Linux CFS调度器之负荷权重load_weight--Linux进程的管理与调度(二十五)
1. 负荷权重
1.1 负荷权重结构struct load_weight
负荷权重用struct load_weight数据结构来表示, 保存着进程权重值weight。其定义在/include/linux/sched.h, v=4.6, L1195, 如下所示
struct load_weight {
unsigned long weight; /* 存储了权重的信息 */
u32 inv_weight; /* 存储了权重值用于重除的结果 weight * inv_weight = 2^32 */
};
1.2 调度实体的负荷权重load
既然struct load_weight保存着进程的权重信息, 那么作为进程调度的实体, 必须将这个权重值与特定的进程task_struct, 更一般的与通用的调度实体sched_entity相关联
struct sched_entity作为进程调度的实体信息, 其内置了load_weight结构用于保存当前调度实体的权重, 参照http://lxr.free-electrons.com/source/include/linux/sched.h?v=4.6#L1195
struct task_struct
{
/* ...... */
struct sched_entity se;
/* ...... */
}
因此我们就可以通过task_statuct->se.load获取负荷权重的信息, 而set_load_weight负责根据进程类型及其静态优先级计算符合权重.
2 优先级和权重的转换
2.1 优先级->权重转换表
一般这个概念是这样的, 进程每降低一个nice值(优先级提升), 则多获得10%的CPU时间, 没升高一个nice值(优先级降低), 则放弃10%的CPU时间.
为执行该策略, 内核需要将优先级转换为权重值, 并提供了一张优先级->权重转换表sched_prio_to_weight, 内核不仅维护了负荷权重自身, 还保存另外一个数值, 用于负荷重除的结果, 即sched_prio_to_wmult数组, 这两个数组中的数据是一一对应的.
其中相关的数据结构定义在kernel/sched/sched.h?v=4.6, L1132
// http://lxr.free-electrons.com/source/kernel/sched/sched.h?v=4.6#L1132
/*
* To aid in avoiding the subversion of "niceness" due to uneven distribution
* of tasks with abnormal "nice" values across CPUs the contribution that
* each task makes to its run queue's load is weighted according to its
* scheduling class and "nice" value. For SCHED_NORMAL tasks this is just a
* scaled version of the new time slice allocation that they receive on time
* slice expiry etc.
*/
#define WEIGHT_IDLEPRIO 3 /* SCHED_IDLE进程的负荷权重 */
#define WMULT_IDLEPRIO 1431655765 /* SCHED_IDLE进程负荷权重的重除值 */
extern const int sched_prio_to_weight[40];
extern const u32 sched_prio_to_wmult[40];
// http://lxr.free-electrons.com/source/kernel/sched/core.c?v=4.6#L8484
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
/*
* Inverse (2^32/x) values of the sched_prio_to_weight[] array, precalculated.
*
* In cases where the weight does not change often, we can use the
* precalculated inverse to speed up arithmetics by turning divisions
* into multiplications:
*/
const u32 sched_prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
对内核使用的范围[-20, 19]中的每个nice级别, sched_prio_to_weight数组都有一个对应项
nice [-20, 19] -=> 下标 [0, 39]
而由于权重weight 用unsigned long 表示, 因此内核无法直接存储1/weight, 而必须借助于乘法和位移来执行除法的技术. sched_prio_to_wmult数组就存储了这些值, 即sched_prio_to_wmult每个元素的值是2^32/prio_to_weight$每个元素的值.
可以验证
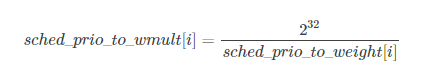
同时我们可以看到其定义了两个宏WEIGHT_IDLEPRIO和WMULT_IDLEPRIO这两个宏对应的就是SCHED_IDLE调度的进程的负荷权重信息, 因为要保证SCHED_IDLE进程的最低优先级和最低的负荷权重. 这点信息我们可以在后面分析set_load_weight函数的时候可以看到
可以验证
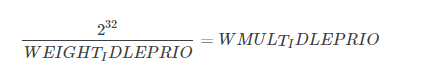
3.2 linux-4.4之前的shced_prio_to_weight和sched_prio_to_wmult
关于优先级->权重转换表sched_prio_to_weight
在linux-4.4之前的内核中, 优先级权重转换表用prio_to_weight表示, 定义在kernel/sched/sched.h, line 1116, 与它一同定义的还有prio_to_wmult, 在kernel/sched/sched.h, line 1139均被定义为static const
但是其实这种能够方式不太符合规范的编码风格, 因此常规来说, 我们的头文件中不应该存储结构的定义, 即为了是程序的模块结构更加清晰, 头文件中尽量只包含宏或者声明, 而将具体的定义, 需要分配存储空间的代码放在源文件中.
否则如果在头文件中定义全局变量,并且将此全局变量赋初值,那么在多个引用此头文件的C文件中同样存在相同变量名的拷贝,关键是此变量被赋了初值,所以编译器就会将此变量放入DATA段,最终在连接阶段,会在DATA段中存在多个相同的变量,它无法将这些变量统一成一个变量,也就是仅为此变量分配一个空间,而不是多份空间,假定这个变量在头文件没有赋初值,编译器就会将之放入BSS段,连接器会对BSS段的多个同名变量仅分配一个存储空间
因此在新的内核中, 内核黑客们将这两个变量存放在了kernel/sched/core.c, 并加上了sched_前缀, 以表明这些变量是在进程调度的过程中使用的, 而在kernel/sched/sched.h, line 1144中则只包含了他们的声明.
下面我们列出优先级权重转换表定义更新后对比项
| 内核版本 | 实现 | 地址 |
|---|---|---|
| <= linux-4.4 | static const int prio_to_weight[40] | kernel/sched/sched.h, line 1116 |
| >=linux-4.5 | const int sched_prio_to_weight[40] | 声明在kernel/sched/sched.h, line 1144, 定义在kernel/sched/core.c |
其定义并没有发生变化, 依然是一个一对一NICE to WEIGHT的转换表
3.3 1.25的乘积因子
各数组之间的乘积因子是1.25. 要知道为何使用该因子, 可考虑下面的例子
两个进程A和B在nice级别0, 即静态优先级120运行, 因此两个进程的CPU份额相同, 都是50%, nice级别为0的进程, 查其权重表可知是1024. 每个进程的份额是1024/(1024+1024)=0.5, 即50%
如果进程B的优先级+1(优先级降低), 成为nice=1, 那么其CPU份额应该减少10%, 换句话说进程A得到的总的CPU应该是55%, 而进程B应该是45%. 优先级增加1导致权重减少, 即1024/1.25=820, 而进程A仍旧是1024, 则进程A现在将得到的CPU份额是1024/(1024+820=0.55, 而进程B的CPU份额则是820/(1024+820)=0.45. 这样就正好产生了10%的差值.
4 进程负荷权重的计算
set_load_weight负责根据非实时进程类型极其静态优先级计算符合权重
而实时进程不需要CFS调度, 因此无需计算其负荷权重值
早期的代码中实时进程也是计算其负荷权重的, 但是只是采用一些方法保持其权重值较大
在早期有些版本中, set_load_weight中实时进程的权重是普通进程的两倍, 后来又设置成0, 直到后来linux-2.6.37开始不再设置实时进程的优先级, 因此这本身就是一个无用的工作
而另一方面, SCHED_IDLE进程的权值总是非常小, 普通非实时进程则根据其静态优先级设置对应的负荷权重
4.1 set_load_weight依据静态优先级设置进程的负荷权重
static void set_load_weight(struct task_struct *p)
{
/* 由于数组中的下标是0~39, 普通进程的优先级是[100~139]
因此通过static_prio - MAX_RT_PRIO将静态优先级转换成为数组下标
*/
int prio = p->static_prio - MAX_RT_PRIO;
/* 取得指向进程task负荷权重的指针load,
下面修改load就是修改进程的负荷权重 */
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
* 必须保证SCHED_IDLE进程的负荷权重最小
* 其权重weight就是WEIGHT_IDLEPRIO
* 而权重的重除结果就是WMULT_IDLEPRIO
*/
if (p->policy == SCHED_IDLE) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
/* 设置进程的负荷权重weight和权重的重除值inv_weight */
load->weight = scale_load(prio_to_weight[prio]);
load->inv_weight = prio_to_wmult[prio];
}
4.2 scale_load取得负荷权重的值
其中scale_load是一个宏, 定义在include/linux/sched.h, line 785
#if 0 /* BITS_PER_LONG > 32 -- currently broken: it increases power usage under light load */
# define SCHED_LOAD_RESOLUTION 10
# define scale_load(w) ((w) << SCHED_LOAD_RESOLUTION)
# define scale_load_down(w) ((w) >> SCHED_LOAD_RESOLUTION)
#else
# define SCHED_LOAD_RESOLUTION 0
# define scale_load(w) (w)
# define scale_load_down(w) (w)
#endif
我们可以看到目前版本的scale_load其实什么也没做就是简单取了个值, 但是我们注意到负荷权重仍然保留了SCHED_LOAD_RESOLUTION不为0的情形, 只不过目前因为效率原因和功耗问题没有启用而已
4.3 set_load_weight的演变
linux内核的调度器经过了不同阶段的发展, 但是即使是同一个调度器其算法也不是一成不变的, 也在不停的改进和优化
| 内核版本 | 实现 | 地址 |
|---|---|---|
| 2.6.18~2.6.22 | 实时进程的权重用RTPRIO_TO_LOAD_WEIGHT(p->rt_priority);转换 | kernel/sched.c#L746 |
| 2.6.23~2.6.34 | 实时进程的权重为非实时权重的二倍 | kernel/sched.c#L1836 |
| 2.6.35~2.6.36 | 实时进程的权重设置为0, 重除值设置为WMULT_CONST | kernel/sched.c, L1859 |
| 2.6.37~至今4.6 | 实时进程不再设置权重 | 其中<= linux-3.2时, 代码在sched.c中 3.3~4.4之后, 增加了sched/core.c文件调度的核心代码在此存放 4.5~至今, 修改prio_to_weight为sched_prio_to_weight, 并将声明存放头文件中 |
5 就绪队列的负荷权重
不仅进程, 就绪队列也关联到一个负荷权重. 这个我们在前面讲Linux进程调度器的设计–Linux进程的管理与调度(十七)的时候提到过了在cpu的就绪队列rq和cfs调度器的就绪队列cfs_rq中都保存了其load_weight.
这样不仅确保就绪队列能够跟踪记录有多少进程在运行, 而且还能将进程的权重添加到就绪队列中.
5.1 cfs就绪队列的负荷权重
// http://lxr.free-electrons.com/source/kernel/sched/sched.h?v=4.6#L596
struct rq
{
/* ...... */
/* capture load from *all* tasks on this cpu: */
struct load_weight load;
/* ...... */
};
// http://lxr.free-electrons.com/source/kernel/sched/sched.h?v=4.6#L361
/* CFS-related fields in a runqueue */
struct cfs_rq
{
struct load_weight load;
unsigned int nr_running, h_nr_running;
/* ...... */
};
// http://lxr.free-electrons.com/source/kernel/sched/sched.h?v=4.6#L596
struct rt_rq中不需要负荷权重
// http://lxr.free-electrons.com/source/kernel/sched/sched.h?v=4.6#L490
struct dl_rq中不需要负荷权重
由于负荷权重仅用于调度普通进程(非实时进程), 因此只在cpu的就绪队列队列rq和cfs调度器的就绪队列cfs_rq上需要保存其就绪队列的信息, 而实时进程的就绪队列rt_rq和dl_rq 是不需要保存负荷权重的.
5.2 就绪队列的负荷权重计算
就绪队列的负荷权重存储的其实就是队列上所有进程的负荷权重的总和, 因此每次进程被加到就绪队列的时候, 就需要在就绪队列的负荷权重中加上进程的负荷权重, 同时由于就绪队列的不是一个单独被调度的实体, 也就不需要优先级到负荷权重的转换, 因而其不需要负荷权重的重除字段, 即inv_weight = 0;
因此进程从就绪队列上入队或者出队的时候, 就绪队列的负荷权重就加上或者减去进程的负荷权重, 但是
//struct load_weight {
/* 就绪队列的负荷权重 +/- 入队/出队进程的负荷权重 */
unsigned long weight +/- task_struct->se->load->weight;
/* 就绪队列负荷权重的重除字段无用途,所以始终置0 */
u32 inv_weight = 0;
//};
因此内核为我们提供了增加/减少/重置就绪队列负荷权重的的函数, 分别是update_load_add, update_load_sub, update_load_set
/* 使得lw指向的负荷权重的值增加inc, 用于进程进入就绪队列时调用
* 进程入队 account_entity_enqueue kernel/sched/fair.c#L2422
*/
static inline void update_load_add(struct load_weight *lw, unsigned long inc)
{
lw->weight += inc;
lw->inv_weight = 0;
}
/* 使得lw指向的负荷权重的值减少inc, 用于进程调出就绪队列时调用
* 进程出队 account_entity_dequeue kernel/sched/fair.c#L2422*/
static inline void update_load_sub(struct load_weight *lw, unsigned long dec)
{
lw->weight -= dec;
lw->inv_weight = 0;
}
static inline void update_load_set(struct load_weight *lw, unsigned long w)
{
lw->weight = w;
lw->inv_weight = 0;
}
| 函数 | 描述 | 调用时机 | 定义位置 | 调用位置 |
|---|---|---|---|---|
| update_load_add | 使得lw指向的负荷权重的值增加inc | 用于进程进入就绪队列时调用 | kernel/sched/fair.c, L117 | account_entity_enqueue两处, sched_slice |
| update_load_sub | 使得lw指向的负荷权重的值减少inc | 用于进程调出就绪队列时调用 | update_load_sub, L123 | account_entity_dequeue两处 |
| update_load_set |
其中sched_slice函数计算当前进程在调度延迟内期望的运行时间, 它根据cfs就绪队列中进程数确定一个最长时间间隔,然后看在该时间间隔内当前进程按照权重比例执行
Linux CFS调度器之负荷权重load_weight--Linux进程的管理与调度(二十五)的更多相关文章
- Linux进程上下文切换过程context_switch详解--Linux进程的管理与调度(二十一)
1 前景回顾 1.1 Linux的调度器组成 2个调度器 可以用两种方法来激活调度 一种是直接的, 比如进程打算睡眠或出于其他原因放弃CPU 另一种是通过周期性的机制, 以固定的频率运行, 不时的检测 ...
- Linux唤醒抢占----Linux进程的管理与调度(二十三)
1. 唤醒抢占 当在try_to_wake_up/wake_up_process和wake_up_new_task中唤醒进程时, 内核使用全局check_preempt_curr看看是否进程可以抢占当 ...
- Linux进程退出详解(do_exit)--Linux进程的管理与调度(十四)
Linux进程的退出 linux下进程退出的方式 正常退出 从main函数返回return 调用exit 调用_exit 异常退出 调用abort 由信号终止 _exit, exit和_Exit的区别 ...
- Linux进程ID号--Linux进程的管理与调度(三)
转自:http://blog.csdn.net/gatieme/article/category/6225543 日期 内核版本 架构 作者 GitHub CSDN 2016-05-12 Linux- ...
- Linux进程ID号--Linux进程的管理与调度(三)【转】
Linux 内核使用 task_struct 数据结构来关联所有与进程有关的数据和结构,Linux 内核所有涉及到进程和程序的所有算法都是围绕该数据结构建立的,是内核中最重要的数据结构之一. 该数据结 ...
- Linux CFS调度器之虚拟时钟vruntime与调度延迟--Linux进程的管理与调度(二十六)
1 虚拟运行时间(今日内容提醒) 1.1 虚拟运行时间的引入 CFS为了实现公平,必须惩罚当前正在运行的进程,以使那些正在等待的进程下次被调度. 具体实现时,CFS通过每个进程的虚拟运行时间(vrun ...
- Linux CFS调度器之队列操作--Linux进程的管理与调度(二十七)
1. CFS进程入队和出队 完全公平调度器CFS中有两个函数可用来增删队列的成员:enqueue_task_fair和dequeue_task_fair分别用来向CFS就绪队列中添加或者删除进程 2 ...
- Linux CFS调度器之唤醒抢占--Linux进程的管理与调度(三十)
我们也讲解了CFS的很多进程操作 table th:nth-of-type(1){ width: 20%; } table th:nth-of-type(2){ width: 20% ; } 信息 函 ...
- Linux CFS调度器之pick_next_task_fair选择下一个被调度的进程--Linux进程的管理与调度(二十八)
1. CFS如何选择最合适的进程 每个调度器类sched_class都必须提供一个pick_next_task函数用以在就绪队列中选择一个最优的进程来等待调度, 而我们的CFS调度器类中, 选择下一个 ...
随机推荐
- 【原创】Python第二章——字符串
字符串是一个字符序列,(提醒:序列是Python的一个重要的关键词),其中存放UNICODE字符.Python中的字符串是不可变的(immutable),即对字符串执行操作时,总是产生一个新的字符串而 ...
- Go基础系列:指定goroutine的执行顺序
Go channel系列: channel入门 为select设置超时时间 nil channel用法示例 双层channel用法示例 指定goroutine的执行顺序 当关闭一个channel时,会 ...
- Ansible常用模块介绍及使用(week5_day1_part2)--技术流ken
Ansible模块 在上一篇博客<Ansible基础认识及安装使用详解(一)--技术流ken>中以及简单的介绍了一下ansible的模块.ansible是基于模块工作的,所以我们必须掌握几 ...
- 第一册:lesson seventy five。
原文: Uncomfortable Shoes. Do you have any shoes like this? What size? Size five. What color? Black. I ...
- 4.2 explain 之 select_type
一.查询类型,主要用于区别 普通查询.联合查询.子查询等的复杂查询 二.常用常见的类型 1. simple : 简单的select查询,查询中不包含子查询或union 2. primary : 查询中 ...
- 【Spring】28、Spring中基于Java的配置@Configuration和@Bean用法.代替xml配置文件
Spring中为了减少xml中配置,可以生命一个配置类(例如SpringConfig)来对bean进行配置. 一.首先,需要xml中进行少量的配置来启动Java配置: <?xml version ...
- 浅谈spring中AOP以及spring中AOP的注解方式
AOP(Aspect Oriented Programming):AOP的专业术语是"面向切面编程" 什么是面向切面编程,我的理解就是:在不修改源代码的情况下增强功能.好了,下面在 ...
- 51单片机定时器实现LED闪烁
要启用一个定时器,先要开启定时器,然后产生中断 系统中断: 初始化程序应完成如下工作: 对TMOD赋值,以确定T0和T1的工作方式. 计算初值,并将其写入TH0.TL0或TH1.TL1. 中断方式时, ...
- 洛谷P4841 城市规划(生成函数 多项式求逆)
题意 链接 Sol Orz yyb 一开始想的是直接设\(f_i\)表示\(i\)个点的无向联通图个数,枚举最后一个联通块转移,发现有一种情况转移不到... 正解是先设\(g(n)\)表示\(n\)个 ...
- 洛谷P2000 拯救世界(生成函数)
题面 题目链接 Sol 生成函数入门题 至多为\(k\)就是\(\frac{1-x^{k+1}}{1-x}\) \(k\)的倍数就是\(\frac{1}{1-x^k}\) 化简完了就只剩下一个\(\f ...