【Python】我的豆瓣短评爬虫的多线程改写
对之前我的那个豆瓣的短评的爬虫,进行了一下架构性的改动。尽可能实现了模块的分离。但是总是感觉不完美。暂时也没心情折腾了。
同时也添加了多线程的实现。具体过程见下。
改动
独立出来的部分:
- MakeOpener
- MakeRes
- GetNum
- IOFile
- GetSoup
- main
将所有的代码都置于函数之中,显得干净了许多。(__) 嘻嘻……
使用直接调用文件入口作为程序的起点
if __name__ == "__main__":
main()
注意,这一句并不代表如果该if之前有其他直接暴露出来的代码时,他会首先执行。
print("首先执行")
if __name__ == "__main__":
print("次序执行")
# 输出如下:
# 首先执行
# 次序执行
该if语句只是代表顺序执行到这句话时进行判断调用者是谁,若是直接运行的该文件,则进入结构,若是其他文件调用,那就跳过。
多线程
这里参考了【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top,和我的情况较为类似,参考较为容易。
仔细想想就可以发现,其实爬10页(每页25本),这10页爬的先后关系是无所谓的,因为写入的时候没有依赖关系,各写各的,所以用串行方式爬取是吃亏的。显然可以用并发来加快速度,而且由于没有同步互斥关系,所以连锁都不用上。
正如引用博文所说,由于问题的特殊性,我用了与之相似的较为直接的直接分配给各个线程不同的任务,而避免了线程交互导致的其他问题。
我的代码中多线程的核心代码不多,见下。
thread = []
for i in range(0, 10):
t = threading.Thread(
target=IOFile,
args=(soup, opener, file, pagelist[i], step)
)
thread.append(t)
# 建立线程
for i in range(0, 10):
thread[i].start()
for i in range(0, 10):
thread[i].join()
调用线程库threading,向threading.Thread()类中传入要用线程运行的函数及其参数。
线程列表依次添加对应不同参数的线程,pagelist[i],step两个参数是关键,我是分别为每个线程分配了不同的页面链接,这个地方我想了半天,最终使用了一些数学计算来处理了一下。
同时也简单试用了下列表生成式:
pagelist = [x for x in range(0, pagenum, step)]
这个和下面是一致的:
pagelist = []
for x in range(0, pagenum, step):
pagelist.append(x)
threading.Thread的几个方法
值得参考:多线程
- start() 启动线程
- jion([timeout]),依次检验线程池中的线程是否结束,没有结束就阻塞直到线程结束,如果结束则跳转执行下一个线程的join函数。在程序中,最后join()方法使得当所调用线程都执行完毕后,主线程才会执行下面的代码。相当于实现了一个结束上的同步。这样避免了前面的线程结束任务时,导致文件关闭。
注意
使用多线程时,期间的延时时间应该设置的大些,不然会被网站拒绝访问,这时你还得去豆瓣认证下"我真的不是机器人"(尴尬)。我设置了10s,倒是没问题,再小些,就会出错了。
完整代码
# -*- coding: utf-8 -*-
"""
Created on Thu Aug 17 16:31:35 2017
@note: 为了便于阅读,将模块的引用就近安置了
@author: lart
"""
import time
import socket
import re
import threading
from urllib import parse
from urllib import request
from http import cookiejar
from bs4 import BeautifulSoup
from matplotlib import pyplot
from datetime import datetime
# 用于生成短评页面网址的函数
def MakeUrl(start):
"""make the next page's url"""
url = 'https://movie.douban.com/subject/26934346/comments?start=' \
+ str(start) + '&limit=20&sort=new_score&status=P'
return url
def MakeOpener():
"""make the opener of requset"""
# 保存cookies便于后续页面的保持登陆
cookie = cookiejar.CookieJar()
cookie_support = request.HTTPCookieProcessor(cookie)
opener = request.build_opener(cookie_support)
return opener
def MakeRes(url, opener, formdata, headers):
"""make the response of http"""
# 编码信息,生成请求,打开页面获取内容
data = parse.urlencode(formdata).encode('utf-8')
req = request.Request(
url=url,
data=data,
headers=headers
)
response = opener.open(req).read().decode('utf-8')
return response
def GetNum(soup):
"""get the number of pages"""
# 获得页面评论文字
totalnum = soup.select("div.mod-hd h2 span a")[0].get_text()[3:-2]
# 计算出页数
pagenum = int(totalnum) // 20
print("the number of comments is:" + totalnum,
"the number of pages is: " + str(pagenum))
return pagenum
def IOFile(soup, opener, file, pagestart, step):
"""the IO operation of file"""
# 循环爬取内容
for item in range(step):
start = (pagestart + item) * 20
print('第' + str(pagestart + item) + '页评论开始爬取')
url = MakeUrl(start)
# 超时重连
state = False
while not state:
try:
html = opener.open(url).read().decode('utf-8')
state = True
except socket.timeout:
state = False
# 获得评论内容
soup = BeautifulSoup(html, "html.parser")
comments = soup.select("div.comment > p")
for text in comments:
file.write(text.get_text().split()[0] + '\n')
print(text.get_text())
# 延时1s
time.sleep(10)
print('线程采集写入完毕')
def GetSoup():
"""get the soup and the opener of url"""
main_url = 'https://accounts.douban.com/login?source=movie'
formdata = {
"form_email": "your-email",
"form_password": "your-password",
"source": "movie",
"redir": "https://movie.douban.com/subject/26934346/",
"login": "登录"
}
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 5.1; U; en; rv:1.8.1)\
Gecko/20061208 Firefox/2.0.0 Opera 9.50",
'Connection': 'keep-alive'
}
opener = MakeOpener()
response_login = MakeRes(main_url, opener, formdata, headers)
soup = BeautifulSoup(response_login, "html.parser")
if soup.find('img', id='captcha_image'):
print("有验证码")
# 获取验证码图片地址
captchaAddr = soup.find('img', id='captcha_image')['src']
# 匹配验证码id
reCaptchaID = r'<input type="hidden" name="captcha-id" value="(.*?)"/'
captchaID = re.findall(reCaptchaID, response_login)
# 下载验证码图片
request.urlretrieve(captchaAddr, "captcha.jpg")
img = pyplot.imread("captcha.jpg")
pyplot.imshow(img)
pyplot.axis('off')
pyplot.show()
# 输入验证码并加入提交信息中,重新编码提交获得页面内容
captcha = input('please input the captcha:')
formdata['captcha-solution'] = captcha
formdata['captcha-id'] = captchaID[0]
response_login = MakeRes(main_url, opener, formdata, headers)
soup = BeautifulSoup(response_login, "html.parser")
return soup, opener
def main():
"""main function"""
timeout = 5
socket.setdefaulttimeout(timeout)
now = datetime.now()
soup, opener = GetSoup()
pagenum = GetNum(soup)
step = pagenum // 9
pagelist = [x for x in range(0, pagenum, step)]
print('pageurl`s list={}, step={}'.format(pagelist, step))
# 追加写文件的方式打开文件
with open('秘密森林的短评.txt', 'w+', encoding='utf-8') as file:
thread = []
for i in range(0, 10):
t = threading.Thread(
target=IOFile,
args=(soup, opener, file, pagelist[i], step)
)
thread.append(t)
# 建立线程
for i in range(0, 10):
thread[i].start()
for i in range(0, 10):
thread[i].join()
end = datetime.now()
print("程序耗时: " + str(end-now))
if __name__ == "__main__":
main()
运行结果
效率有提升
对应的单线程程序在github上。单线程:
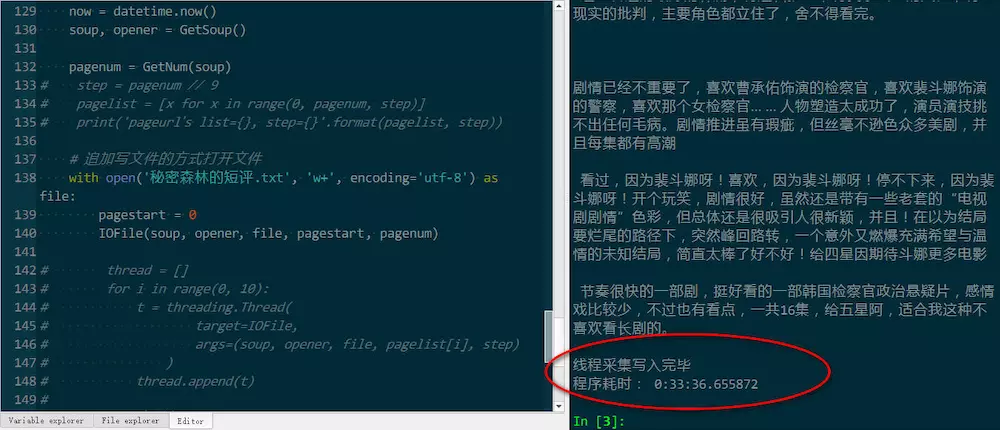
可见时间超过30分钟。修改后时间缩短到了11分钟。
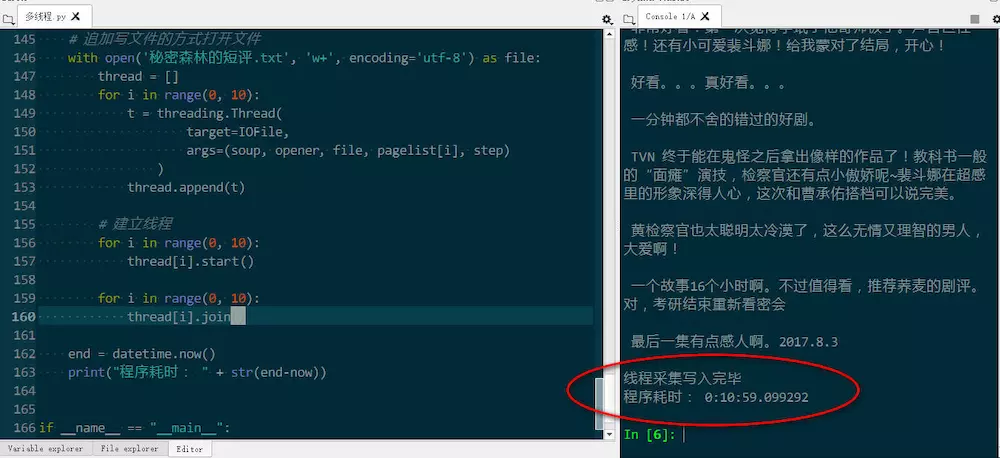
文件截图
我的项目
具体文件和对应的结果截图我放到了我的github上。
【Python】我的豆瓣短评爬虫的多线程改写的更多相关文章
- 【Python】我的第一个豆瓣短评爬虫
写在开头 豆瓣上有着大量的影视剧的评论,所以说,要是想要实现对广大人民群众的观点的分析,对一部片子的理解,综合来看大家的评论是很有必要的.而短评作为短小精干的快速评论入口,是值得一谈的. 所以先要实现 ...
- 用python写一个豆瓣短评通用爬虫(登录、爬取、可视化)
原创技术公众号:bigsai,本文在1024发布,祝大家节日快乐,心想事成. @ 目录 前言 登录 爬取 储存 可视化分析 前言 在本人上的一门课中,老师对每个小组有个任务要求,介绍和完成一个小模块. ...
- 【Python】利用豆瓣短评数据生成词云
在之前的文章中,我们获得了豆瓣爬取的短评内容,汇总到了一个文件中,但是,没有被利用起来的数据是没有意义的. 前文提到,有一篇微信推文的关于词云制作的一个实践记录,准备照此试验一下. 思路分析 读文件 ...
- Java豆瓣电影爬虫——抓取电影详情和电影短评数据
一直想做个这样的爬虫:定制自己的种子,爬取想要的数据,做点力所能及的小分析.正好,这段时间宝宝出生,一边陪宝宝和宝妈,一边把自己做的这个豆瓣电影爬虫的数据采集部分跑起来.现在做一个概要的介绍和演示. ...
- Python爬取豆瓣指定书籍的短评
Python爬取豆瓣指定书籍的短评 #!/usr/bin/python # coding=utf-8 import re import sys import time import random im ...
- 哪吒票房超复联4,100行python代码抓取豆瓣短评,看看网友怎么说
<哪吒之魔童降世>这部国产动画巅峰之作,上映快一个月时间,票房口碑双丰收. 迄今已有超一亿人次观看,票房达到42.39亿元,超过复联4,跻身中国票房纪录第三名,仅次于<战狼2> ...
- python爬虫之多线程、多进程+代码示例
python爬虫之多线程.多进程 使用多进程.多线程编写爬虫的代码能有效的提高爬虫爬取目标网站的效率. 一.什么是进程和线程 引用廖雪峰的官方网站关于进程和线程的讲解: 进程:对于操作系统来说,一个任 ...
- 12行Python暴力爬《黑豹》豆瓣短评
作者:黄嘉锋 来源:https://www.jianshu.com/p/ea0b56e3bd86 草长莺飞,转眼间又到了三月"爬虫月".这时往往不少童鞋写论文苦于数据获取艰难,辗转 ...
- Python爬取《你好李焕英》豆瓣短评并基于SnowNLP做情感分析
爬取过程在这里: Python爬取你好李焕英豆瓣短评并利用stylecloud制作更酷炫的词云图 本文基于前文爬取生成的douban.txt,基于SnowNLP做情感分析. 依赖库: 豆瓣镜像比较快: ...
随机推荐
- 如何使用windows performance recorder
先下载WPA TOOLS:从该地址下载,选最新的版本,然后可以只选择下载WPA工具 后面编写XML文件等等,可以参考这篇文章. 需要注意: 用管理员启动cmd后,如果想运行特定路径的文件,需要带上绝对 ...
- oracle查询语句执行顺序
完整的查询语句类似是这样的: select ..., ROWNUM from table where <where clause> group by <columns> hav ...
- iOS消息通知Notification的用法
1.发送消息 NSNotification *notification = [NSNotification notificationWithName:@"selectPosition&quo ...
- 016:URL命名与反转URL
为什么需要URL命名? 主要解决蛋疼url变化情况,比如:哪天项目经理或领导过来说,把login改成signin,把register改成signup等蛋疼的需求——因为一旦改了url后,相关视图函数里 ...
- Spoj4060 game with probability Problem
题目链接:Click here Solution: 刚开始还以为博弈论加概率,然而并不是... 设两个状态:\(f(i)\)表示当前剩下\(i\)个石头时,先手的获胜概率,\(g(i)\)为后手的获胜 ...
- Java 内置锁 重入问题
阅读<Java并发编程实战>,遇到了一个问题 代码如下 /** * @auther draymonder */ public class Widget { public synchroni ...
- FJWC2017&FJOI2017一试 游记
day1 早上是以前泉州七中的杨国烨讲课.(据说当时看新闻说是一对双胞胎一起上thu的其中一个)课题是图论/网络流. 下午第一道一开始推出来了一个之和面积有关的式子,然后觉得可以容斥一发,觉得 ...
- hihoCoder #1558 : H国的身份证号码I
题目链接:https://hihocoder.com/problemset/problem/1558 H国的身份证号码I 时间限制:10000ms 单点时限:1000ms 内存限制:256MB 描述 ...
- HDU3398—String-(组合数)
Problem Description Recently, lxhgww received a task : to generate strings contain '0's and '1's onl ...
- Spring Data JPA(一)简介
Spring Data JPA介绍 可以理解为JPA规范的再次封装抽象,底层还是使用了Hibernate的JPA技术实现,引用JPQL(Java Persistence Query Language) ...