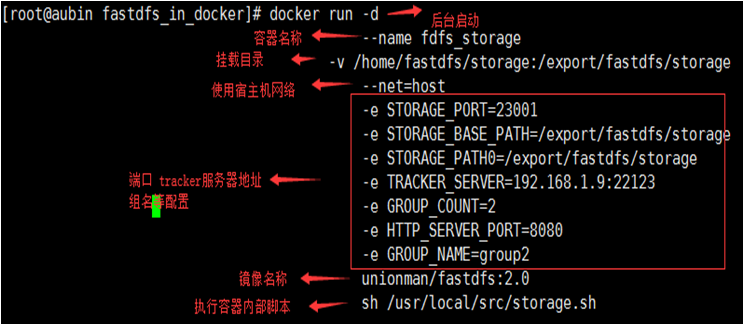
6)接下来,在192.168.1.7 及192.168.1.2上运行容器 部署storage服务器。
在192.168.1.7 上执行:
$ docker run -d --name fdfs_storage -v /home/fastdfs/storage:/export/fastdfs/storage --net=host -e STORAGE_PORT=23001 -e STORAGE_BASE_PATH=/export/fastdfs/storage -e STORAGE_PATH0=/export/fastdfs/storage -e TRACKER_SERVER=192.168.1.9:22123 -e GROUP_COUNT=2 -e HTTP_SERVER_PORT=8080 -e GROUP_NAME=group1 unionman/fastdfs:2.0 sh /usr/local/src/storage.sh
在192.168.1.2上执行:
$ docker run -d --name fdfs_storage -v /home/fastdfs/storage:/export/fastdfs/storage --net=host -e STORAGE_PORT=23001 -e STORAGE_BASE_PATH=/export/fastdfs/storage -e STORAGE_PATH0=/export/fastdfs/storage -e TRACKER_SERVER=192.168.1.9:22123 -e GROUP_COUNT=2 -e HTTP_SERVER_PORT=8080 -e GROUP_NAME=group2 unionman/fastdfs:2.0 sh /usr/local/src/storage.sh
同样成功运行容器后,通过docker ps指令查看正在运行的容器状态及容器id。可以看到,storage容器已经搭建好了。
$docker ps -a
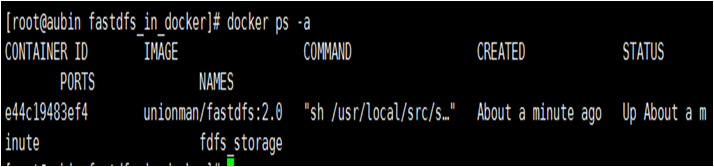
到这里,简单的fastdfs集群就已经搭建完了。
在这里简单解释一下docker run的命令。
7)接下来,我们进入到tracker容器内部查看fastdfs详情。
$docker exec -it d9165515fb16 /bin/sh

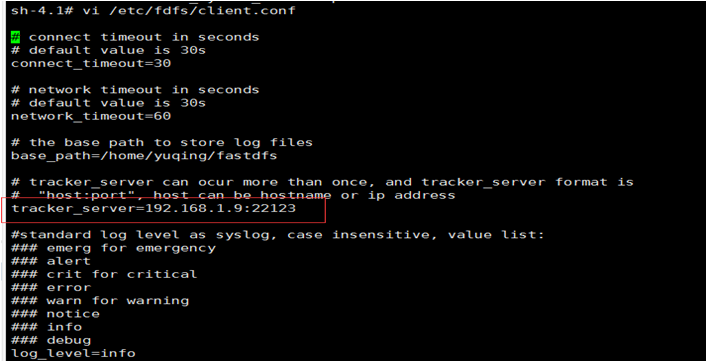
$ vi /etc/fdfs/client.conf
执行指令查看监控状态
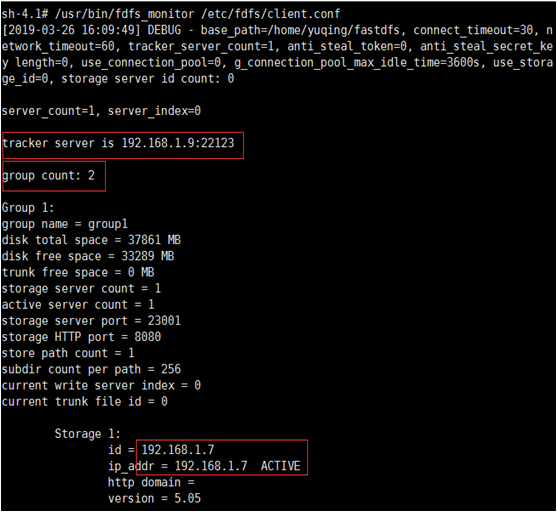
$ /usr/bin/fdfs_monitor /etc/fdfs/client.conf
如果出现如图下情况则,创建相应的文件目录。

再次输入指令
$ /usr/bin/fdfs_monitor /etc/fdfs/client.conf
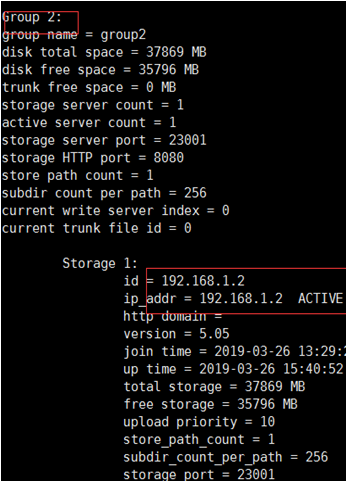
接下来就可以看到详细的监控状态了。
如图为tracker服务器监控状态:
随便编写一个txt文件,测试上传
$vi zzf.txt

执行上传文件指令
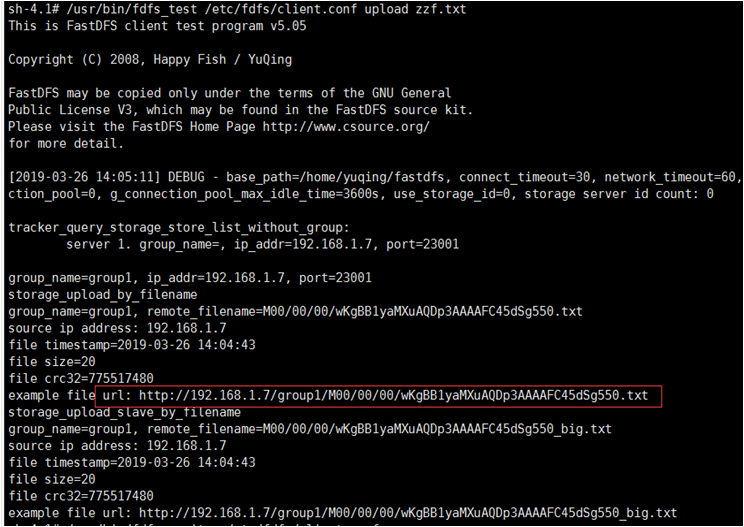
$ /usr/bin/fdfs_test /etc/fdfs/client.conf upload zzf.txt
结果如下图所示
如图为使用fdfs_test客户端上传文件,返回结果集:
每个storage上装有nginx,所以文件也可以通过http的方式直接访问

4.总结
对于fastDNF集群搭建,我也是处于入门阶段,网上搜集很多前辈的资料,学习了几天,亲自搭建了一遍,也亲自把他们的内容归纳总结成这一篇博文。可能还存在一些漏洞。后期有更好的方案或者优化我再去作相应的更新,或者哪位笔友发现问题或者有好的解决方案也可以提供一下,作为博园新人,不足的地方望大家见谅,大家一起进步学习。
FastDfs集群docker化部署的更多相关文章
- RabbitMQ集群 Docker一键部署
以下内容来自网络转载 步骤1. 安装docker 以centos7为例,https://docs.docker.com/engine/installation/linux/centos/ 步骤2. 创 ...
- Neo4j集群容器化部署
集群基本配置(示例) core servers: 10.110.10.11, 10.110.10.12, 10.110.10.13read replicas: 10.110.10.14, 10.110 ...
- 【技术解析】如何用Docker实现SequoiaDB集群的快速部署
1. 背景 以Docker和Rocket为代表的容器技术现在正变得越来越流行,它改变着公司和用户创建.发布.运行分布式应用的方式,在未来5年将给云计算行业带来它应有的价值.它的诱人之处在于: 1)资源 ...
- FastDFS集群部署
之前介绍过关于FastDFS单机部署,详见博文:FastDFS+Nginx(单点部署)事例 下面来玩下FastDFS集群部署,实现高可用(HA) 服务器规划: 跟踪服务器1[主机](Tracker S ...
- FastDFS集群部署(转载 写的比较好)
FastDFS集群部署 之前介绍过关于FastDFS单机部署,详见博文:FastDFS+Nginx(单点部署)事例 下面来玩下FastDFS集群部署,实现高可用(HA) 服务器规划: 跟踪服务器1 ...
- 本文介绍如何使用 Docker Swarm 来部署 Nebula Graph 集群,并部署客户端负载均衡和高可用
本文作者系:视野金服工程师 | 吴海胜 首发于 Nebula Graph 论坛:https://discuss.nebula-graph.com.cn/t/topic/1388 一.前言 本文介绍如何 ...
- Fastdfs集群部署以及基本操作
FastDFS引言 本地存储与分布式文件系统 本地存储的缺点: 是否有备份? 没有 成本角度? 贵 服务器 :用于计算 ---- cpu/内存 用于存储 ---- 硬盘大 存储瓶颈? 容量有限 ...
- Linux安装fastdfs集群部署
过程问题: make: gcc:命令未找到 解决: yum -y install gcc 一.环境和版本: Linux环境:CentOS 7.6 libfastcommon版本:1.0.39 Fast ...
- 从头认识一下docker-附带asp.net core程序的docker化部署
从头认识一下docker-附带asp.net core程序的docker化部署 简介 在计算机技术日新月异的今天, Docker 在国内发展的如火如荼,特别是在一线互联网公司, Docker 的使用是 ...
随机推荐
- python多版本管理工具(pyenv)
在学习和利用python开发的很多情况下,需要多版本的Python并存.此时需要在系统中安装多个Python,但又不能影响系统自带的 Python.pyenv 就是这样一个 Python 版本管理器. ...
- getMemory的经典例子
//NO.1:程序首先申请一个char类型的指针str,并把str指向NULL(即str里存的是NULL的地址,*str为NULL中的值为0),调用函数的过程中做了如下动作:1申请一个char类型的指 ...
- ThinkPHP5 打开多语言支持
1.在thinkphp\start.php 页面中添加多语言的切换函数的参数格式,本贴目前只支持两种语言,并注意必须全部小写!全部小写!!全部小写!!!,注意这一步很关键 Lang::setAllow ...
- Devexpress Ribbon 动态生成菜单
/// <summary> /// 动态加载菜单 /// </summary> private void GetMenuBind() { //根据登录用户角色菜单动态创建 // ...
- Ubuntu部署python3.7的开发和运行环境
Ubuntu部署python3.7的开发和运行环境 1 概述 由于最近项目全部由python2.x转向 python3.x(使用 python3.7.1) ,之前的云主机的的默认python版本都面临 ...
- [Swift]LeetCode159.具有最多两个不同字符的最长子串 $ Longest Substring with At Most Two Distinct Characters
Given a string S, find the length of the longest substring T that contains at most two distinct char ...
- [Swift]LeetCode243.最短单词距离 $ Shortest Word Distance
Given a list of words and two words word1 and word2, return the shortest distance between these two ...
- 简单python程序练习
1.打印※花矩形 i = 1 while i<=5: j = 1 while j <=5: print("*",end="") #end=" ...
- 利用Zabbix来监控Windows Performance Counter
Windows的性能计数器提供了很多系统的性能指标度量,通过Windows的性能计数器,我们可以对Windows的服务器的当前运行状态有个即时的情况了解. Zabbix Agent支持(Win) pe ...
- MySQL如何系统学习
MySQL是当下互联网最流行的开源数据库.不管你使用或者学习何种编程语言,都将会使用到数据库,而MySQL则是应用最为广泛的数据库,没有之一! 之前在我的博客上也发布过一些MySQL优化配置项,都收到 ...