本地矩阵(Local Matrix)
本地矩阵具有整型的行、列索引值和双精度浮点型的元素值,它存储在单机上。MLlib支持稠密矩阵DenseMatrix和稀疏矩阵Sparse Matrix两种本地矩阵,稠密矩阵将所有元素的值存储在一个列优先(Column-major)的双精度型数组中,而稀疏矩阵则将非零元素以列优先的CSC(Compressed Sparse Column)模式进行存储,关于CSC等稀疏矩阵存储方式的具体实现,可以参看:
https://www.tuicool.com/articles/A3emmqi
或者
http://www.cs.colostate.edu/~mcrob/toolbox/c++/sparseMatrix/sparse_matrix_compression.html
本地矩阵的基类是org.apache.spark.mllib.linalg.Matrix,DenseMatrix和SparseMatrix均是它的实现类,和本地向量类似,MLlib也为本地矩阵提供了相应的工具类Matrices,调用工厂方法即可创建实例:
scala>import org.apache.spark.mllib.linalg.{Matrix, Matrices}
import org.apache.spark.mllib.linalg.{Matrix, Matrices}
// 创建一个3行2列的稠密矩阵[ [1.0,2.0], [3.0,4.0], [5.0,6.0] ]
// 请注意,这里的数组参数是列先序的!
scala> val dm: Matrix = Matrices.dense(, , Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
dm: org.apache.spark.mllib.linalg.Matrix =
1.0 2.0
3.0 4.0
5.0 6.0
这里可以看出列优先的排列方式,即按照列的方式从数组中提取元素。也可以创建稀疏矩阵:
// 创建一个3行2列的稀疏矩阵[ [9.0,0.0], [0.0,8.0], [0.0,6.0]]
// 第一个数组参数表示列指针,即每一列元素的开始索引值
// 第二个数组参数表示行索引,即对应的元素是属于哪一行
// 第三个数组即是按列先序排列的所有非零元素,通过列指针和行索引即可判断每个元素所在的位置
scala> val sm: Matrix = Matrices.sparse(, , Array(, , ), Array(, , ), Array(, , ))
sm: org.apache.spark.mllib.linalg.Matrix =
x CSCMatrix
(,) 9.0
(,) 6.0
(,) 8.0
9 0
0 8
0 6
0 1 3
这里,创建一个3行2列的稀疏矩阵[ [9.0,0.0], [0.0,8.0], [0.0,6.0]]。Matrices.sparse的参数中,3表示行数,2表示列数。第1个数组参数表示列指针,即每一列元素的开始索引值, 第二个数组参数表示行索引,即对应的元素是属于哪一行;第三个数组即是按列先序排列的所有非零元素,通过列指针和行索引即可判断每个元素所在的位置。比如取每个数组的第2个元素为2,1,6,表示第2列第1行的元素值是6.0。
注:第一个数组参数表示列指针详细解释:
列偏移表示某一列的第一个非0元素在values里面的起始偏移位置。在列偏移的最后补上矩阵总的非0元素个数。
0 1 3 6 9 11 14
1 2 4 7 10 12 15
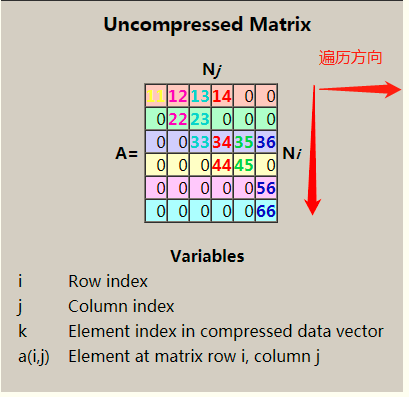
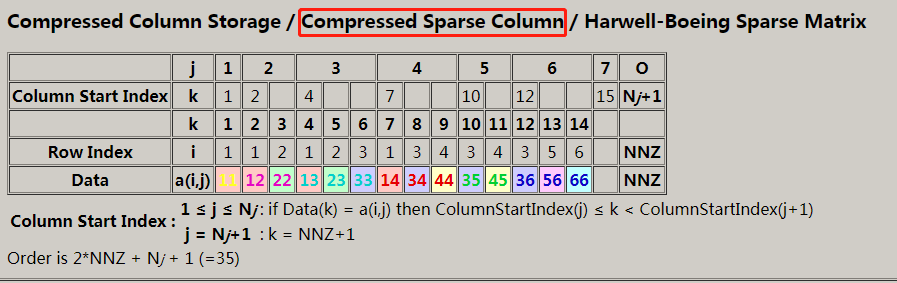
//下列矩阵 1.0 0.0 4.0 0.0 3.0 5.0 2.0 0.0 6.0 如果采用稀疏矩阵存储的话,其存储信息包括: 实际存储值: [1.0, 2.0, 3.0, 4.0, 5.0, 6.0]`, 矩阵元素对应的行索引:rowIndices=[, , , , , ]` 列起始位置索引: `colPointers=[, , , ]`. scala> val sparseMatrix= Matrices.sparse(, , Array(, , , ), Array(, , , , , ), Array(1.0, 2.0, 3.0, 4.0, 5.0, 6.0)) sparseMatrix: org.apache.spark.mllib.linalg.Matrix = x CSCMatrix (,) 1.0 (,) 2.0 (,) 3.0 (,) 4.0 (,) 5.0 (,) 6.0
本地矩阵(Local Matrix)的更多相关文章
- Spark Mllib里的本地矩阵概念、构成(图文详解)
不多说,直接上干货! Local matrix:本地矩阵 数组Array(1,2,3,4,5,6)被重组成一个新的2行3列的矩阵. testMatrix.scala package zhouls.bi ...
- R语言编程艺术# 矩阵(matrix)和数组(array)
矩阵(matrix)是一种特殊的向量,包含两个附加的属性:行数和列数.所以矩阵也是和向量一样,有模式(数据类型)的概念.(但反过来,向量却不能看作是只有一列或一行的矩阵. 数组(array)是R里更一 ...
- 【Math for ML】矩阵分解(Matrix Decompositions) (下)
[Math for ML]矩阵分解(Matrix Decompositions) (上) I. 奇异值分解(Singular Value Decomposition) 1. 定义 Singular V ...
- 【Math for ML】矩阵分解(Matrix Decompositions) (上)
I. 行列式(Determinants)和迹(Trace) 1. 行列式(Determinants) 为避免和绝对值符号混淆,本文一般使用\(det(A)\)来表示矩阵\(A\)的行列式.另外这里的\ ...
- R语言编程艺术#02#矩阵(matrix)和数组(array)
矩阵(matrix)是一种特殊的向量,包含两个附加的属性:行数和列数.所以矩阵也是和向量一样,有模式(数据类型)的概念.(但反过来,向量却不能看作是只有一列或一行的矩阵. 数组(array)是R里更一 ...
- NumPy 矩阵库(Matrix)
NumPy 矩阵库(Matrix) NumPy 中包含了一个矩阵库 numpy.matlib,该模块中的函数返回的是一个矩阵,而不是 ndarray 对象. 一个 的矩阵是一个由行(row)列(col ...
- Hadoop部署方式-本地模式(Local (Standalone) Mode)
Hadoop部署方式-本地模式(Local (Standalone) Mode) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. Hadoop总共有三种运行方式.本地模式(Local ...
- HTML5本地存储(Local Storage) 的前世今生
长久以来本地存储能力一直是桌面应用区别于Web应用的一个主要优势.对于桌面应用(或者原生应用),操作系统一般都提供了一个抽象层用来帮助应用程序保存其本地数据 例如(用户配置信息或者运行时状态等). 常 ...
- iOS 远程通知(Remote Notification)和本地通知(Local Notification)
ios通知分为远程通知和本地通知,远程通知需要连接网络,本地通知是不需要的,不管用户是打开应用还是关闭应用,我们的通知都会发出,并被客户端收到 我们使用远程通知主要是随时更新最新的数据给用户,使用本地 ...
随机推荐
- 从零开始学习CocoaPods安装和使用
从零开始学习CocoaPods安装和使用 转载: Code4App原创:http://code4app.com/article/cocoapods-install-usage http://m.i ...
- Spring - 父容器与子容器
一.Spring容器(父容器) 1.Mapper代理对象 2.Service对象 二.Springmvc(前端控制器)(子容器) Controller对象 1.标准的配置是这样的:Con ...
- 一点一点看JDK源码(三)java.util.ArrayList 前偏
一点一点看JDK源码(三)java.util.ArrayList liuyuhang原创,未经允许禁止转载 本文举例使用的是JDK8的API 目录:一点一点看JDK源码(〇) 1.综述 ArrayLi ...
- Web—05-常用css列表
color 设置文字的颜色,如: color:red; font-size 设置文字的大小,如:font-size:12px; font-family 设置文字的字体,如:font-family:'微 ...
- stack permutation
#include <iostream> #include <stack> #include <queue> using namespace std; bool ch ...
- Linux中将端口(80)重定向
在Linux中直接指定命令: iptables -t nat -A PREROUTING -p tcp --dport 80 -j REDIRECT --to-port 8080 其中80为要访问的端 ...
- 一道关于js正则表达式的面试题
这道面试题明显是要用到正则表达式来解决的,由于太久没有写正则表达式了,一时之间竟然写不出来,所以记录一下笔记,下面直接上代码: function parseUrl(str) { // 判断是否传入参数 ...
- H5新增的标签以及改良的标签
1>OL标签的改良 start type reversed:翻转排序 2>datalist标签自动补全的使用 3>progress标签的使用:进度条 4>meter标签的应用 ...
- Pagination
using System.Collections.Generic; namespace Oyang.Tool { public interface IPagination { int PageInde ...
- Android中,子线程使用主线程中的组件出现问题的解决方法
Android中,主线程中的组件,不能被子线程调用,否则就会出现异常. 这里所使用的方法就是利用Handler类中的Callback(),接受线程中的Message类发来的消息,然后把所要在线程中执行 ...