Hive(8)-常用查询函数
一. 空字段赋值
1. 函数说明
NVL:给值为NULL的数据赋值,它的格式是NVL( value,default_value)。它的功能是如果value为NULL,则NVL函数返回default_value的值,否则返回value的值,如果两个参数都为NULL ,则返回NULL。
2. 案例
-- 如果员工的comm为NULL,则用-1代替
select comm,nvl(comm, -1) from emp;
-- 如果员工的comm为NULL,则用领导id代替
select comm, nvl(comm,mgr) from emp;
二. case when
1. 函数说明

2. 案例

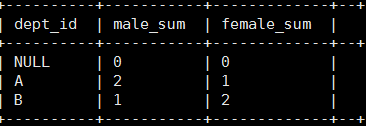
-- 求出不同部门男女各多少人
select dept_id,
sum(case sex when '男' then 1 else 0 end) male_sum,
sum(case sex when '女' then 1 else 0 end) female_sum
from emp_sex
group by dept_id;
三. 行转列(concat)
1. 函数说明
CONCAT(string A/col, string B/col…):返回输入字符串连接后的结果,支持任意个输入字符串;
CONCAT_WS(separator, str1, str2,...):它是一个特殊形式的 CONCAT()。第一个参数是剩余参数间的分隔符。分隔符可以是与剩余参数一样的字符串。如果分隔符是 NULL,返回值也将为 NULL。这个函数会跳过分隔符参数后的任何 NULL 和空字符串。分隔符将被加到被连接的字符串之间;
COLLECT_SET(col):函数只接受基本数据类型,它的主要作用是将某字段的值进行去重汇总,产生array类型字段。
2.案例

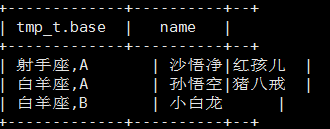
将血型和星座一样的归类到一起
select tmp_t.base, concat_ws("|",collect_set(tmp_t.name)) name
from(
select concat(constellation,",",blood_type) base, name from person_info
) tmp_t
group by tmp_t.base;
四. 列转行(explode)
1.函数说明

EXPLODE(col):将hive一列中复杂的array或者map结构拆分成多行。
LATERAL VIEW :
用法:LATERAL VIEW udtf(expression) tableAlias AS columnAlias
解释:用于和split, explode等UDTF一起使用,它能够将一列数据拆成多行数据,在此基础上可以对拆分后的数据进行聚合。
2.案例
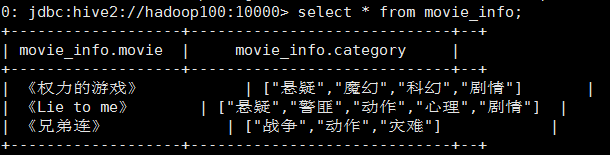
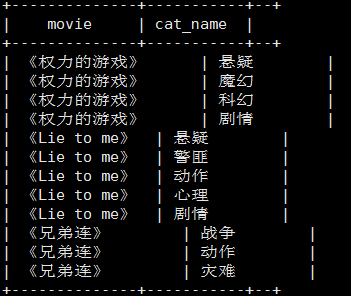
将电影分类中的数组数据展开
select movie, cat_name
from
movie_info lateral view explode(category) exp_tbl as cat_name;
五. 窗口函数(开窗函数)
1. 语法
UDAF() over (PARTITION By col1,col2 order by col3 窗口子句(rows between .. and ..)) AS 列别名
注意:PARTITION By后可跟多个字段,order By只跟一个字段。
2. 函数说明
over()决定了聚合函数的聚合范围,默认对整个窗口中的数据进行聚合,聚合函数对每一条数据调用一次。
partition by子句:使用Partiton by子句对数据进行分区,可以用paritition by对区内的进行聚合。
order by子句作用:对分区中的数据进行排序;确定聚合哪些行(默认从起点到当前行的聚合)
窗口子句
CURRENT ROW:当前行
n PRECEDING:往前n行数据
n FOLLOWING:往后n行数据
UNBOUNDED:起点,UNBOUNDED PRECEDING 表示从前面的起点, UNBOUNDED FOLLOWING表示到后面的终点
LAG(col,n,default_val):往前第n行数据
LEAD(col,n, default_val):往后第n行数据
NTILE(n):把有序分区中的行分发到指定数据的组中,各个组有编号,编号从1开始,对于每一行,NTILE返回此行所属的组的编号。注意:n必须为int类型。
tips:
通过使用partition by子句将数据进行了分区。如果想要对窗口进行更细的动态划分,就要引入窗口子句。
order by必须跟在partition by后;Rows必须跟在Order by子;(partition by .. order by)可替换为(distribute by .. sort by ..)
什么时候用开窗函数?
开窗函数常结合聚合函数使用,一般来讲聚合后的行数要少于聚合前的行数,但是有时我们既想显示聚集前的数据,
又要显示聚集后的数据,这时我们便引入了窗口函数.
3.案例

1). 查询在2017年4月份购买过的顾客及总人数
select name, count(1) over()
from business
where orderdate like "2017-04-%"
group by name;

2). 查询顾客的购买明细及月购买总额
select name, orderdate, cost, sum(cost) over(partition by month(orderdate)) from business;
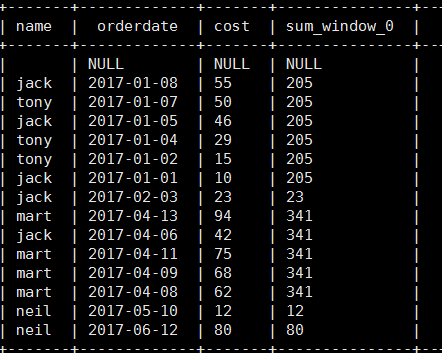
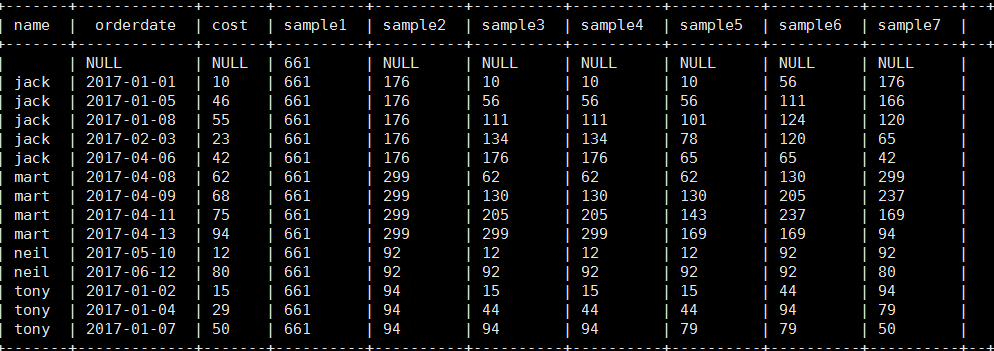
3). 将每个顾客的cost按照日期进行累加
select name,orderdate,cost,
sum(cost) over() as sample1,--所有行相加 sum(cost) over(partition by name) as sample2,--按name分组,组内数据相加 sum(cost) over(partition by name order by orderdate) as sample3,--按name分组,组内数据累加 sum(cost) over(partition by name order by orderdate rows between UNBOUNDED PRECEDING and current row ) as sample4 ,--和sample3一样,由起点到当前行的聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING and current row) as sample5, --当前行和前面一行做聚合 sum(cost) over(partition by name order by orderdate rows between 1 PRECEDING AND 1 FOLLOWING ) as sample6,--当前行和前边一行及后面一行 sum(cost) over(partition by name order by orderdate rows between current row and UNBOUNDED FOLLOWING ) as sample7 --当前行及后面所有行 from business;
4). 查看顾客上次的购买时间
select name,orderdate,cost,
lag(orderdate,1,'first_buy') over(partition by name order by orderdate )
from business;

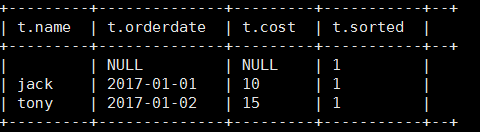
5). 查询前20%时间的订单信息
select * from (
select name,orderdate,cost, ntile(5) over(order by orderdate) sorted
from business
) t
where sorted = 1;
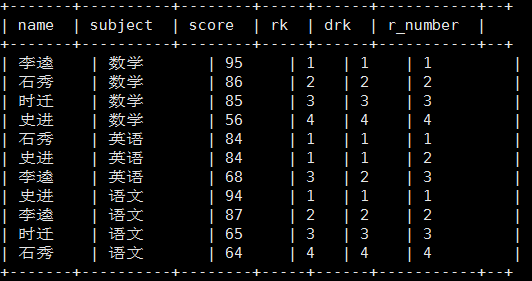
六. Rank
1.函数说明
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
2. 案例

计算每门学科成绩排名
select name, subject, score,
rank() over(partition by subject order by score desc) rk,
dense_rank() over(partition by subject order by score desc) drk,
row_number() over(partition by subject order by score desc) r_number
from score;
Hive(8)-常用查询函数的更多相关文章
- HIVE之常用字符串函数
可以参考: 博文 : https://www.iteblog.com/archives/1639.html
- Hive SQL 常用日期
Hive SQL 常用日期 原文地址:Hive SQL常用日期函数 Hive SQL 常用日期 注意: MM DD MO TU等要大写 已知日期 要求日期 语句 结果 本周任意一天 本周一 selec ...
- oracle(sql)基础篇系列(一)——基础select语句、常用sql函数、组函数、分组函数
花点时间整理下sql基础,温故而知新.文章的demo来自oracle自带的dept,emp,salgrade三张表.解锁scott用户,使用scott用户登录就可以看到自带的表. #使用ora ...
- php常用数组函数回顾一
数组对于程序开发来说是一个必不可少的工具,我根据网上的常用数组函数,结合个人的使用情况,进行数组系列的总结复习.里面当然不只是数组的基本用法,还有相似函数的不同用法的简单实例,力求用最简单的实例,记住 ...
- iOS开发数据库篇—SQLite常用的函数
iOS开发数据库篇—SQLite常用的函数 一.简单说明 1.打开数据库 int sqlite3_open( const char *filename, // 数据库的文件路径 sqlite3 * ...
- 23个MySQL常用查询语句
23个MySQL常用查询语句 一查询数值型数据: SELECT * FROM tb_name WHERE sum > 100; 查询谓词:>,=,<,<>,!=,!> ...
- (转)WordPress的主查询函数-query_posts()
今天说说WordPress 的主查询函数 -query_posts(),因为我正在制作的主题里面多次用到了这个函数 . query_posts()查询函数决定了哪些文章出现在WordPress 主 循 ...
- PLSQL常用时间函数
body { font-family: "Microsoft YaHei UI","Microsoft YaHei",SimSun,"Segoe UI ...
- 常用分组函数count-avg-sum-max-min
分组函数也称多行函数,用于对一组数据进行运算,针对一组数据(取自于多行记录的相同字段)只返回一个结果,例如计算公司全体员工的工资总和.最高工资.最低工资.各部门的员工平均工资(按部门分组)等.由于分组 ...
随机推荐
- 使用webBrowser下载文件
如果直接用webBrowser.Navigate("http://***.com/");会弹出文件下载的对话框. 而如果用webclient.UploadData()下载,对方网站 ...
- Service Discovery in WCF 4.0 – Part 1 z
Service Discovery in WCF 4.0 – Part 1 When designing a service oriented architecture (SOA) system, t ...
- QT的键值对应关系 看完开发节省时间 哈哈
http://blog.csdn.net/wangjieest/article/details/8283656
- 运维不仅仅是懂Linux就行,还需要知道这些……
运维不仅仅是懂Linux就行,因为还有一大部分的Windows运维,最近看一个报道说,windows的服务器占了47.71%.嗯,向windows运维人员致敬.当然我们这篇文章不是说运维除了懂Linu ...
- 设置dedecms标签 [field:global.autoindex/] 初始值{class递增}
在{dede:arclist/}这个标签中有个[field:global.autoindex/],是从0开始自增,如果我们想自定义一个数值,比如自定义从2开始.那么就可以写成下面代码: [field: ...
- 巧用padding生成正方形DIV
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- redis三节点sentinel部署
角色 ip port master 127.0.0.1 6379 slave-1 127.0.0.1 6380 slave-2 127. ...
- 理解Underscore的设计架构
在一个多月的毕业设计之后,我再次开始了Underscore的源码阅读学习,断断续续也写了好些篇文章了,基本把一些比较重要的或者个人认为有营养的函数都解读了一遍,所以现在学习一下Underscore的整 ...
- IntelliJ IDEA 运行你的第一个Java应用程序
IntelliJ IDEA 运行你的第一个Java应用程序创建项目让我们创建一个简单的Java Hello World项目. 单击创建新的项目. 打开新建项目向导.你应该注意的主要是项目的SDK.SD ...
- springMVC框架下返回json格式的对象,list,map
原文地址:http://liuzidong.iteye.com/blog/1069343 注意这个例子要使用jQuery,但是jquery文件属于静态的资源文件,所以要在springMVC中设置静态资 ...