做一个简单的scrapy爬虫
前言:
做一个简单的scrapy爬虫,带大家认识一下创建scrapy的大致流程。我们就抓取扇贝上的单词书,python的高频词汇。
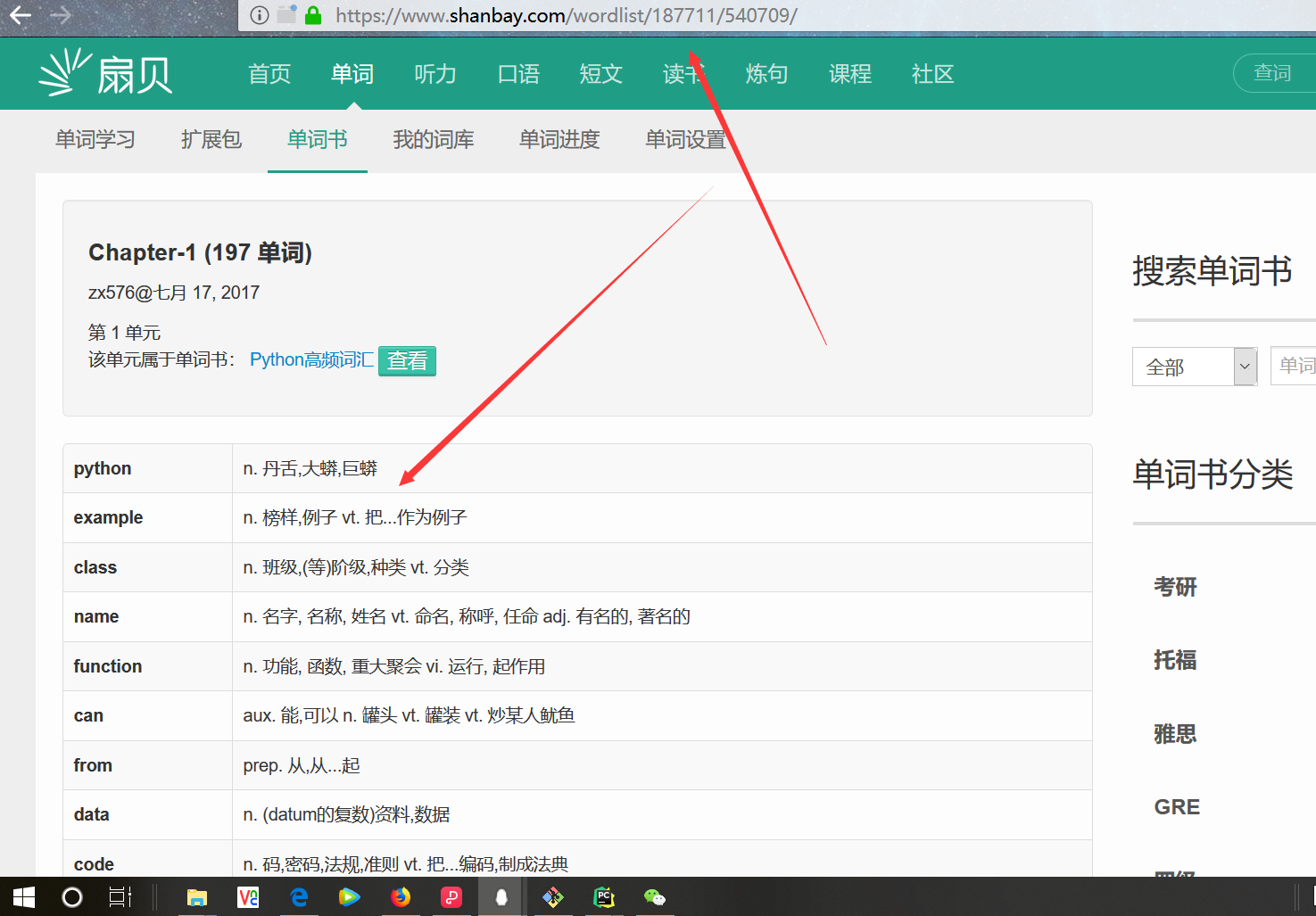
步骤:
一,新建一个工程scrapy_shanbay
二,在工程中中新建一个爬虫项目,scrapy startproject shanbei_spider
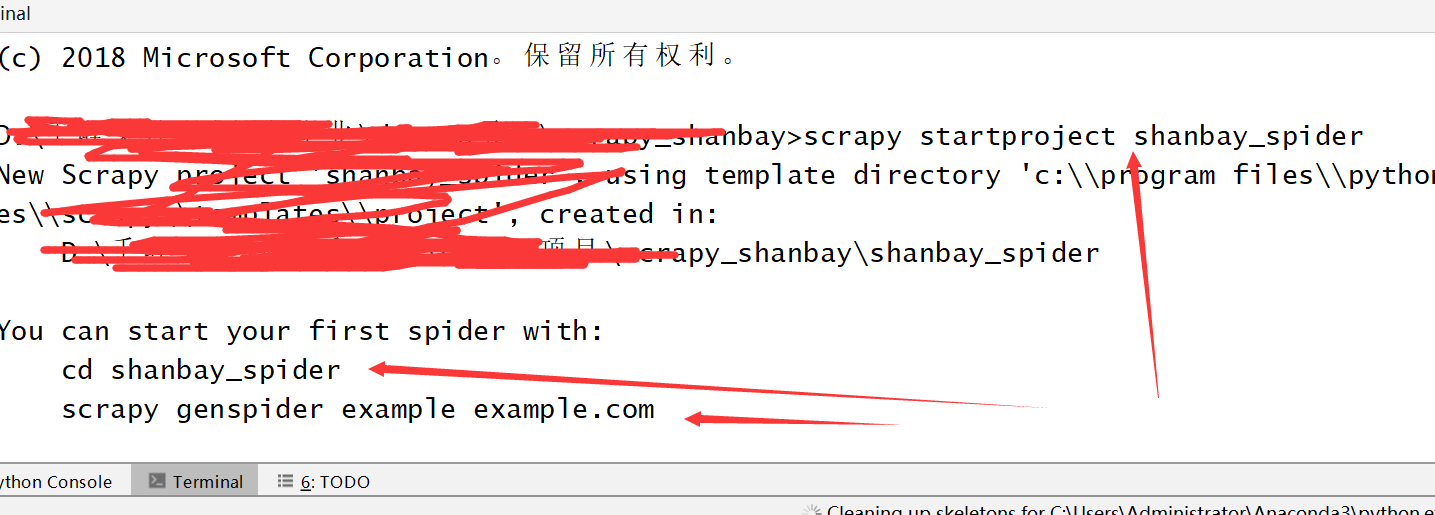
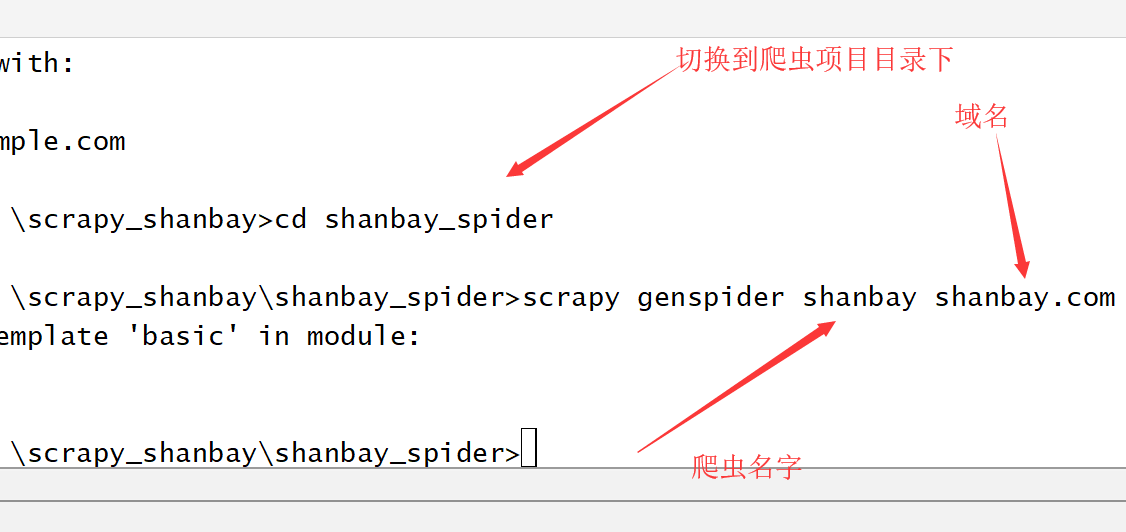
三,切入到项目目录下,然后在项目中,新建一个爬虫spider。scrapy crawl shanbay shanbay.com
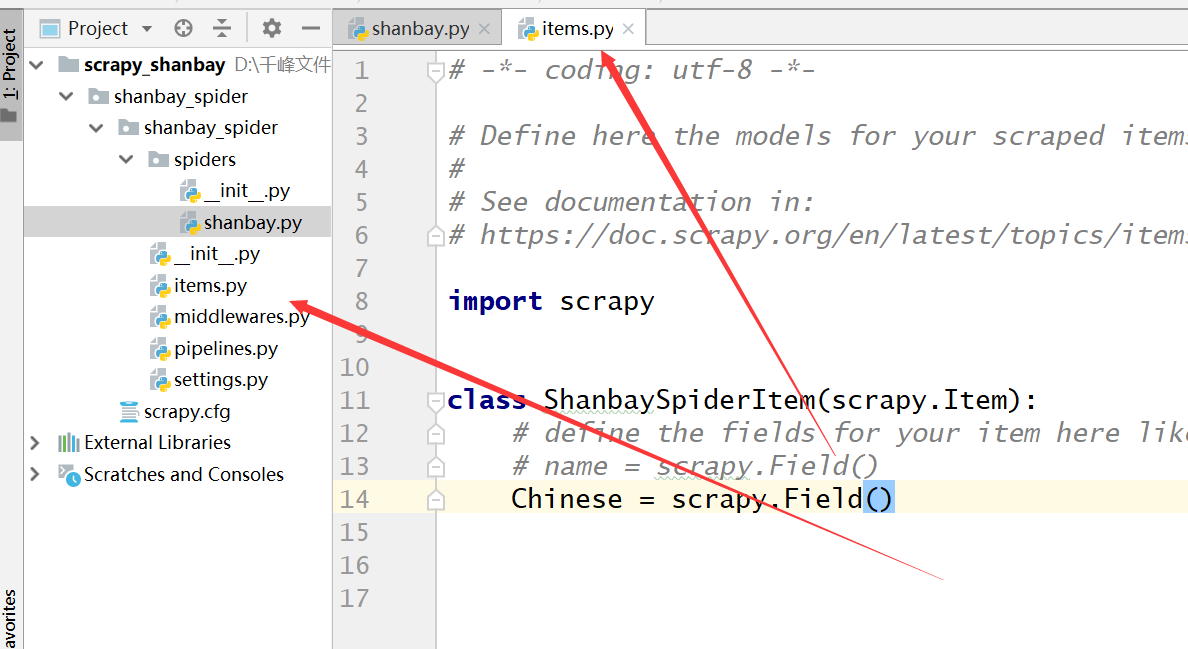
四,在item中,新建一个字段,既要获取的字段。
五,开始书写spider,里面分两部分,第一部分 start_request()主要是获取所有的url,第二部分是解析页面,获取所需要的字段,并存储。
import scrapy
from scrapy.http import Request
from shanbay_spider.items import ShanbaySpiderItem class ShanbaySpider(scrapy.Spider):
name = 'shanbay'
allowed_domains = ['shanbay.com']
# start_urls = ['http://shanbay.com/'] def start_requests(self):
for i in range():
page = + i *
url_base = 'https://www.shanbay.com/wordlist/187711/' + str(page) + '/?page={}'
for x in range():
url = url_base.format(x+ )
yield Request(url,self.parse) def parse(self, response):
html_contents = response.xpath('/html/body/div[3]/div/div[1]/div[2]/div/table/tbody/tr//*/text()')
item = ShanbaySpiderItem() for result in html_contents: item['Chinese'] = result.extract()
yield item
六,执行运行保存命令,scrapy crawl shanbay -o shanbay.csv

七,东西都保存在shanbay.csv中了
总结,其实这个非常简单,但是你用scrapy你会明显感觉到比requests快的很多。而且相比于requests库,你发现用scrapy会很简单。比较明显的一点就是你用request的话,你需要自己写个列表存放url,存进去再一个一个拿出来。再scrapy中,你只需要把url生成,然后yield request就行了,非常之方便。
做一个简单的scrapy爬虫的更多相关文章
- 用Nodejs做一个简单的小爬虫
Nodejs将JavaScript语言带到了服务器端,作为js主力用户的前端们,因此获得了服务器端的开发能力,但除了用express搭建一个博客外,还有什么好玩的项目可以做呢?不如就做一个网络爬虫吧. ...
- 一个简单的scrapy爬虫抓取豆瓣刘亦菲的图片地址
一.第一步是创建一个scrapy项目 sh-3.2# scrapy startproject liuyifeiImage sh-3.2# chmod -R 777 liuyifeiImage/ 二.分 ...
- 一个简单的python爬虫程序
python|网络爬虫 概述 这是一个简单的python爬虫程序,仅用作技术学习与交流,主要是通过一个简单的实际案例来对网络爬虫有个基础的认识. 什么是网络爬虫 简单的讲,网络爬虫就是模拟人访问web ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
- 【Bugly干货分享】一起用 HTML5 Canvas 做一个简单又骚气的粒子引擎
Bugly 技术干货系列内容主要涉及移动开发方向,是由Bugly邀请腾讯内部各位技术大咖,通过日常工作经验的总结以及感悟撰写而成,内容均属原创,转载请标明出处. 前言 好吧,说是“粒子引擎”还是大言不 ...
- 使用React并做一个简单的to-do-list
1. 前言 说到React,我从一年之前就开始试着了解并且看了相关的入门教程,而且还买过一本<React:引领未来的用户界面开发框架 >拜读.React的轻量组件化的思想及其virtual ...
- 【 D3.js 入门系列 --- 3 】 做一个简单的图表!
前面说了几节,都是对文字进行处理,这一节中将用 D3.js 做一个简单的柱形图. 做柱形图有很多种方法,比如用 HTML 的 div 标签,或用 svg . 推荐用 SVG 来做各种图形.SVG 意为 ...
- 一起用HTML5 canvas做一个简单又骚气的粒子引擎
前言 好吧,说是"粒子引擎"还是大言不惭而标题党了,离真正的粒子引擎还有点远.废话少说,先看demo 本文将教会你做一个简单的canvas粒子制造器(下称引擎). 世界观 这个简单 ...
- 今天来做一个PHP电影小爬虫。
今天来做一个PHP电影小爬虫.我们来利用simple_html_dom的采集数据实例,这是一个PHP的库,上手很容易.simple_html_dom 可以很好的帮助我们利用php解析html文档.通过 ...
随机推荐
- php优化方法
代码优化是开发程序和网站必不可少的一步,代码优化好了,可以大大增加程序的运行效率.使网站或程序加载反应更快.用户体验也就会更好.下面就为大家总结了50条PHP代码优化技巧. 1. 用单引号代替双引号来 ...
- Linux的mysql部署
1. 先输入代码yum install wget -y才可以做后面的 2.下载并安装MySQL官方的 Yum Repository 代码: wget -i -c http://dev.mysql ...
- mysql 主从复制 (2)
今天说一下MySQL的主从复制如何做到! 准备工作: 1.两个虚拟机:我这里用的是CentOS5.5,IP地址分别是192.168.1.101 和192.168.1.105: 101做主服务器,105 ...
- 常见样式问题七、word-break、word-wrap、white-space区别
常见样式问题七.word-break.word-wrap.white-space区别:https://blog.csdn.net/c11073138/article/details/79534394 ...
- BZOJ 3931 (网络流+最短路)
题面 传送门 分析 考虑网络流 注意到数据包走的是最短路,所以我们只需要考虑在最短路上的边 由于最短路可能有多条,我们先跑一遍Dijkstra,然后再\(O(m)\) 遍历每条边(u,v,w) 如果d ...
- L The Digits String(没有写完,有空补)
链接:https://ac.nowcoder.com/acm/contest/338/L来源:牛客网 Consider digits strings with length n, how many d ...
- JVM(8)之 Stop The World
开发十年,就只剩下这套架构体系了! >>> 小伙伴还记得上一篇中我们留下的一个问题吗?什么是停顿类型!经过前几章的学习,我们知道垃圾回收首先是要经过标记的.对象被标记后就会根据不 ...
- 【学习总结】Python-3-字符串运算符与字符串格式化
参考: 本教程的评论区:菜鸟教程-Python3-Python数字 字符串运算符: 实例变量a值为字符串 "Hello",b变量值为 "Python": 字符串 ...
- React入门-JSX和虚拟dom
1.JSX理解 举例: const element = <h1>Hello, world!</h1>; 这被称为 JSX,是一个 JavaScript 的语法扩展.建议在 Re ...
- JS中去除字符串空白符
海纳百川,有容乃大 1.通过原型创建字符串的trim() //去除字符串两边的空白 String.prototype.trim=function(){ return this.replace(/(^\ ...