[NOIP2016] 天天爱跑步 桶 + DFS
题解:
很久以前就想写了,一直没敢做,,,不过今天写完没怎么调就过了还是很开心的。
首先我们观察到跑步的人数是很多的,要一条一条的遍历显然是无法承受的,因此我们要考虑更加优美的方法。
首先我们假设观察者没有时间的限制,一天到晚都在观察。那么我们可以想到一个很显然的做法——差分。这样就可以很方便的求出一个点被经过了多少次。
貌似这样再加想一下就可以直接用树链剖分+差分搞了。
但是还有更好的算法,是O(n)的。
而且还是比较好写的。
首先我们观察可以被统计到的点要符合一个什么条件。
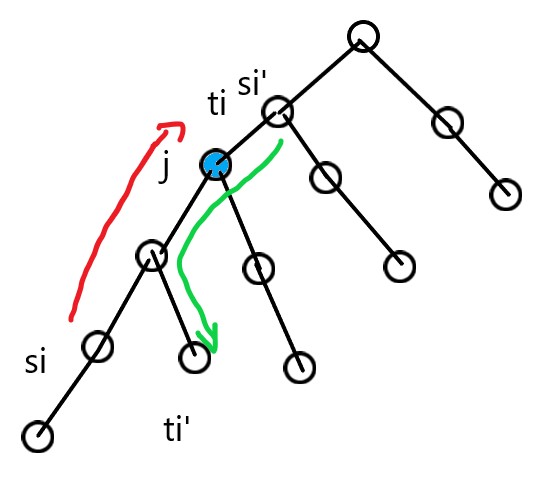
设点j上的观察者在w[j]的时候观察,那么也就是说从s出发,要刚好经过w[j]到达点j,才可以被点j上的观察者统计到。
由此我们可以列出两个式子:
1,当s在j的子树内,而t在j的上方时。
$w[j] + dep[j] = dep[s_i]$
2,当t在j的子树内,而s在j的上方时
$dis[i] - (dep[t_i] - dep[j]) = w[j]$ 其中dis[i]表示s ---> t的路程长度
因为dis[i] - (dep[t_i] - dep[j])其实就是s ---> j的路径长,所以这个式子就显然成立了。
如果我们将带i的放在左边,带j的放在右边,那么将会有
$dis[i] - dep[t_i] = w[j] - dep[j]$
那s和t都在j的子树内怎么办?(都在上方显然不会统计到)
现在这时如果我们还是套用上面的式子,那么会有两种情况
(1),j是(s,t)的LCA,那么此时两个式子一旦其中之一被满足,另外一个就一定会被满足(因为两个式子的实质是一样的),那么s和t将分别对j产生一次贡献(否则没有贡献)
(2),j不是(s,t)的LCA,那么此时两个式子可能会被满足,s和t不一定会对j产生贡献。但是这种情况下,不论式子是否被满足,s和t都是不应该对j产生贡献的。
那么我们怎么避免这种情况?
首先我们注意到一旦这种情况出现,LCA[s,t]将会是s和t最后一次可能产生贡献的地方,因此我们要在LCA[s,t]处,消除s和t的影响,使得s和t无法对上面的点产生贡献。
那么我们应该如何统计呢?
注意到所有的式子都可以被表示为左边只有关于i的,右边只有关于j的情况,因此我们完全可以将式子的左边和右边单独计算。即分别用两个桶统计关于两个式子的满足情况。
比如说我们定义int bu[600100]; 然后每次遇到一个$s_i$的时候,我们就令$dep[s_i]++$。然后我们在每进入一个点时,都记录一个tmp = bu[w[j] + dep[j]],那么桶内对应位置元素的个数就代表满足
$dep[s_i] = t$(t为桶中位置)的元素个数。因此我们访问bu[w[j] + dep[j]]就可以获取满足 $w[j] + dep[j] = dep[s_i]$ 的元素个数,而之所以要在进入之前先记录一下位置,则是为了准确获取子树内的贡献,保证不被之前的东西干扰。
对第二个式子的处理方式也是类似的,只不过因为第二个式子中出现了减号,而且减号旁边大小关系不确定,因此我们需要的桶中位置可能为负,所以我们统一加上一个较大的数,将本来要占据负数的数组整体向后移位就可以了。
具体实现看代码。
#include<bits/stdc++.h>
using namespace std;
#define R register int
#define AC 501000
#define ac 910000//要开这么大。。。
#define getchar() *o++
char READ[], *o = READ;
int n, m;
int w[AC], ans[AC], s[AC], t[AC], dis[AC], dep[AC], may[ac], id[ac];
int Head[AC], Next[ac], date[ac], tot;
struct edge{
int Head[AC], Next[ac], date[ac], tot;
inline void add(int f, int w)
{
date[++tot] = w, Next[tot] = Head[f], Head[f] = tot;
date[++tot] = f, Next[tot] = Head[w], Head[w] = tot;
}
}E1,E2,E3;//询问的边(LCA),查询的边(ans) inline int read()
{
int x = ; char c = getchar();
while(c > '' || c < '') c = getchar();
while(c >= '' && c <= '') x = x * + c - '', c = getchar();
return x;
} inline void add(int f, int w)
{
date[++tot] = w, Next[tot] = Head[f], Head[f] = tot;
date[++tot] = f, Next[tot] = Head[w], Head[w] = tot;
} inline void add1(int f, int w, int S)
{
E3.date[++tot] = w, E3.Next[tot] = E3.Head[f], E3.Head[f] = tot, may[tot] = S;
} inline void add2(int f, int w)//这里只能连单向边
{
E2.date[++tot] = w, E2.Next[tot] = E2.Head[f], E2.Head[f] = tot;
} void pre()
{
int a, b;
n = read(), m = read();
for(R i = ; i < n; i++)
{
a = read(), b = read();
add(a, b);
}
for(R i = ; i <= n; i++) w[i] = read();
E1.tot = E2.tot = tot = ;
for(R i = ; i <= m; i++)
{
s[i] = read(), t[i] = read();
E1.add(s[i], t[i]);
add1(s[i], i, );//标记为开始节点
add1(t[i], i, );//标记为结束节点
id[E1.tot - ] = id[E1.tot] = i;
}
} struct get_LCA{
int father[AC], LCA[ac]; bool z[AC]; inline int find(int x)
{
return (x == father[x]) ? x : father[x] = find(father[x]);
} void dfs(int x)
{
int now;
z[x] = true;
for(R i = Head[x]; i; i = Next[i])
{
now = date[i];
if(z[now]) continue;
dep[now] = dep[x] + ;
dfs(now);
father[now] = x;//访问完就要改父亲了
}
for(R i = E1.Head[x]; i; i = E1.Next[i])
{
now = E1.date[i];
if(z[now] && !LCA[i ^ ])
{
// printf("%d %d\n", x, now);
LCA[i] = find(now);
dis[id[i]] = dep[x] - dep[LCA[i]] + dep[now] - dep[LCA[i]];
add2(LCA[i], id[i]);//将LCA和询问联系起来
}
}
} void getLCA()
{
for(R i = ; i <= n; i++) father[i] = i;
dep[] = ;
dfs();
}
}LCA; #define k 600000
struct difference{
int bu[ac], b[ac * ];
void dfs(int x, int fa)
{
int tmp = bu[dep[x] + w[x]], rnt = b[w[x] - dep[x] + k], now;
for(R i = E3.Head[x]; i; i = E3.Next[i])//加上当前节点的贡献
{
now = E3.date[i];
if(!may[i]) ++bu[dep[x]];//如果是开始节点
else ++b[dis[now] - dep[x] + k];//等式两边同时+k
}
for(R i = Head[x]; i; i = Next[i])//遍历子树
{
now = date[i];
if(now == fa) continue;
dfs(now, x);
}
ans[x] = bu[dep[x] + w[x]] - tmp + b[w[x] - dep[x] + k] - rnt;
for(R i = E2.Head[x]; i; i = E2.Next[i])//查看当前节点是哪些点对的LCA
{
now = E2.date[i];
if(dep[s[now]] == dep[x] + w[x]) --ans[x];//如果造成了贡献,那么必定是双倍,因此要减去
--bu[dep[s[now]]];//减去贡献
--b[dis[now] - dep[t[now]] + k];//等式两边同时+k!
}
} }get; void work()
{
for(R i = ; i <= n; i++) printf("%d ", ans[i]);
printf("\n");
} int main()
{
freopen("in.in", "r", stdin);
fread(READ, , , stdin);
pre();
LCA.getLCA();
get.dfs(, );
work();
fclose(stdin);
return ;
}
[NOIP2016] 天天爱跑步 桶 + DFS的更多相关文章
- [Noip2016]天天爱跑步 LCA+DFS
[Noip2016]天天爱跑步 Description 小c同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.?天天爱跑步?是一个养成类游戏,需要玩家每天按时上线,完成打卡任 ...
- luogu1600 [NOIp2016]天天爱跑步 (tarjanLca+dfs)
经过部分分的提示,我们可以把一条路径切成s到lca 和lca到t的链 这样就分为向上的链和向下的链,我们分开考虑: 向上:如果某一个链i可以对点x产生贡献,那么有deep[x]+w[x]=deep[S ...
- [NOIp2016]天天爱跑步 线段树合并
[NOIp2016]天天爱跑步 LG传送门 作为一道被毒瘤出题人们玩坏了的NOIp经典题,我们先不看毒瘤的"动态爱跑步"和"天天爱仙人掌",回归一下本来的味道. ...
- 【LG1600】[NOIP2016]天天爱跑步
[LG1600][NOIP2016]天天爱跑步 题面 洛谷 题解 考虑一条路径\(S\rightarrow T\)是如何给一个观测点\(x\)造成贡献的, 一种是从\(x\)的子树内出来,另外一种是从 ...
- NOIP2016天天爱跑步 题解报告【lca+树上统计(桶)】
题目描述 小c同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.«天天爱跑步»是一个养成类游戏,需要玩家每天按时上线,完成打卡任务. 这个游戏的地图可以看作一一棵包含 nn个 ...
- NOIP2016 天天爱跑步 线段树合并_桶_思维题
竟然独自想出来了,好开心 Code: #include<bits/stdc++.h> #define setIO(s) freopen(s".in","r&q ...
- NOIP2016 天天爱跑步(线段树/桶)
题目描述 小c同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.天天爱跑步是一个养成类游戏,需要 玩家每天按时上线,完成打卡任务. 这个游戏的地图可以看作一一棵包含 N个结点 ...
- noip2016天天爱跑步
题目描述 小c同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.«天天爱跑步»是一个养成类游戏,需要玩家每天按时上线,完成打卡任务. 这个游戏的地图可以看作一一棵包含 个结点 ...
- P1600 天天爱跑步[桶+LCA+树上差分]
题目描述 小c同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.<天天爱跑步>是一个养成类游戏,需要玩家每天按时上线,完成打卡任务. 这个游戏的地图可以看作一一棵 ...
随机推荐
- web之前端获取上传图片并展示
1.html中经常存在图片上传的问题,但是后续的展示基本上是通过后台输出流的方式来呈现的.但是这样耗费的资源比较多.所以这里学习了一种前端直接展示图片的方式(供参考). 2.html的编写方式比较简单 ...
- 聊聊WS-Federation(test)
本文来自网易云社区 单点登录(Single Sign On),简称为 SSO,目前已经被大家所熟知.简单的说, 就是在多个应用系统中,用户只需要登录一次就可以访问所有相互信任的应用系统. 举例: 我们 ...
- Git笔记——01
Git - 幕布 Git 教程:https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b00 ...
- Unity Android设备的输入
Unity Android设备的输入 1依据屏幕位置输入 有的时候也许是为了整个有些风格的干净,减少屏幕上的UI图标,以至于摒弃了虚拟按键这种常用的输入方式.为了替代虚拟按键的输入方式而选择了依据点击 ...
- linux 命令行基础
命令行基础 一些名词 「图形界面」 「命令行」 「终端」 「shell」 「bash」 安装使用 Windws: 安装git, 打开 gitbash Linux 打开终端 Mac 打开终端 基本命令 ...
- mapReduce入门教程
什么是MapReduce MapReduce是Google提出的一个软件架构,用于大规模数据集(大于1TB)的并行运算.概念"Map(映射)"和"Reduce(归纳)&q ...
- [转载]CENTOS 6.0 iptables 开放端口80 3306 22端口
原文地址:6.0 iptables 开放端口80 3306 22端口">CENTOS 6.0 iptables 开放端口80 3306 22端口作者:云淡风轻 #/sbin/iptab ...
- 剑指offer-包含min函数的栈20
题目描述 定义栈的数据结构,请在该类型中实现一个能够得到栈中所含最小元素的min函数(时间复杂度应为O(1)). class Solution: def __init__(self): self.st ...
- Ubuntu—查看进程并关闭进程
环境:Ubuntu终端 命令:ps -aux 功能:查看进程信息 命令:kill 进程号(PID) 功能:杀死进程
- linux服务器操作小技巧
python程序后台一直运行,并将打印信息输出到文件中 nohup -u test.py > out.txt & -u 表示无缓冲,直接将打印信息输出带文件中 &表示程序后台运行