Linux分页机制
地址长度
在Linux下,unsigned long可以与地址的长度保持一致,即32位系统下unsigned long为32位,而64位系统下为64位长。
虚拟地址的分解
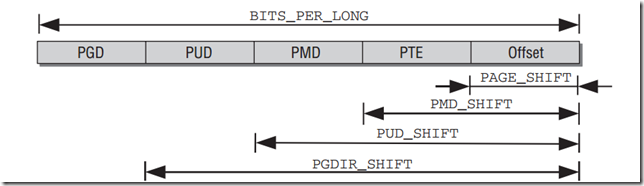
如图所示,通过XXX_SHIFT方式,移位得到范围。
1: /* PAGE_SHIFT determines the page size */
2: #define PAGE_SHIFT 12
3: #define PAGE_SIZE (_AC(1,UL) << PAGE_SHIFT) // 4KB = 4096
4: #define PAGE_MASK (~(PAGE_SIZE-1)) // 0x0FFF
对于没有PMD和PUD的情况,即只有两级页表的情况,在include/asm-generic/pgtable-nopud.h及pgtable_nopmd.h的情况:
1: /*
2: * Having the pmd type consist of a pud gets the size right, and allows
3: * us to conceptually access the pud entry that this pmd is folded into
4: * without casting.
5: */
6: typedef struct { pud_t pud; } pmd_t;
7:
8: #define PMD_SHIFT PUD_SHIFT
9: #define PTRS_PER_PMD 1
10: #define PMD_SIZE (1UL << PMD_SHIFT)
11: #define PMD_MASK (~(PMD_SIZE-1))
1: /*
2: * Having the pud type consist of a pgd gets the size right, and allows
3: * us to conceptually access the pgd entry that this pud is folded into
4: * without casting.
5: */
6: typedef struct { pgd_t pgd; } pud_t;
7:
8: #define PUD_SHIFT PGDIR_SHIFT
9: #define PTRS_PER_PUD 1
10: #define PUD_SIZE (1UL << PUD_SHIFT)
11: #define PUD_MASK (~(PUD_SIZE-1))
1: /*
2: * traditional i386 two-level paging structure:
3: */
4:
5: #define PGDIR_SHIFT 22
6: #define PTRS_PER_PGD 1024
因此,对于x86情况来说,下图更为合适:
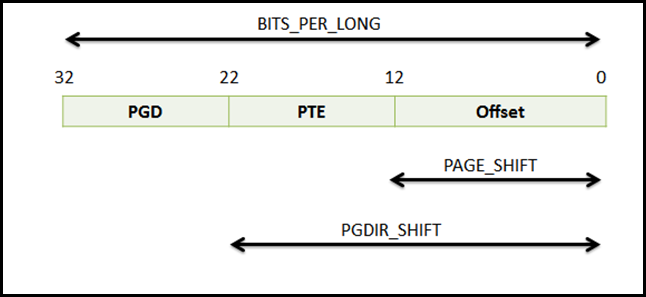
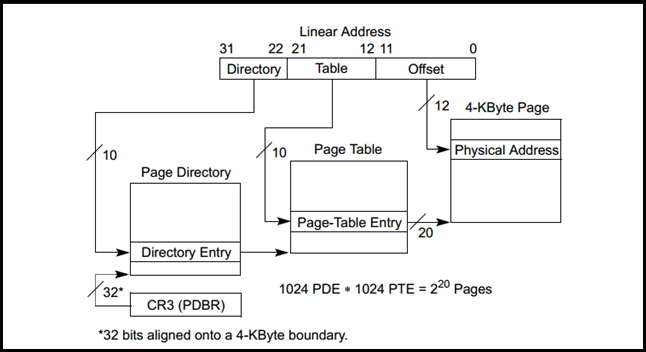
由上图可知,页目录中有1024个PDE(Page Directory Entry),其中每个entry代表着一张页表,对应着4MB的内存区域。而对于Linux来说,内核态总共需要1GB的内存空间,因此需要256个PDE来保存其对应的页表索引。
对于不同的进程来说,虽然768个PDE(3GB内存)是与该进程相关的,即对于不同的进程是不一样的,但是内核空间是各个进程都共享的,所以可以预见,每个进程的Page Directory中后256项都是相同的。
这样通过两层的页表,每个进程最多需要768个Page Table就足够了,从而节省了很多空间。
在PDE和PTE中,除了保存相应下一级内存页的高20位地址外,还有一些重要的属性位,比如P(Present),代表该页是否存在于物理内存中。
物理内存的管理
内核先要管理物理内存,因为物理内存在范围上地位(或重要性)是不平等的,位于DMA区域的物理内存更加珍贵些,因为DMA操作只能利用这部分的物理内存,如果被应用程序轻易地就给分配掉了,那么很可能导致DMA失败。
另外还要考虑NUMA的复杂情况,所以内核需要对物理内存的分配进行管理。
即引导CPU优先分配那些相对廉价的物理内存区域(HighMem),而且对于相对昂贵并且经常需要使用的内存区域(Normal Zone)使用简单而直接的线性映射页表项,
1: (Linear Address = Physical Address + Constant)
从而使对该区域的访问更加方便。
在每个结点的每个区域上,都有对应的空闲的页表,以Buddy System进行管理,内核需要分配物理内存的时候,就要向Buddy System进行申请。
但是不管哪个区域(Zone)物理内存,都需要通过页表项的方式,提供给内核或者应用程序使用。虽然分页机制是可以进行开关的,但是在Linux操作系统工作的情景下,分页机制是打开的。
也就是说,内核或者应用程序中对内存地址的操作,都是要经过CPU的MMU单元进行页表项的转换,从线性地址转换到物理地址的。
如果使用的内存地址所在的内存页表项中的P(Present)标志为0的话,代表内存页不在物理内存中,会由CPU引发缺页异常,再由异常处理程序负责从页交换文件中调到相应的页,重新加载到物理内存中,然后再尝试重新执行引起缺页异常的那条指令。
而所有的这一切,对于访问内存的内核或者应用程序来说,都是透明的。
什么是TLB
物理内存就是我们机器里的内存条,所有的数据都要加载到物理内存中运行,但是程序员不知道客户机器中的物理内存大小,因为无法为程序分配物理内存;虚拟内存的出现则让程序员无需考虑客户机器物理内存的大小,可以随意的给程序分配内存地址,只要遵循硬件厂商和操作系统厂商的开发手册即可;而虚拟内存数据和物理内存之间要形成映射,到底每一段虚拟内存数据被放到哪个物理内存中,则需要存储管理来实现。
而虚拟内存和物理内存间的映射关系被以页表的形式存储,而TLB就是一个高速页表缓存器,专门存储这些映射关系,由于这些映射关系较多,所以TLB也是分级管理,Nahalem就是三级TLB。当CPU执行数据访问时候,必须访问TLB从而获取
映射关系,从而知道虚拟内存数据到底放在物理内存的什么位置,然后精确的处理数据。
刷新TLB的方法
因为TLB是保存着线性地址到物理地址的映射关系,它实际上是物理内存中页表部分的一个View,因此如果页表中的某一项发生了变化,而TLB没有跟着相应的变化的话,就会出现不一致(Inconsistent)的问题。
为了解决这个问题,可以通过刷新TLB(flush TLB)的方法来重置,方法如下:
1: mov eax, cr3;
2: move cr3, eax;
因此,我们在Linux内核源码中看到下面的代码:
1: static inline void __native_flush_tlb(void)
2: {
3: native_write_cr3(native_read_cr3());
4: }
Buddy System
Buddy System提供以下的API,以供内核分配物理内存:
1: // 以下函数返回一个struct page的实例
2:
3: alloc_pages(mask, order); //返回一个struct page实例, 代表起始页
4:
5: alloc_page(mask); //返回一个struct page实例, 只分配一页
6:
7: get_zeroed_page(mask); //返回一个置0的内存页
8:
9:
以及
1: // 以下函数返回内存块的虚拟地址
2:
3: __get_free_pages(mask, order);
4: __get_free_page(mask);
和
1: get_dma_pages(gfp_mask, order);//返回适用于DMA的页
以下是释放页的函数
1: free_page(struct page*);
2: free_pages(struct page*, order);
3:
4: __free_page(addr);
5: __free_pages(addr, order);
启动过程的对分页的支持
1: setup_arch() -> paging_init()
BootMem
在操作系统启动过程中时,也需要使用物理内存,但是这时Buddy System还没有Ready,所以Linux提供了一种简单的物理内存管理方案。
通过比特位的位图来管理物理内存的使用情况,采用First-Best策略来搜索合适的物理内存块。
保证最快找到可以大小的连续物理内存,又不会覆盖掉正在使用的物理内存。
Slab分配器
用户态的程序可以使用C标准库中提供的malloc接口分配小块的内存,但是内核也需要分配小块的内存,却无法使用标准库提供的服务。所以内核提供了slab分配器来分配小块的内存。
slab分配器的好处:
- 1. 由于内核趋向于有规律地分配并释放相同大小的内存块,比如sizeof(fs_struct)大小。所以slab分配器提供了缓存的功效,即对刚刚释放的小块内存,并不立即交给Buddy System回收,而是先保留下来,当内核马上又分配相同大小的内存块时,就可以很快地重用这块内存。
- 2. 如果直接调用Buddy System进行小块内存的分配,就会增加内存调度的块大小,加快高速缓存行的刷新,从而导致不重要的数据驻留在高速缓存行中,重要的数据却被切换到内存中。
- 3. 直接调用Buddy System进行小块内存的分配,会使数据总是出现在2的整数幂次附件,从而使对应的高速缓存行,不停地被刷新,导致该高速缓存行被过度使用。
Linux分页机制的更多相关文章
- Linux分页机制之概述--Linux内存管理(六)
1 分页机制 在虚拟内存中,页表是个映射表的概念, 即从进程能理解的线性地址(linear address)映射到存储器上的物理地址(phisical address). 很显然,这个页表是需要常驻内 ...
- [转帖]Linux分页机制之分页机制的演变--Linux内存管理(七)
Linux分页机制之分页机制的演变--Linux内存管理(七) 2016年09月01日 20:01:31 JeanCheng 阅读数:4543 https://blog.csdn.net/gatiem ...
- [转帖]Linux分页机制之概述--Linux内存管理(六)
Linux分页机制之概述--Linux内存管理(六) 2016年09月01日 19:46:08 JeanCheng 阅读数:5491 标签: linuxkernel内存管理分页架构更多 个人分类: ┈ ...
- Linux分页机制之分页机制的实现详解--Linux内存管理(八)
1 linux的分页机制 1.1 四级分页机制 前面我们提到Linux内核仅使用了较少的分段机制,但是却对分页机制的依赖性很强,其使用一种适合32位和64位结构的通用分页模型,该模型使用四级分页机制, ...
- Linux分页机制之分页机制的演变--Linux内存管理(七)
1 页式管理 1.1 分段机制存在的问题 分段,是指将程序所需要的内存空间大小的虚拟空间,通过映射机制映射到某个物理地址空间(映射的操作由硬件完成).分段映射机制解决了之前操作系统存在的两个问题: 地 ...
- Linux的分段和分页机制
1.分段机制 80386的两种工作模式 80386的工作模式包括实地址模式和虚地址模式(保护模式).Linux主要工作在保护模式下. 分段机制 在保护模式下,80386虚地址空间可达16K个段,每 ...
- Linux内存寻址之分页机制
在上一篇文章Linux内存寻址之分段机制中,我们了解逻辑地址通过分段机制转换为线性地址的过程.下面,我们就来看看更加重要和复杂的分页机制. 分页机制在段机制之后进行,以完成线性—物理地址的转换过程.段 ...
- linux x86内核中的分页机制
Linux采用了通用的四级分页机制,所谓通用就是指Linux使用这种分页机制管理所有架构的分页模型,即便某些架构并不支持四级分页.对于常见的x86架构,如果系统是32位,二级分页模型就可满足系统需求: ...
- Linux内存寻址之分段机制及分页机制【转】
前言 本文涉及的硬件平台是X86,如果是其他平台的话,如ARM,是会使用到MMU,但是没有使用到分段机制: 最近在学习Linux内核,读到<深入理解Linux内核>的内存寻址一章.原本以为 ...
随机推荐
- Vue实现无痕刷新
一.什么是无痕刷新 在不刷新浏览器的情况下,实现页面的刷新. 传统的刷新页面方式 window.location.reload()原生 js 提供的方法 this.$router.go(0)vue 路 ...
- SpringBoot扫描不到类,注入失败A component required a bean of type 'XXService' that could...
SpringBoot项目的Bean装配默认规则是根据Application类所在的包位置从上往下扫描! “Application类”是指SpringBoot项目入口类.这个类的位置很关键: 如果App ...
- FrameWork内核解析之布局加载与资源系统(三)
阿里P7Android高级架构进阶视频免费学习请点击:https://space.bilibili.com/474380680本篇文章将继续从以下两个内容来介绍布局加载与资源系统: [ LayoutM ...
- el-form-item内容过多,及弹窗框宽度属性show-overflow-tooltip设置
内容过多: :show-overflow-tooltip=true 宽度属性设置: .el-tooltip__popper{ max-width:30% }
- Spring学习笔记(9)——注入参数
集合类型属性 1.Set类型 private Set<String> sets=new HashSet<String>(); //我们需要给它添加set方法 public Se ...
- 前后台 工作切换---------------Linux 任务管理器(一)
继续下一章... 发现了一个好东东.就是前后台的切换.例如我们现在要vim一个文件.然后又要查找一些命令的时候,以前不知道,都是退出后,查完了,在vim进入.现在我们可以将该vim拿到后台,然后查完了 ...
- vue在element-ui的dialog弹出框中加入百度地图
参考:https://blog.csdn.net/u012724595/article/details/82703579 <!-- gps弹窗 --> <el-dialog v-di ...
- 【Luogu】【关卡2-6】贪心(2017年10月)
任务说明:贪心就是只考虑眼前的利益.对于我们人生来说太贪是不好的,不过oi中,有时是对的. P1090 合并果子 有N堆果子,只能两两合并,每合并一次消耗的体力是两堆果子的权重和,问最小消耗多少体力. ...
- koa2 使用 async 、await、promise解决异步的问题
koa代码编写上避免了多层的嵌套异步函数调用 async await来解决异步 - async await 需要依赖于promise 三主角: __函数前面 async, 内部才能await,要想aw ...
- Python爬虫总结——常见的报错、问题及解决方案
在爬虫开发时,我们时常会遇到各种BUG各种问题,下面是我初步汇总的一些报错和解决方案. 在以后的学习中,如果遇到其他问题,我也会在这里进行更新. 各位如有什么补充,欢迎评论区留言~~~ 问题: IP被 ...