分库分表后跨分片查询与Elastic Search
携程酒店订单Elastic Search实战:http://www.lvesu.com/blog/main/cms-610.html
为什么分库分表后不建议跨分片查询:https://www.jianshu.com/p/1a0c6eda6f63
分库分表技术演进(阿里怎么分):https://mp.weixin.qq.com/s/3ZxGq9ZpgdjQFeD2BIJ1MA
1.需求背景
移动互联网时代,海量的用户每天产生海量的数量,这些海量数据远不是一张表能Hold住的。比如
- 用户表:支付宝8亿,微信10亿。CITIC对公140万,对私8700万。
- 订单表:美团每天几千万,淘宝历史订单百亿、千亿。
- 交易流水表
2.选择方案
(1)NoSQL/NewSQL(不选择)
选择RDBMS,不选择NoSQL/NewSQL,主要是因为NoSQL/NewSQL可靠性无法与RDBMS相提并论。RDBMS有以下几个优点:
- RDBMS生态完善;
- RDBMS绝对稳定;
- RDBMS的事务特性;
目前绝大部分公司的核心数据都是:以RDBMS存储为主,NoSQL/NewSQL存储为辅!互联网公司又以MySQL为主,国企&银行等不差钱的企业以Oracle/DB2为主!NoSQL比较具有代表性的是MongoDB,es。NewSQL比较具有代表性的是TiDB。
(2)分区(不选择)
- 分区原理:分区表是由多个相关的底层表实现,存储引擎管理分区的各个底层表和管理普通表一样,只是分区表在各个底层表上各自加上一个相同的索引(分区表要求所有的底层表都必须使用相同的存储引擎)。
- 分区优点:它对用户屏蔽了sharding的细节,即使查询条件没有sharding column,它也能正常工作(只是这时候性能一般)。
- 分区缺点:连接数、网络吞吐量等资源都受到单机的限制;并发能力远远达不到互联网高并发的要求。(主要因为虽然每个分区可以独立存储,但是分区表的总入口还是一个MySQL示例)。
- 适用场景:并发能力要求不高;数据不是海量(分区数有限,存储能力就有限)。
(3)分库分表(选择)
互联网行业处理海量数据的通用方法:分库分表。 分库分表中间件全部可以归结为两大类型:
CLIENT模式;
PROXY模式;
CLIENT模式代表有阿里的TDDL,开源社区的sharding-jdbc(sharding-jdbc的3.x版本即sharding-sphere已经支持了proxy模式)。架构如下:
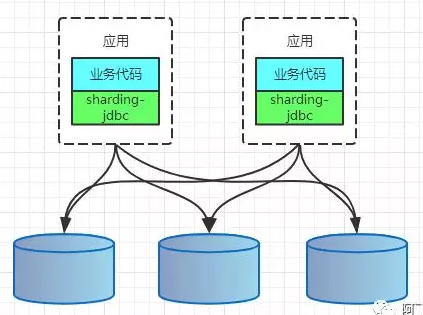
PROXY模式代表有阿里的cobar,民间组织的MyCAT。架构如下:
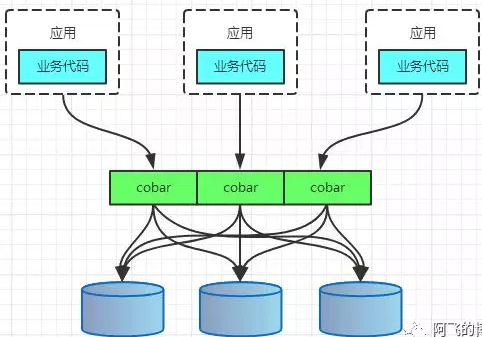
无论是CLIENT模式,还是PROXY模式。几个核心的步骤是一样的:SQL解析,重写,路由,执行,结果归并。
3.分库分表思路(MYSQL)
- 单个sharding column分库分表 ;
- 多个sharding column分库分表;
- sharding column分库分表 + ES检索;
阿里:选用orderid分表,那我用userid来查询的很多,那不是所有的分表都要查?怎么处理
以阿里订单系统为例(参考《企业IT架构转型之道:阿里巴巴中台战略思想与架构实现》),它选择了三个column作为三个独立的sharding column,即:order_id,user_id,merchant_code。user_id和merchant_code就是买家ID和卖家ID,因为阿里的订单系统中买家和卖家的查询流量都比较大,并且查询对实时性要求都很高。而根据order_id进行分库分表,应该是根据order_id的查询也比较多。
4.分库分表落地(MYSQL)
(1)选择合适的sharding column
分库分表第一步也是最重要的一步,即sharding column的选取,sharding column选择的好坏将直接决定整个分库分表方案最终是否成功。sharding column的选取跟业务强相关。
- 选择方法:分析你的API流量,将流量比较大的API对应的SQL提取出来,将这些SQL共同的条件作为sharding column。
- 选择示例:例如一般的OLTP系统都是对用户提供服务,这些API对应的SQL都有条件用户ID,那么,用户ID就是非常好的sharding column。
(2)冗余全量表和冗余关系表选择(订单表)
例如将一张订单表t_order拆分成三张表t_order、t_user_order、t_merchant_order。分别使用三个独立的sharding column,即order_id(订单号),user_id(用户ID),merchant_code(商家ID)。

冗余全量表:每个sharding列对应的表的数据都是全量的
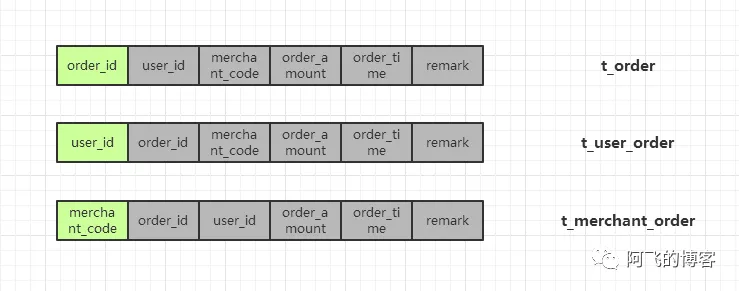
冗余关系表:只有一个sharding column的分库分表的数据是全量的,其他分库分表只是与这个sharding column的关系表。实际使用中可能会冗余更多常用字段,如用户名称、商户名称等。
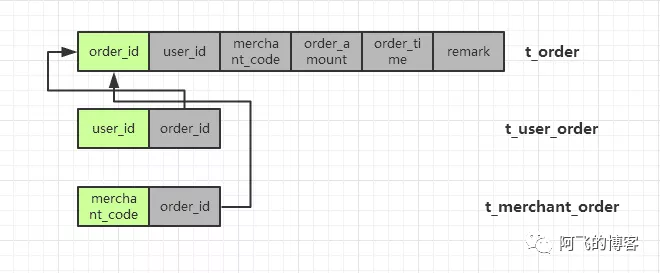
冗余全量表 VS 冗余关系表
- 速度对比:冗余全量表速度更快,冗余关系表需要二次查询,即使有引入缓存,还是多一次网络开销;
- 存储成本:冗余全量表需要几倍于冗余关系表的存储成本;
- 维护代价:冗余全量表维护代价更大,涉及到数据变更时,多张表都要进行修改。
总结:选择冗余全量表还是索引关系表,这是一种架构上的trade off(权衡),两者的优缺点明显,阿里的订单表是冗余全量表。
(3)单个sharding column分库分表示例(账户表)

一般账户相关API使用account_no为sharding column
(4)多个sharding column分库分表示例(用户表)
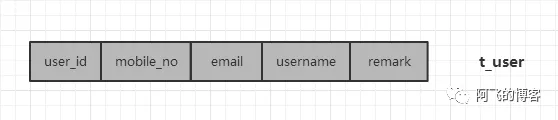
用户可以通过mobile_no,email和username进行登录,一些用户相关API又常使用user_id,所以sharding column选这4个字段。
(5)sharding column分库分表 + ES检索(模糊查询)
上面提到的都是条件中有sharding column的SQL执行。但是,总有一些查询条件是不包含sharding column的,同时,我们也不可能为了这些请求量并不高的查询,无限制的冗余分库分表。那么这些查询条件中没有sharding column的SQL怎么处理?以sharding-jdbc为例,有多少个分库分表,就要并发路由到多少个分库分表中执行,然后对结果进行合并。这种条件查询相对于有sharding column的条件查询性能很明显会下降很多。
更有甚者,尤其是有些运营系统中的模糊条件查询,或者上十个条件筛选。例如淘宝我的所有订单页面,筛选条件有多个,且商品标题可以模糊匹配,这即使是单表都解决不了的问题,更不用谈分库分表了。
sharding column + es的模式,将分库分表所有数据全量冗余到es中,将那些复杂的查询交给es处理。(ElasticSearch,搜索引擎)以订单表为例:
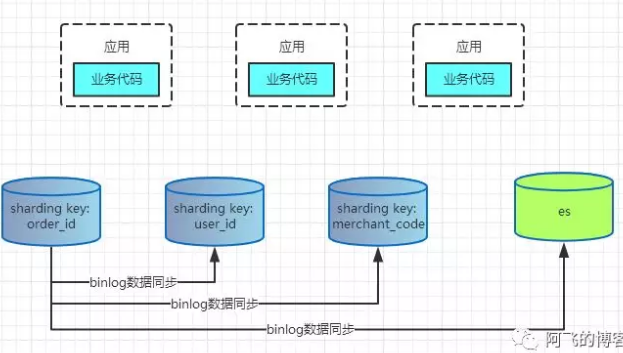
PS:多sharding column不到万不得已的情况下最好不要使用,建议采用单sharding column + es的模式简化架构。
5.全文索引思路(HBase)
- Solr+HBase
- ES+HBase
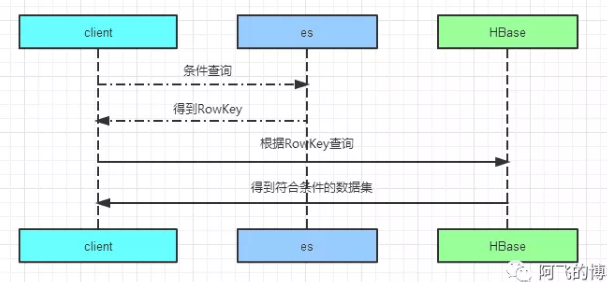
可能参与条件检索的字段索引到ES中,所有字段的全量数据保存到HBase中,这就是经典的ES+HBase组合方案,即索引与数据存储隔离的方案。Hadoop体系下的HBase存储能力我们都知道是海量的,而且根据它的rowkey查询性能那叫一个快如闪电。而es的多条件检索能力非常强大。这个方案把es和HBase的优点发挥的淋漓尽致,同时又规避了它们的缺点,可以说是一个扬长避免的最佳实践。
它们之间的交互大概是这样的:先根据用户输入的条件去es查询获取符合过滤条件的rowkey值,然后用rowkey值去HBase查询,后面这一查询步骤的时间几乎可以忽略,因为这是HBase最擅长的场景,交互图如下所示:
6.总结
最后,对几种方案总结如下(sharding column简称为sc):

对于海量数据,且有一定的并发量的分库分表,绝不是引入某一个分库分表中间件就能解决问题,而是一项系统的工程。需要分析整个表相关的业务,让合适的中间件做它最擅长的事情。例如有sharding column的查询走分库分表,一些模糊查询,或者多个不固定条件筛选则走es,海量存储则交给HBase。
做了这么多事情后,后面还会有很多的工作要做,比如数据同步的一致性问题,还有运行一段时间后,某些表的数据量慢慢达到单表瓶颈,这时候还需要做冷数据迁移。
MySQL单表可以存储10亿级数据,只是这时候性能比较差,业界公认MySQL单表容量在1KW以下是最佳状态,因为这时它的BTREE索引树高在3~5之间。
参考文档:
转自:https://www.cnblogs.com/badboy200800/p/9790395.html
分库分表后跨分片查询与Elastic Search的更多相关文章
- 【分库分表】sharding-jdbc—分片策略
一.分片策略 Sharding-JDBC认为对于分片策略存有两种维度: 数据源分片策略(DatabaseShardingStrategy):数据被分配的目标数据源 表分片策略(TableShardin ...
- 为什么MySQL分库分表后总存储大小变大了?
1.背景 在完成一个分表项目后,发现分表的数据迁移后,新库所需的存储容量远大于原本两张表的大小.在做了一番查询了解后,完成了优化. 回过头来,需要进一步了解下为什么会出现这样的情况. 与标题的问题的类 ...
- mysql分库分表那些事
为什么使用分库分表? 如下内容,引用自 Sharding Sphere 的文档,写的很大气. <ShardingSphere > 概念 & 功能 > 数据分片> 传统的 ...
- 分库分表真的适合你的系统吗?聊聊分库分表和NewSQL如何选择
曾几何时,"并发高就分库,数据大就分表"已经成了处理 MySQL 数据增长问题的圣经. 面试官喜欢问,博主喜欢写,候选人也喜欢背,似乎已经形成了一个闭环. 但你有没有思考过,分库分 ...
- 你们要的MyCat实现MySQL分库分表来了
❝ 借助MyCat来实现MySQL的分库分表落地,没有实现过的,或者没了解过的可以看看 ❞ 前言 在之前写过一篇关于mysql分库分表的文章,那篇文章只是给大家提供了一个思路,但是回复下面有很多说是细 ...
- MySQL订单分库分表多维度查询
转自:http://blog.itpub.net/29254281/viewspace-2086198/ MySQL订单分库分表多维度查询 MySQL分库分表,一般只能按照一个维度进行查询. 以订单 ...
- 数据库分库分表和带来的唯一ID、分页查询问题的解决
需求缘起(用一个公司的发展作为背景) 1.还是个小公司的时候,注册用户就20w,每天活跃用户1w,每天最大单表数据量就1000,然后高峰期每秒并发请求最多就10,此时一个16核32G的服务器,每秒请求 ...
- MYSQL数据库数据拆分之分库分表总结
数据存储演进思路一:单库单表 单库单表是最常见的数据库设计,例如,有一张用户(user)表放在数据库db中,所有的用户都可以在db库中的user表中查到. 数据存储演进思路二:单库多表 随着用户数量的 ...
- 面试官:"谈谈分库分表吧?"
原文链接:面试官:"谈谈分库分表吧?" 面试官:“有并发的经验没?” 应聘者:“有一点.” 面试官:“那你们为了处理并发,做了哪些优化?” 应聘者:“前后端分离啊,限流啊 ...
随机推荐
- nginx+uwsgi部署django项目
1.django项目部署前需要生成admin的静态资源文件 (1)生成admin的静态资源文件 # 关闭debug模型 DEBUG = False # 允许所有域名访问 ALLOWED_HOSTS = ...
- 【spring源码分析】IOC容器初始化(十一)
前言:前面分析了doCreateBean中的createBeanInstance函数,接下来分析其剩余流程. 首先贴上doCreateBean函数: // AbstractAutowireCapabl ...
- Django-CRM项目学习(八)-客户关系系统整体实现(待完成!)
注意点:利用stark组件与rbac组件实现客户关系系统 1.需求整理与确认 1.1 客户关系系统整体需求 a
- Django Template(模板)
一.模板组成 组成:HTML代码 + 逻辑控制代码 二.逻辑控制代码的组成 1.变量 语法格式 : {{ name }} # 使用双大括号来引用变量 1.Template和Context对象(不推荐使 ...
- redis 初步认识二(c#调用redis)
前置:服务器安装redis 1.引用redis 2.使用redis(c#) 一 引用redis (nuget 搜索:CSRedisCore) 二 使用redis(c#) using System ...
- 19 款仿 Bootstrap 后台管理主题免费下载
声明: 1. 本篇文章提到的仿 Bootstrap 风格的主题,是基于 jQuery 的 ASP.NET MVC 控件库的主题. 2. FineUIMvc(基础版)完全免费,可以用于商业项目. 目录 ...
- Aninteresting game HDU - 5975 (数学+lowbit)
Let’s play a game.We add numbers 1,2...n in increasing order from 1 and put them into some sets. Whe ...
- nginx简单的命令
nginx -s reload|reopen|stop|quit #重新加载配置|重启|停止|退出 nginx nginx -t #测试配置是否有语法错误 nginx [-?hvVtq] [-s si ...
- flutter Provide 状态管理篇
Provide是Google官方推出的状态管理模式.官方地址为: https://github.com/google/flutter-provide 现在Flutter的状态管理方案很多,redux. ...
- 2018年NGINX最新版高级视频教程
2018年NGINX最新版高级视频教程,想要的联系我,QQ:1844912514