Decision Tree Algorithm
Decision Tree算法的思路是,将原始问题不断递归地细分为子问题,直到子问题直接可获得答案为止。在模型训练的过程中,根据训练集去做树的生长(Grow the tree),生长所有可能的Branches,最终达到叶子节点(leaf nodes)。在预测过程中,则遍历树枝,去寻找和预测目标最相近的叶子。
构建决策树模型:
而在构建过程中的主要问题是,选择数据集的哪个feature来做分割。这里用到了Greedy Search。形象地说,每走一步,都选择当前情况下最好的路径,而不管下一步如何或几步之后如何。那么,定义什么是“最好”,有三个标准:ID3,C4.5和Gini index。
ID3:计算信息增益(Information Gain),即分割前后熵值的差,差值越大,则我们在分割过程中,获得的信息量就越大:
Entropy of the target datase:
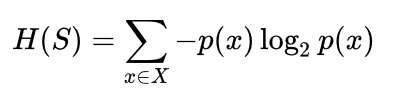
Information Gain by a split:

C4.5:和ID3相似,但采取的是信息增益率(Information Gain Ratio),避免了通过将数据集分割为无限多个从而获得最大信息增益的极限情况:
切割信息量(feature_A将集合S分割为若干个sj):
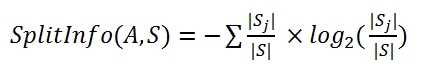
信息增益率=信息增益/切割信息量
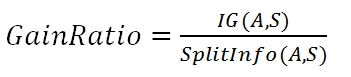
在ID3和C4.5算法中,构建树时需要选择Information Gain或Gain Ratio最大的feature.
CART:与前面两种算法不同,CART计算的是Gini系数。Gini如果为0,说明集合纯净,Gini大则说明集合离散度高。所以我们选择,使Gini系数最小的feature来生成枝叶。同时,在算法比较中,Gini算法没有logrithm的存在,计算速度会更快:
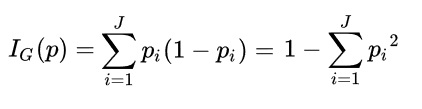
选择ID3, C4.5和CART中的一个标准来递归的生成树,即可完成建模。
利用决策树做预测:
在预测时,根据target example的feature取值,在现有决策树的枝叶路径中搜寻最匹配的路径。如果存在相同的路径,perfect!直接找出输出值。如果不存在,卡在了某个分叉路口,那么就对该分岔路口下的所有节点进行投票,来取得最大可能性的输出值。
问题思考:
如果我的Training Set足够大,同时其多样性也足够,那么在训练过程中生成的决策树就会枝叶茂盛、十分复杂。同时带来的问题就是,过于细枝末节的决策树,会完美拟合训练集,但对于测试集的预测会大打折扣。这是典型的Overfitting,这时就要对决策树进行修剪,具体原理请见下篇博文。
Decision Tree Algorithm的更多相关文章
- 机器学习技法:09 Decision Tree
Roadmap Decision Tree Hypothesis Decision Tree Algorithm Decision Tree Heuristics in C&RT Decisi ...
- 机器学习技法笔记:09 Decision Tree
Roadmap Decision Tree Hypothesis Decision Tree Algorithm Decision Tree Heuristics in C&RT Decisi ...
- Decision Tree
Decision Tree builds classification or regression models in the form of a tree structure. It break d ...
- Spark MLlib - Decision Tree源码分析
http://spark.apache.org/docs/latest/mllib-decision-tree.html 以决策树作为开始,因为简单,而且也比较容易用到,当前的boosting或ran ...
- Sklearn库例子1:Sklearn库中AdaBoost和Decision Tree运行结果的比较
DisCrete Versus Real AdaBoost 关于Discrete 和Real AdaBoost 可以参考博客:http://www.cnblogs.com/jcchen1987/p/4 ...
- OpenCV码源笔记——Decision Tree决策树
来自OpenCV2.3.1 sample/c/mushroom.cpp 1.首先读入agaricus-lepiota.data的训练样本. 样本中第一项是e或p代表有毒或无毒的标志位:其他是特征,可以 ...
- (转)Decision Tree
Decision Tree:Analysis 大家有没有玩过猜猜看(Twenty Questions)的游戏?我在心里想一件物体,你可以用一些问题来确定我心里想的这个物体:如是不是植物?是否会飞?能游 ...
- CART分类与回归树与GBDT(Gradient Boost Decision Tree)
一.CART分类与回归树 资料转载: http://dataunion.org/5771.html Classification And Regression Tree(CART)是决策 ...
- [ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest)
[ML学习笔记] 决策树与随机森林(Decision Tree&Random Forest) 决策树 决策树算法以树状结构表示数据分类的结果.每个决策点实现一个具有离散输出的测试函数,记为分支 ...
随机推荐
- CSS3制作的垂直口风琴1
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- C#根据出生日期和当前日期计算精确年龄
C#根据出生日期和当前日期计算精确年龄更多 0c#.net基础 public static string GetAge(DateTime dtBirthday, DateTime dtNow){ st ...
- Javascript | DOM\DOM树浅析
DOM Document Object Model(文档对象模型) 定义了表示和修改文档所需的方法. DOM对象即为宿主对象,由浏览器厂商定义,用来操作html和xml功能的一类对象的集合.也有人称D ...
- frontend-dev面试
1.笔试题 vuex 存储的数据为null或者undefined是为啥? 1.伸缩布局 flex规则 2.横向布局的实现方法有多少? 3.说一说 flex:1; 的含义 / 说一说flex:1 1 3 ...
- Python之路-Python中文件和异常
一.文件的操作 open函数 在python中,使用open函数,打开一个已经存在的文件,或者新建一个新文件. 函数语法 open(name[, mode[, buffering[,encoding] ...
- apache重写规则简单理解
1.前提:开启apache重写,并把httpd.conf里的相关的AllowOverride denied改为AllowOverride all 2.重写规则可写在项目根目录的.htaccess文件或 ...
- Zabbix分布式监控系统实践
https://www.zabbix.com/wiki/howto/install/Ubuntu/ubuntuinstall 环境介绍OS: Ubuntu 10.10 Server 64-bitSer ...
- springboot-启动一段时间图片不能上传
问题:[B2B]后台服务.PC服务.APP服务.仓储服务,启动一段时间图片不能上传. 原因:/tmp下以tomcat开头的目录被清理了. 处理方案:1.找到涉及服务器 注:后台服务.PC服务.APP服 ...
- loadrunner 使用
loadrunner给我的感觉很强势吧,第一次接触被安装包吓到了,当时用的是win10安装11版本的,各种安装失败,印象很深刻,那时候全班二三十号人,搞环境搞了两天,后来无奈,重做系统换成win7的了 ...
- Mac新手入门:mac操作技巧
面对全新的mac电脑,你是不是一脸的迷茫,一些原来windows上的基本操作在mac上都不知道从何入手了,下面小编就为大家整理了一些基本的操作.相信一定会方便你的学习和工作的. 如何压缩与解压缩 在M ...