MySQL数据库3分组与单表、多表查询
浮华褪尽,人比烟花寂寞…… ——张爱玲
一、表操作的补充
select * from 表名 where 列名 in (值1,值2,。。。);
查出对应值的数据。
1.1null 和 not null
使用null的时候:
当创建的表中有null时我们如果需要查询出来null所对应的信息,需要用select * from 表名 where 字段名 is null;
mysql> create table v1(id int auto_increment primary key,
-> name varchar(32),email varchar(32))charset=utf8;
Query OK, 0 rows affected (0.70 sec)
mysql> insert into v1(email) values('xxx');
Query OK, 1 row affected (0.07 sec)
mysql> select * from v1;
+----+------+-------+
| id | name | email |
+----+------+-------+
| 1 | NULL | xxx |
+----+------+-------+
1 row in set (0.00 sec)
mysql> select * from v1 where name is null;
+----+------+-------+
| id | name | email |
+----+------+-------+
| 1 | NULL | xxx |
+----+------+-------+
1 row in set (0.01 sec)
mysql> select *from v1 where name='';
Empty set (0.00 sec)
使用null会降低数据的查询效率,不推荐使用,在创建表的时候建议把值默认为空。
1.2使用not null的时候
mysql> create table v2(id int auto_increment primary key,
-> name varchar(32) not null default '',email varchar(32)not null default '')charset=utf8;
Query OK, 0 rows affected (0.44 sec)
mysql> insert into v2(email) values('xxx');
Query OK, 1 row affected (0.06 sec)
mysql> select *from v2 where name='';
+----+------+-------+
| id | name | email |
+----+------+-------+
| 1 | | xxx |
+----+------+-------+
1 row in set (0.00 sec)
二、单表的操作(import)
2.1分组
分组:将所标记的某个相同字段进行归类,比如员工信息表的职位分组,或者按照性别进行分组等。
2.1.1聚合函数
max(列)求出列中的最大值
min(列)求出列中的最小值
sum(列)对列中的数据求和
count(列)对列中的数据计数
avg(列)对列中的数据计算平均数
例子见group by
2.1.2group by
用法:
select 聚合函数, 选取的字段 from employee group by 分组的字段;
group by 是分组的关键词,group by 必须和聚合函数(count)一块出现。count(字段名),按照条件对字段中的数据进行计数。
例子:
1.以性别为例, 进行分组, 统计一下男生和女生的人数是多少个。
mysql> create table employee(
-> id int not null unique auto_increment primary key,
-> name varchar(20) not null,
-> gender enum('male','female') not null default 'male',
-> age int(3) unsigned not null default 28,
-> hire_date date not null,
-> post varchar(50),
-> post_comment varchar(100),
-> salary double(15,2),
-> office int,
-> depart_id int
-> )charset=utf8;
Query OK, 0 rows affected (0.61 sec)
mysql> insert into employee(name,gender,age,hire_date,post,salary,office,depart_id) values
-> ('小张','male',73,'20140701','研发部',3500,401,1),
-> ('小李','male',28,'20121101','研发部',2100,401,1),
-> ('小赵','female',18,'20150411','研发部',18000,403,3),
-> ('歪歪','female',48,'20150311','销售部',3000.13,402,2),
-> ('丫丫','female',38,'20101101','销售部',2000.35,402,2),
-> ('丁丁','female',18,'20110312','销售部',1000.37,402,2),
-> ('小明','male',28,'20160311','运营部',10000.13,403,3),
-> ('小华','male',18,'19970312','运营部',20000,403,3),
-> ('小王','female',18,'20130311','运营部',19000,403,3);
Query OK, 9 rows affected (0.09 sec)
Records: 9 Duplicates: 0 Warnings: 0
mysql> select count(id),gender from employee group by gender;
+-----------+--------+
| count(id) | gender |
+-----------+--------+
| 4 | male |
| 5 | female |
+-----------+--------+
2 rows in set (0.10 sec)
mysql> select gender,count(id) as total from employee group by gender;
#这里可以用as重命名显示的列名
+--------+-------+
| gender | total |
+--------+-------+
| male | 4 |
| female | 5 |
+--------+-------+
2 rows in set (0.00 sec)
2.对部门进行分组, 求出每个部门年龄最大的那个人。
mysql> select depart_id , max(age) from employee group by depart_id;
+-----------+----------+
| depart_id | max(age) |
+-----------+----------+
| 1 | 73 |
| 2 | 48 |
| 3 | 28 |
+-----------+----------+
3 rows in set (0.04 sec)
3.对部门进行分组, 求出每个部门年龄求和。
mysql> select depart_id,sum(age) from employee group by depart_id;
+-----------+----------+
| depart_id | sum(age) |
+-----------+----------+
| 1 | 101 |
| 2 | 104 |
| 3 | 82 |
+-----------+----------+
3 rows in set (0.00 sec)
4.对部门进行分组, 求出每个部门年龄求平均数。
mysql> select depart_id,avg(age) from employee group by depart_id;
+-----------+----------+
| depart_id | avg(age) |
+-----------+----------+
| 1 | 50.5000 |
| 2 | 34.6667 |
| 3 | 20.5000 |
+-----------+----------+
3 rows in set (0.02 sec)
2.1.3having
对group by 之后的数据进行二次筛选
例子
5.对部门进行分组, 求出每个部门年龄求平均数,选出平均数最大的部门。
mysql> select depart_id,avg(age) from employee group by depart_id having avg(age)>35;
+-----------+----------+
| depart_id | avg(age) |
+-----------+----------+
| 1 | 50.5000 |
+-----------+----------+
1 row in set (0.00 sec)
mysql> select depart_id,avg(age)as pj from employee group by depart_id having pj>35;
+-----------+---------+
| depart_id | pj |
+-----------+---------+
| 1 | 50.5000 |
+-----------+---------+
1 row in set (0.00 sec)
2.1.4升序和降序
order by 字段名 asc(升序)desc(降序)
升序和降序可以同时使用如age desc, id asc;
表示: 先对age进行降序, 如果age有相同的行, 则对id进行升序。
例子
mysql> select * from employee order by age desc,id desc;
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | name | gender | age | hire_date | post | post_comment | salary | office | depart_id |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 1 | 小张 | male | 73 | 2014-07-01 | 研发部 | NULL | 3500.00 | 401 | 1 |
| 4 | 歪歪 | female | 48 | 2015-03-11 | 销售部 | NULL | 3000.13 | 402 | 2 |
| 5 | 丫丫 | female | 38 | 2010-11-01 | 销售部 | NULL | 2000.35 | 402 | 2 |
| 7 | 小明 | male | 28 | 2016-03-11 | 运营部 | NULL | 10000.13 | 403 | 3 |
| 2 | 小李 | male | 28 | 2012-11-01 | 研发部 | NULL | 2100.00 | 401 | 1 |
| 9 | 小王 | female | 18 | 2013-03-11 | 运营部 | NULL | 19000.00 | 403 | 3 |
| 8 | 小华 | male | 18 | 1997-03-12 | 运营部 | NULL | 20000.00 | 403 | 3 |
| 6 | 丁丁 | female | 18 | 2011-03-12 | 销售部 | NULL | 1000.37 | 402 | 2 |
| 3 | 小赵 | female | 18 | 2015-04-11 | 研发部 | NULL | 18000.00 | 403 | 3 |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
9 rows in set (0.00 sec)
2.1.5limit限制输出
limit offset ,size
limit 起始行索引,向下查询的长度(索引为0代表第一行)
例子
mysql> select * from employee limit 0,3;
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| id | name | gender | age | hire_date | post | post_comment | salary | office | depart_id |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
| 1 | 小张 | male | 73 | 2014-07-01 | 研发部 | NULL | 3500.00 | 401 | 1 |
| 2 | 小李 | male | 28 | 2012-11-01 | 研发部 | NULL | 2100.00 | 401 | 1 |
| 3 | 小赵 | female | 18 | 2015-04-11 | 研发部 | NULL | 18000.00 | 403 | 3 |
+----+--------+--------+-----+------------+-----------+--------------+----------+--------+-----------+
3 rows in set (0.00 sec)
2.1.6查询表示需要遵循的顺序(important)
select * from 表名 where 条件 group by 条件 having 条件 order by 条件 limit 条件;
where > group by > having > order by > limit
三、多表操作
外键
主关键字(primary key)是表中的一个或多个字段,它的值用于唯一地标识表中的某一条记录。
公共关键字(Common Key)在关系数据库中,关系之间的联系是通过相容或相同的属性或属性组来表示的。如果两个关系中具有相容或相同的属性或属性组,那么这个属性或属性组被称为这两个关系的公共关键字。
如果公共关键字在一个关系中是主关键字,那么这个公共关键字被称为另一个关系的外键。由此可见,外键表示了两个关系之间的相关联系。以另一个关系的外键作主关键字的表被称为主表,具有此外键的表被称为主表的从表。外键又称作外关键字。
使用外键的原因:
1.减少占用的内存空间
2.只需要修改主表的数据,从表的数据也会相应的跟着修改
3.1一对多
一对多指一个主表中的数据和从表中的数据是一对多的关系,如下例,一个部门可以有多个员工。
使用方法:
constraint 外键名 foreign key (被约束的字段) references 约束的表(约束的字段)
mysql> create table department(
-> id int auto_increment primary key,
-> name varchar(32) not null default '')
-> charset utf8;
Query OK, 0 rows affected (0.42 sec)
mysql> insert into department(name) values('研发部'),('运维部'),('前台部'),('小卖部');
Query OK, 4 rows affected (0.06 sec)
Records: 4 Duplicates: 0 Warnings: 0
mysql> create table userinfo(id int auto_increment primary key,
-> name varchar(32) not null default '',
-> depart_id int not null default 1,
-> constraint fk_user_depart foreign key (depart_id) references department(id))
-> charset utf8;
Query OK, 0 rows affected (0.39 sec)
mysql> insert into userinfo (name,depart_id) values('xiaozhu',1),('xiaoyu',1),
-> ('laohe',2),('longge',2),('ludi',3),('xiaoguo',4);
Query OK, 6 rows affected (0.21 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from userinfo;
+----+---------+-----------+
| id | name | depart_id |
+----+---------+-----------+
| 1 | xiaozhu | 1 |
| 2 | xiaoyu | 1 |
| 3 | laohe | 2 |
| 4 | longge | 2 |
| 5 | ludi | 3 |
| 6 | xiaoguo | 4 |
+----+---------+-----------+
6 rows in set (0.00 sec)
mysql> select * from department;
+----+-----------+
| id | name |
+----+-----------+
| 1 | 研发部 |
| 2 | 运维部 |
| 3 | 前台部 |
| 4 | 小卖部 |
+----+-----------+
4 rows in set (0.00 sec)
mysql> insert into userinfo(name,depart_id) values('xiaozhang',5);#depart_id受department.id的约束
ERROR 1452 (23000): Cannot add or update a child row: a foreign key constraint fails (`test2`.`userinfo`, CONSTRAINT `fk_user_depart` FOREIGN KEY (`depart_id`) REFERENCES `department` (`id`))
#联表查询
mysql> select userinfo.name as uname,department.name as dname from userinfo left
-> join department on depart_id = department.id;
+---------+-----------+
| uname | dname |
+---------+-----------+
| xiaozhu | 研发部 |
| xiaoyu | 研发部 |
| laohe | 运维部 |
| longge | 运维部 |
| ludi | 前台部 |
| xiaoguo | 小卖部 |
+---------+-----------+
6 rows in set (0.00 sec)
3.2多对多
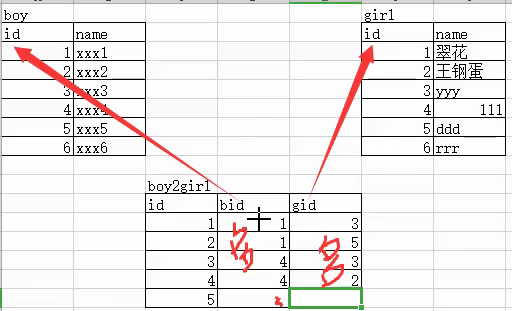
多对多指当一个主表有多个从表时,从表之间的每个数据之间的关系就是多对多,如下图,一个boy可以和多个girl约会,一个girl也可以和多个boy约会。
mysql> create table boy(id int auto_increment primary key,
-> bname varchar(32) not null default'')charset utf8;
Query OK, 0 rows affected (0.36 sec)
mysql> insert into boy(bname) values('zhangsan'),('lisi'),('wangwu');
Query OK, 3 rows affected (0.09 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table girl(id int auto_increment primary key,
-> gname varchar(32) not null default'')charset utf8;
Query OK, 0 rows affected (0.33 sec)
mysql> insert into girl(gname) values('xiaoli'),('xiaohua'),('xiaomei');
Query OK, 3 rows affected (0.06 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> create table boy_girl(id int auto_increment primary key,
-> bid int not null default 1,
-> gid int not null default 1,
-> constraint fk_boy_girl_boy foreign key(bid) references boy(id),
-> constraint fk_boy_girl_girl foreign key(gid) references girl(id)
-> )charset utf8;
Query OK, 0 rows affected (0.42 sec)
mysql> insert into boy_girl(bid,gid) values(1,1),(2,2),(3,3),(3,1),(2,1),(1,2);
Query OK, 6 rows affected (0.04 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from boy left join boy_girl on boy.id = boy_girl.bid left join girl
-> on girl.id = boy_girl.gid;
+----+----------+------+------+------+------+---------+
| id | bname | id | bid | gid | id | gname |
+----+----------+------+------+------+------+---------+
| 1 | zhangsan | 1 | 1 | 1 | 1 | xiaoli |
| 2 | lisi | 5 | 2 | 1 | 1 | xiaoli |
| 3 | wangwu | 4 | 3 | 1 | 1 | xiaoli |
| 1 | zhangsan | 6 | 1 | 2 | 2 | xiaohua |
| 2 | lisi | 2 | 2 | 2 | 2 | xiaohua |
| 3 | wangwu | 3 | 3 | 3 | 3 | xiaomei |
+----+----------+------+------+------+------+---------+
6 rows in set (0.03 sec)
mysql> select bname,gname from boy left join boy_girl on boy.id = boy_girl.bid
-> left join girl on girl.id = boy_girl.gid;
+----------+---------+
| bname | gname |
+----------+---------+
| zhangsan | xiaoli |
| lisi | xiaoli |
| wangwu | xiaoli |
| zhangsan | xiaohua |
| lisi | xiaohua |
| wangwu | xiaomei |
+----------+---------+
6 rows in set (0.00 sec)
3.3一对一
一对一指的是两个表中的数据是一对一的关系,使用unique(字段名)来约束这种关系。如下例,由于工资属于员工的敏感信息,用单独的表去存储,这时工资和员工信息就是一对一的关系。
mysql> create table priv(
-> id int auto_increment primary key,
-> salary int not null default 0,
-> uid int not null default 1,
-> constraint fk_priv_user foreign key (uid) references userinfo(id),
-> unique(uid)) charset=utf8;
Query OK, 0 rows affected (0.52 sec)
mysql> insert into priv(salary,uid) values (10000,1),(12000,2),(15000,3),(8000,4),(9000,5),(9900,6);
Query OK, 6 rows affected (0.16 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select name,salary from userinfo left join priv on priv.uid = userinfo.id;
+---------+--------+
| name | salary |
+---------+--------+
| xiaozhu | 10000 |
| xiaoyu | 12000 |
| laohe | 15000 |
| longge | 8000 |
| ludi | 9000 |
| xiaoguo | 9900 |
+---------+--------+
6 rows in set (0.00 sec)
3.4多表联查
多表联查就是将多个有关系的表放在一起查,使用的语句有:
left join……on查询时以左边的数据为主
right join ……on查询时以右边的数据为主
mysql> insert into department(name) values('业务部');
Query OK, 1 row affected (0.12 sec)
mysql> select userinfo.name as uname,department.name as dname from userinfo left
-> join department on depart_id = department.id;
+---------+-----------+
| uname | dname |
+---------+-----------+
| xiaozhu | 研发部 |
| xiaoyu | 研发部 |
| laohe | 运维部 |
| longge | 运维部 |
| ludi | 前台部 |
| xiaoguo | 小卖部 |
+---------+-----------+
6 rows in set (0.00 sec)
mysql> select userinfo.name as uname,department.name as dname from userinfo right
-> join department on depart_id = department.id;
+---------+-----------+
| uname | dname |
+---------+-----------+
| xiaozhu | 研发部 |
| xiaoyu | 研发部 |
| laohe | 运维部 |
| longge | 运维部 |
| ludi | 前台部 |
| xiaoguo | 小卖部 |
| NULL | 业务部 |
+---------+-----------+
7 rows in set (0.00 sec)
MySQL数据库3分组与单表、多表查询的更多相关文章
- mysql数据库,当数据类型是float时,查询居然查询不出数据来
mysql数据库,当数据类型是float时,查询居然查询不出数据来,类似如下: 以后mysql数据库不用float类型,而double类型可以查得出来.
- Mysql数据库多对多关系未建新表
原则上,多对多关系是要新建一个关系表的,当遇到没有新建表的情况下如何查询多对多的SQL呢? FIND_IN_SET(str,strlist) 官网:http://dev.mysql.com/doc/r ...
- linux定时查询mysql数据库并把结果保存到新表 然后备份数据库
脚本文件名:myshell内容如下: #!/bin/bash # mysql用户名 username="root" # mysql密码 password="root&qu ...
- MySQL数据库的创建和操作以及多表查询
创建数据库: CREATE DATABASE 数据库名称; 查看所有的数据库: SHOW DATABASES; 操作指定数据库: USE 数据库名称; 查看当前所操作的数据库: SELECT DATA ...
- java操作MySQL数据库(插入、删除、修改、查询、获取所有行数)
插播一段广告哈:我之前共享了两个自己写的小应用,见这篇博客百度地图开发的两个应用源码共享(Android版),没 想到有人找我来做毕设了,年前交付,时间不是很紧,大概了解了下就接下了,主要用到的就是和 ...
- MySQL数据库详解(一)执行SQL查询语句时,其底层到底经历了什么?
一条SQL查询语句是如何执行的? 前言 大家好,我是WZY,今天我们学习下MySQL的基础框架,看一件事千万不要直接陷入细节里,你应该先鸟瞰其全貌,这样能够帮助你从高维度理解问题.同样,对于MyS ...
- MySQL数据库实验二:单表查询
实验二 单表查询 一.实验目的 理解SELECT语句的操作和基本使用方法. 二.实验环境 是MS SQL SERVER 2005的中文客户端. 三.实验示例 1.查询全体学生的姓名.学号.所在系. ...
- MySQL数据库入门(建库和建表)--陈远波
建库.建表 1.建库 (1)SQL语句命令建库: Create database数据库名称 (该方法创建的数据库没有设置编码乱码) 1 2 3 4 5 -- 创建数据库时,设置数据库的编码方式 -- ...
- MySQL数据库基础(三)(操作数据表中的记录)
1.插入记录INSERT 命令:,expr:表达式 注意:如果给主键(自动编号的字段)赋值的话,可以赋值'NULL'或'DEFAULT',主键的值仍会遵守默认的规则:如果省略列名的话,所有的字段必须一 ...
随机推荐
- 阶段2 JavaWeb+黑马旅游网_15-Maven基础_第1节 基本概念_02maven依赖管理的概念
传统的web项目jar放在项目中,占用磁盘空间 maven项目里面只保存jar包的坐标.jar包文件都在仓库中.扎包重用都在jar包仓库中.
- delphi : 窗体的close,free,destroy
一.我用application.create(TForm2,Form2)语句,创建了Form2,可是调用了Form2.close后,重新调用Form2.show. 刚才所创建的Form2仍然存在.问为 ...
- iOS客户端使用教程
使用须知 支持 ios9.0 以上系统,兼容 iphone.ipad.ipod 等设备. 电脑上用 PP 助手安装 Shadowrocket Mac电脑上用PP助手安装Shadowrocket 下 ...
- Go语言入门篇-项目常见用法&语法
一.导入包用法: //_表示仅执行该包下的init函数(不需要整个包导入) import _ "git.xx.xx/baases/identity/cachain/version" ...
- 华南理工大学 “三七互娱杯” C HRY and Abaas
https://ac.nowcoder.com/acm/contest/874/C 题目大意是两人俄罗斯轮盘赌 n个位置 有m个子弹 已知哪些位置上有子弹 子弹打出 游戏结束 求第i次扣动扳机游戏才结 ...
- P1012拼数
这是一道字符串的普及—的题. 输入几组数字,怎样组合起来才可以使最后结果最大.一开始这道题类似于那道删数问题,每次删除递增序列的最后一位,达到最小.而这个题我也是想到了贪心做法,于是想逐位判断,让在前 ...
- Cause: com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Unknown column 'p.knowlege_part_id' in 'field list'
MyBatis中,出现Unknown column的提示是mapper.xml中的数据库字段写错了. 错误示例: XxMapper.xml中 <sql id="KnowlegeSect ...
- centos7 安装redis 出现cc: command not found错误解决
安装过程 1. 下载并解压 cd /root/software wget http://download.redis.io/releases/redis-3.2.4.tar.gz tar -zxvf ...
- PHP 中一个 False 引发的问题,差点让公司损失一百万
PHP 中一个 False 引发的问题,差点让公司损失一百万 一.场景描述 上周我一个在金融公司的同学,他在线上写一个 Bug,差点造成公司损失百万.幸好他及时发现了这个问题并修复了.这是一个由 PH ...
- Springboot+CAS单点登录
一:安装CAS 下载cas:https://github.com/apereo/cas 1.1 将cas并打成war包.放入一个干净的tomcat中,启动tomcat测试: http://localh ...