mysql 大数据分页优化
一、mysql大数据量使用limit分页,随着页码的增大,查询效率越低下。
1. 直接用limit start, count分页语句, 也是我程序中用的方法:
select * from product limit start, count
当起始页较小时,查询没有性能问题,我们分别看下从10, 100, 1000, 10000开始分页的执行时间(每页取20条), 如下:
select * from product limit 10, 20 0.016秒
select * from product limit 100, 20 0.016秒
select * from product limit 1000, 20 0.047秒
select * from product limit 10000, 20 0.094秒
我们已经看出随着起始记录的增加,时间也随着增大, 这说明分页语句limit跟起始页码是有很大关系的,那么我们把起始记录改为40w看下(也就是记录的一半左右)
select * from product limit 400000, 20 3.229秒
再看我们取最后一页记录的时间
select * from product limit 866613, 20 37.44秒
难怪搜索引擎抓取我们页面的时候经常会报超时,像这种分页最大的页码页显然这种时
间是无法忍受的。
从中我们也能总结出两件事情:
1)limit语句的查询时间与起始记录的位置成正比
2)mysql的limit语句是很方便,但是对记录很多的表并不适合直接使用。
2. 对limit分页问题的性能优化方法
利用表的覆盖索引来加速分页查询
我们都知道,利用了索引查询的语句中如果只包含了那个索引列(覆盖索引),那么这种情况会查询很快。
因为利用索引查找有优化算法,且数据就在查询索引上面,不用再去找相关的数据地址了,这样节省了很多时间。另外Mysql中也有相关的索引缓存,在并发高的时候利用缓存就效果更好了。
在我们的例子中,我们知道id字段是主键,自然就包含了默认的主键索引。现在让我们看看利用覆盖索引的查询效果如何:
这次我们之间查询最后一页的数据(利用覆盖索引,只包含id列),如下:
select id from product limit 866613, 20 0.2秒
相对于查询了所有列的37.44秒,提升了大概100多倍的速度
那么如果我们也要查询所有列,有两种方法,
(1)一种是id>=的形式,另一种就是利用join,看下实际情况:
SELECT * FROM product WHERE ID > =(select id from product limit 866613, 1) limit 20
查询时间为0.2秒,简直是一个质的飞跃啊,哈哈
(2)另一种写法
SELECT * FROM product a JOIN (select id from product limit 866613, 20) b ON a.ID = b.id
查询时间也很短,赞!
其实两者用的都是一个原理嘛,所以效果也差不多
二、覆盖索引
1、定义:
(1)如果一个索引包含(或覆盖)所有需要查询的字段的值,称为‘覆盖索引’。即只需扫描索引而无须回表。
(2)只扫描索引而无需回表的优点:
1)索引条目通常远小于数据行大小,只需要读取索引,则mysql会极大地减少数据访问量。
2)因为索引是按照列值顺序存储的,所以对于IO密集的范围查找会比随机从磁盘读取每一行数据的IO少很多。
3)一些存储引擎如myisam在内存中只缓存索引,数据则依赖于操作系统来缓存,因此要访问数据需要一次系统调用
4)innodb的聚簇索引,覆盖索引对innodb表特别有用。(innodb的二级索引在叶子节点中保存了行的主键值,所以如果二级主键能够覆盖查询,则可以避免对主键索引的二次查询)
(3)覆盖索引必须要存储索引列的值,而哈希索引、空间索引和全文索引不存储索引列的值,所以mysql只能用B-tree索引做覆盖索引。
当发起一个被索引覆盖的查询(也叫作索引覆盖查询)时,在EXPLAIN的Extra列可以看到“Using index”的信息

2、实验验证
表结构
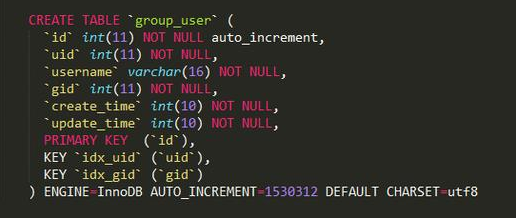
150多万的数据,这么一个简单的语句:

慢查询日志里居然很多用了1秒的,Explain的结果是:

从Explain的结果可以看出,查询已经使用了索引,但为什么还这么慢?
分析:首先,该语句ORDER BY 使用了Using filesort文件排序,查询效率低;其次,查询字段不在索引上,没有使用覆盖索引,需要通过索引回表查询;也有数据分布的原因。
知道了原因,那么问题就好解决了。
解决方案:由于只需查询uid字段,添加一个联合索引便可以避免回表和文件排序,利用覆盖索引提升查询速度,同时利用索引完成排序。

覆盖索引:SQL只需要通过索引就可以返回查询所需要的数据,而不必通过二级索引查到主键之后再去查询数据。
我们再Explain看一次:

Extra信息已经有'Using Index',表示已经使用了覆盖索引。经过索引优化之后,线上的查询基本不超过0.001秒。
部分内容来自于:https://www.cnblogs.com/lpfuture/p/5772055.html
mysql 大数据分页优化的更多相关文章
- MySQL大数据分页的优化思路和索引延迟关联
之前上次在部门的分享会上,听了关于MySQL大数据的分页,即怎样使用limit offset,N来进行大数据的分页,现在做一个记录: 首先我们知道,limit offset,N的时候,MySQL的查询 ...
- Mysql大数据表优化处理
原文链接: https://segmentfault.com/a/1190000006158186 当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表 ...
- mysql大数据表优化
1.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描. 2.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉 ...
- Mysql大范围分页优化案例
在BBS线上业务抓到如下分页SQL: meizu_bbs meizu_bbs Query Sending data , meizu_bbs meizu_bbs Query Sending data , ...
- mysql 大数据分页查询优化
应用场景: 当有一张表的数据非常大,需要使用到分页查询,分页查询在100w条后查询效率非常低: 解决方案: 1.业务层解决:只允许用户翻页一百页以内,十条一页: 2.使用where id > 5 ...
- 【1】MySQL大数据量分页查询方法及其优化
---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适应场景: 适用于数据量较少的情况(元组百/千 ...
- MySQL大数据量分页查询方法及其优化
MySQL大数据量分页查询方法及其优化 ---方法1: 直接使用数据库提供的SQL语句---语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N---适 ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- MySQL分页查询大数据量优化方法
方法1: 直接使用数据库提供的SQL语句 语句样式: MySQL中,可用如下方法: SELECT * FROM 表名称 LIMIT M,N适应场景: 适用于数据量较少的情况(元组百/千级)原因/缺点: ...
随机推荐
- awk-第一篇
awk [单独的编程语言解释器] 1.awk介绍 全称:Aho Weinberger Kernaighan三个人的首字母缩写: 1970年第一次出现在Unix机器上,后来在开源领域使用它: 所以,我们 ...
- 使用Eigen遇到恶心报错
参考博客:https://www.cnblogs.com/wongyi/p/8734346.html 1. 数据类型报错 /home/wy/workdir/slambook/ch3/useEigen/ ...
- 论文阅读:Stateless Network Functions: Breaking the Tight Coupling of State and Processing
摘要: 无状态网络功能是一个新的网络功能虚拟化架构,解耦了现有的网络功能设计到无状态处理组件以及数据存储层,在打破紧密耦合的同时,实现了更具可伸缩性和可恢复性的网络功能基础设施.无状态NF处理实例是围 ...
- 【转】毛虫算法——尺取法
转自http://www.myexception.cn/program/1839999.html 妹子满分~~~~ 毛毛虫算法--尺取法 有这么一类问题,需要在给的一组数据中找到不大于某一个上限的&q ...
- wannafly 练习赛11 B 假的字符串(字典树+建边找环)
链接:https://www.nowcoder.com/acm/contest/59/B 时间限制:C/C++ 1秒,其他语言2秒 空间限制:C/C++ 32768K,其他语言65536K 64bit ...
- iframe嵌套页面 跨域
父级调用iframe方法: document.getElementById("iframe").contentWindow.func(data1,data2...) 子级 ifra ...
- tomcat简单性能优化
1.内存使用配置 2.最大连接数配置
- sklearn—支持向量机
SVC介绍: 拟合出来的模型为一个超平面 解决与样本维数无关,适合做文本分类 解决小样本.非线性.高维 是用于分类.回归.孤立点检测的监督学习方法的集合. 优点: 有效的高维空间 维数大于样本数的时候 ...
- [VBA]斐波那契数列
Sub 斐波那契()Dim arrFor i = 3 To 100Cells(1, 1) = 0Cells(2, 1) = 1Cells(i, 1) = Cells(i - 1, 1) + Cells ...
- 阶段3 1.Mybatis_03.自定义Mybatis框架_7.自定义Mybatis的编码-实现基于注解配置的查询所有
注解的方式,这里进行修改.上面注释的是原来xml的方式. 在dao类里面加上注解 创建注解类 声明注解的生命周期为Runntime 改变注解出现的位置,在Mehtod方法上 写完之后这里就不报错了. ...