step4: Xpath的使用
XPath 是一门在 XML 文档中查找信息的语言。XPath 可用来在 XML 文档中对元素和属性进行遍历。
XPath 包含一个标准函数库。
XPath 是一个 W3C 标准。
语法简介:
http://www.runoob.com/xpath/xpath-syntax.html
节点介绍:
父节点/子节点/同胞节点/先辈节点/后代节点
语法:
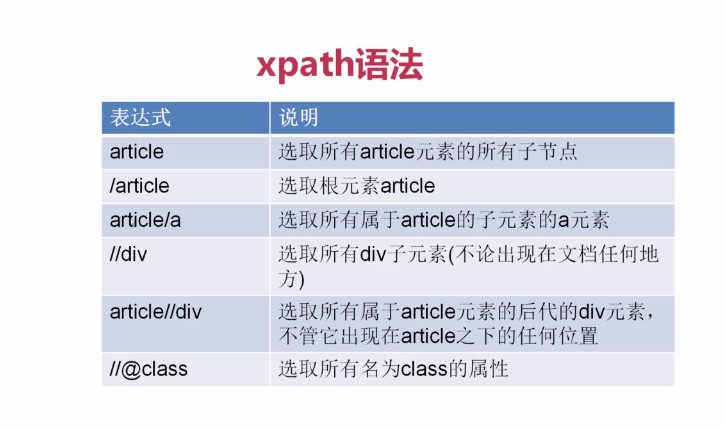
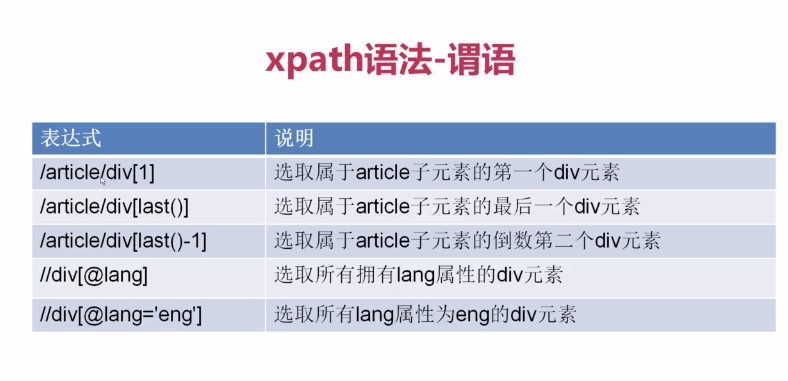
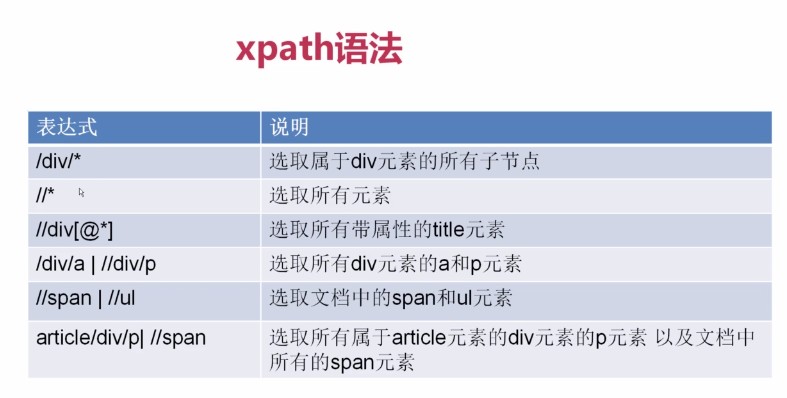
提取title
#这里注意修改start_urls
def parse(self, response):
title1 = response.xpath("/html/body/div[3]/div[3]/div[1]/div[1]/h1") #这里根据网页源码第一个div应为1
#title2 = response.xpath('//*[@id="post-112265"]/div[1]/h1/text()')
title = response.xpath('//div[@class="entry-header"]/h1/text()').extract()[0] #extract提取为数组,然后获取第一个值
断点调试与scrapy shell

提取时间
date = response.xpath("//p[@class='entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","")
#strip()去换行,空格
提取点赞数
#提取不到值
praise_num = response.xpath("//span[@class='vote-post-up']")
#引出contains函数并向下取一层h10标签,输出数组第一个值
praise_num = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
提取正文内容
#获取属性为entry的标签内容
content = response.xpath("//div[@class='entry']").extract()[0]
step4: Xpath的使用的更多相关文章
- 利用cookies+requests包登陆微博,使用xpath抓取目标用户的用户信息、微博以及对应评论
本文目的:介绍如何抓取微博内容,利用requests包+cookies实现登陆微博,lxml包的xpath语法解析网页,抓取目标内容. 所需python包:requests.lxml 皆使用pip安装 ...
- 找xpath好用的工具(比较少用,针对只能在IE上打开的网站)
有一些网站只能在IE浏览器里打开,不像firefox那样有好多好用的插件来找元素的xpath,css path等. 当然现在IE也可以,F12出现像firebug那样的窗口,来查看元素. 这里呢在介绍 ...
- firefox浏览器写xpath
最近在学xpath发现Firefox浏览器不支持xpath定位页面元素 百度为例: F12 页面前端代码 输入最简单的xpath发现并不能定位元素 解决方案:添加 Try Xpath 这个插件,因为 ...
- Python3 Selenium自动化web测试 ==> 第十节 WebDriver高级应用 -- xpath语法
学习目的: xpath定位是针对常规定位方法中,最有效的定位方式. 场景: 页面元素的定位. 正式步骤: step1:常规属性 示例UI 示例UI相关HTML代码 相关代码示例: #通过id定位 dr ...
- xpath提取多个标签下的text
title: xpath提取多个标签下的text author: 青南 date: 2015-01-17 16:01:07 categories: [Python] tags: [xpath,Pyth ...
- C#+HtmlAgilityPack+XPath带你采集数据(以采集天气数据为例子)
第一次接触HtmlAgilityPack是在5年前,一些意外,让我从技术部门临时调到销售部门,负责建立一些流程和寻找潜在客户,最后在阿里巴巴找到了很多客户信息,非常全面,刚开始是手动复制到Excel, ...
- 在Java中使用xpath对xml解析
xpath是一门在xml文档中查找信息的语言.xpath用于在XML文档中通过元素和属性进行导航.它的返回值可能是节点,节点集合,文本,以及节点和文本的混合等.在学习本文档之前应该对XML的节点,元素 ...
- XPath 学习二: 语法
XPath 使用路径表达式来选取 XML 文档中的节点或节点集.节点是通过沿着路径 (path) 或者步 (steps) 来选取的. 下面列出了最有用的路径表达式: 表达式 描述 nodename 选 ...
- xpath 学习一: 节点
xpath 中,有七种类型的节点: 元素.属性.文本.命名空间.处理指令.注释.以及根节点 树的根成为文档节点或者根节点. 节点关系: Parent, Children, sibling(同胞), A ...
随机推荐
- Transaction And Lock--存储过程中使用事务的模板
某公司内部使用的模板 create procedure [usp_my_procedure_name] as begin set nocount on; declare @trancount int; ...
- Replication--发布属性immediate_sync
在创建发布时,如果选择立即初始化,会将immediate_sync属性设置为true.如果immediate_sync属性为true时,snapshot文件和发布事务及发布命令将一直保留到指定的事务保 ...
- Ocelot Consul ACL
Ocelot允许您指定服务发现提供程序,并使用它来查找Ocelot正在将请求转发给下游服务的主机和端口.目前,这仅在GlobalConfiguration部分中受支持,这意味着所有ReRoute将使用 ...
- Consul .netcore
0)基本概念 consul常用于服务发现 [微服务] web_Api \ \ ->注册服务 raft选举le ...
- C# 等待框
今天发现dev控件自带了等待框,调用方便,而且不会阻塞主线程. 拉一个窗体,界面上放两个按钮,显示等待框,隐藏. <Window x:Class="WaitDialogTest.Mai ...
- ajax 多个setInterval进行ajax请求的页面长时间打开会出现页面卡死问题
多个setInterval进行ajax请求的页面长时间打开会出现页面卡死问题 浏览器的渲染(UI)线程和js线程是互斥的,在执行js耗时操作时,页面渲染会被阻塞掉.当我们执行异步ajax的时候没有问 ...
- ASP.NET Core ASP.NET Core+MVC搭建及部署
ASP.NET Core+MVC搭建及部署 一.创建项目: 1.选择ASP.NET Core Web Application(.NET Core) 注意框架 2.选择Web Application: ...
- emacs 考场配置
先存在这里,免得等回来乱搞的时候把自己的配置搞丢了qwq (custom-set-variables '(custom-enabled-themes (quote (tango-dark)))) (c ...
- c++实验4 栈及栈的应用+回文+中、后缀表达式
栈及栈的应用+回文+中.后缀表达式 1.栈顺序存储结构的基本操作算法实现 (1)栈顺序存储结构的类定义: class SeqStack { private: int maxsize; DataType ...
- OCP 12c最新考试原题及答案(071-8)
8.(5-4) choose the best answer:You need to produce a report where each customer's credit limit has b ...