Neo4j百万级数据导入只需30s
先上图:425万nodes、180万relationships只用了30s 243ms
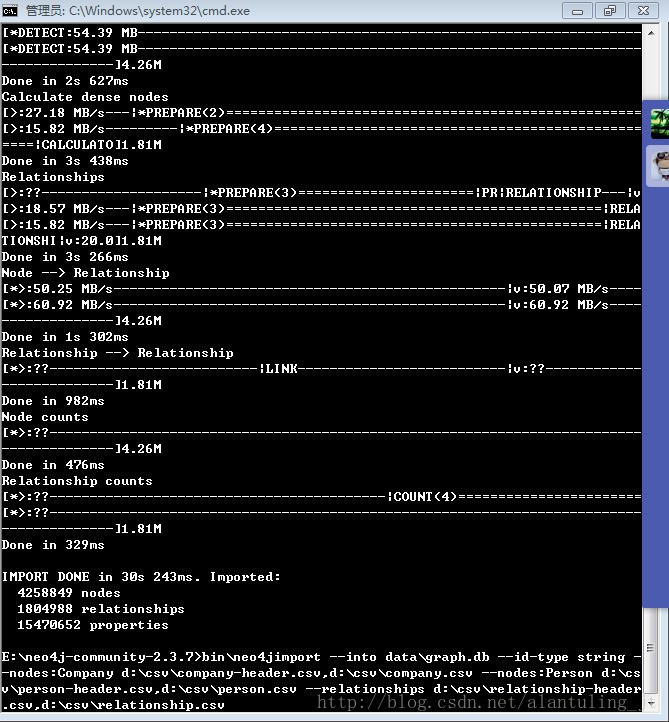
项目需要生成关系图,开始考虑的是用Neo4j官网提供的REST API,从solr中查出2组数据先创建节点再创建关系,过程相当痛苦,速度非常慢,一天都处理不完;
后来改用cypher语句,通过load csv方法,先将数据生成cvs节点文件和关系文件,再通过load csv file create 语法创建,但文件超过30万条时,服务就出错了,遂放弃;
以上2种方法适合小数据量的图库操作,和局部插入更新,不适合大量数据的导入,生成关系图;
后来通过使用官方提供的Neo4jImport 命令行导入数据成功。命令格式在上图中最下面部分有。
首先是要通过查库生成一定格式的csv数据,按node,relationship分别生成,这个可以通过java写代码生成,格式如下:
例子:
节点文件:
文件名:person.csv
文件内容:
id:ID,name,sex,age
p123,jobs,male,28
文件名:company-header.csv
文件内容:
id:ID,entName
文件名:company.csv
文件内容:
c111,Apple
关系文件:
文件名:relationship-header.csv
文件内容:
:START_ID,:END_ID,:TYPE
文件名:relationship.csv
文件内容:
p123,c111,founder
说明:其中一个文件可以分两部分写,一部分写文件头部信息,这些可能需要人为更改,较方便;内容部分一般是代码生成,数据量大,打开修改很费事,一般不动,所以建议分开写,如例子中company-header.csv和company.csv文件就分属于头部文件和内容文件。
:ID表示此列的值作为接连值,并会创建索引,所以如果这列的值有重复,在创建的时候会报错;
:START_ID表示起始节点的ID值;
:END_ID表示结束节点的ID值;
:TYPE表示关系值;
例子中表示的是jobs是Apple公司的创始人;
当然还有其他一些格式,比如:
:LABEL 给列设置标签,可以设置多个标签,用分号分隔;
:IGNORE该列不创建properties
:START_ID(Company)指定该列只能是company中ID的值,前提是company中id:ID(Company)也这样写。
另外,有问题可以留言探讨,我也是刚研究了一周。
原文地址:https://www.jianshu.com/p/0aff60f766f3
Neo4j百万级数据导入只需30s的更多相关文章
- 详解如何挑战4秒内百万级数据导入SQL Server(转)
对于大数据量的导入,是DBA们经常会碰到的问题,在这里我们讨论的是SQL Server环境下百万级数据量的导入,希望对大家有所帮助.51CTO编辑向您推荐<SQL Server入门到精通&g ...
- NEO4J亿级数据导入导出以及数据更新
1.添加配置 apoc.export.file.enabled=true apoc.import.file.enabled=true dbms.directories.import=import db ...
- 实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- 【转 】实战手记:让百万级数据瞬间导入SQL Server
想必每个DBA都喜欢挑战数据导入时间,用时越短工作效率越高,也充分的能够证明自己的实力.实际工作中有时候需要把大量数据导入数据库,然后用于各种程序计算,本文将向大家推荐一个挑战4秒极限让百万级数据瞬间 ...
- Excel导入数据库百万级数据瞬间插入
Excel导入数据库百万级数据瞬间插入 百万级别,瞬间,有点吊哇
- Sql Server中百万级数据的查询优化
原文:Sql Server中百万级数据的查询优化 万级别的数据真的算不上什么大数据,但是这个档的数据确实考核了普通的查询语句的性能,不同的书写方法有着千差万别的性能,都在这个级别中显现出来了,它不仅考 ...
- EF查询百万级数据的性能测试--多表连接复杂查询
相关文章:EF查询百万级数据的性能测试--单表查询 一.起因 上次做的是EF百万级数据的单表查询,总结了一下,在200w以下的数据量的情况(Sql Server 2012),EF是可以使用,但是由于 ...
- 【eclipse jar包】在编写java代码时,为方便编程,常常会引用别人已经实现的方法,通常会封装成jar包,我们在编写时,只需引入到Eclipse中即可。
Eclipse中导入外部jar包 在编写java代码时,为方便编程,常常会引用别人已经实现的方法,通常会封装成jar包,我们在编写时,只需引入到Eclipse中即可. 工具/原料 Eclipse 需要 ...
- MSSQL、MySQL 数据库删除大批量千万级百万级数据的优化
原文:https://blog.csdn.net/songyanjun2011/article/details/7308414 SQL Server上面删除1.6亿条记录,不能用Truncate(因为 ...
随机推荐
- vue.js(8)--v-for的使用
v-for遍历数组.对象数组.对象.迭代次数 <!DOCTYPE html> <html lang="en"> <head> <meta ...
- OS库的使用
Python中有关OS库的使用 路径操作 os.path.abspath(path) 返回path在当前系统中的绝对路径 os.path.normpath(path) 归一化path的表示形式,统一用 ...
- 抽象类(abstract)与接口(interface)的区别
如果一个类中包含抽象方法,那么这个类就是抽象类.abstract只能用来修饰类或者方法,不能用来修饰属性. 接口是指一个方法的集合,接口中的所有方法都没有方法体.接口通过关键字interface实现. ...
- 公私钥,数字证书,https
1.密钥对,在非对称加密技术中,有两种密钥,分为私钥和公钥,私钥是密钥对所有者持有,不可公布,公钥是密钥对持有者公布给他人的. 2.公钥,公钥用来给数据加密,用公钥加密的数据只能使用私钥解密. 3.私 ...
- java ajax返回 Json 的 几种方式
原文:https://blog.csdn.net/qq_26289533/article/details/78749057 方式 1. : 自写代码转 Json 需要 HttpHttpServlet ...
- pandas模块之读取文件
首先我们来看一个文件 1 男 北京 刘一 我笑 #跳过此行,序号1 2 女 上海 刘珊 你笑 3 男 杭州 刘五 他笑 #跳过此行,序号四 4 女 重庆 刘六 不笑了 下面来分析内容,并使用参数 1 ...
- JAVA学习笔记--方法中的参数调用是引用调用or值调用
文献来源:<JAVA核心技术卷Ⅰ>,第4章第5节 (没有相关书籍的可看传送门) ps:测试demo因为偷懒,用的是String对象 结论:Java使用的是对象的值引用.即将任何对象所在内存 ...
- Struts和Hibernate的jar包
这几天做了一个javaee关于struts框架和Hibernate框架的实践,实践内容倒是没什么,关键是找框架的配置花了许多时间 于是在这里把这两个框架的有关jar上传分享一下 链接: https:/ ...
- springboot 加载jsp 刷新jsp ,刷新Controller (亲自尝试)
解决jsp加载成功.<dependency> <groupId>org.apache.tomcat.embed</groupId> <artifactId&g ...
- 【优化】MySQL千万级大表优化解决方案
问题概述 使用阿里云rds for MySQL数据库(就是MySQL5.6版本),有个用户上网记录表6个月的数据量近2000万,保留最近一年的数据量达到4000万,查询速度极慢,日常卡死.严重影响业务 ...