6.3 OrderBy 优化
1. 创建实例
create table tblA(
age int,
birth TIMESTAMP not null
); insert into tblA(age,birth) values(22,now());
insert into tblA(age,birth) values(23,now());
insert into tblA(age,birth) values(24,now()); create index idx_A_ageBirth no tblA(age,birth); select * from tblA;
2.查询实例
a.
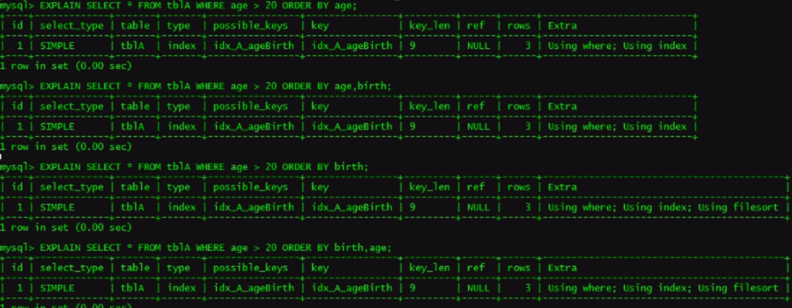
b.
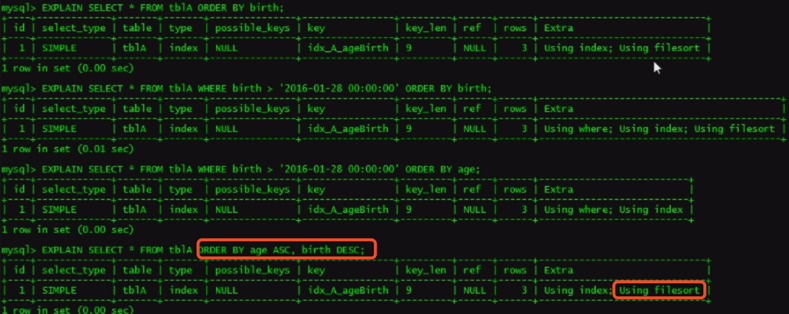
小总结:OrderBy满足两种情况,会使用Index方式排序
order by 语句使用索引最左前列。
使用where子句与Order by 子句条件列组合满足索引最左前列。
3. 如果不在索引列上,filesort有两种算法(双路排序、单路排序)
双路排序:
mysql4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,
读取行指针和orderby列,对他们进行排序,然后扫描已经排好序的列表,按照列表中的值重新从列表中读取对应的数据输出。
取一批数据,要对磁盘惊进行两次扫描,众所周知,I/O是很耗时间,所以在mysql4.1之后,出现了第二种改进的算法,就是单路排序。 单路排序:
从磁盘读取查询需要的所有列,按照orderby列在buffer对他们进行排序,然后扫描排序后的列表进行输出,
它的效率更快一些,避免了第二次读取数据。并且把随机IO变成了顺序IO,但是它会使用等多的空间,因为他的每一行数据都是保存在内存中。 单路排序引发的问题:
在sort_buffer中,单路比双路要多占用很多空间,因为单路是把所有的数据都去出来,所以可能取出的数据总大小超出了sort_buffer的容量,导致每次只能取sort_buffer容量大小的数据,进行排序(创建tmp文件,多路合并),排完再取sort_buffer容量大小,再排……从而多次I/O。
本来想省一次I/O操作,反而导致了大量的I/O操作,反而得不偿失。
优化策略:
增大sort_buffer_size参数的设置
增大max_length_for_sort_data参数设置 why? 1. Order by时select * 是一个大忌Query需要的字段,这点非常重要。在这里的影响是:
a. 当Query的字段大小总和小于max_length_for_sort_data而且排序字段不是TEXT|BLOB类时,会用改进后的算法——单路排序,否则用老算法——多路排序。
b. 两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O,但是用单路排序算法的风险会更大一些,所以要提高sort_buffer_size。 2. 尝试提高sort_buffer_size
不管用哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的。 3.尝试提高max_length_for_sort_data
提高这个参数,会增加用改进算法的概率,但是如果设的太高,数据总容量超出sort_buffer_size的概率就会增大,明显症状就是高的磁盘I/O活动和低的处理器使用率。
小总结:


关注我的公众号,精彩内容不能错过
6.3 OrderBy 优化的更多相关文章
- MySQL高级优化
MySQL高级 1.索引是什么? (1)索引是排好序可以快速查找的数据结构 (2)方便快速查找,索引实际上也是一张表所以也是要占内存的 2.索引存在哪里? (1)InnoDB引擎 ①索引是和数据存放在 ...
- mysql随笔
MySQL查询优化器--非SPJ的优化 MySQL查询优化器--非SPJ优化(一)--GROUPBY优化 http://blog.163.com/li_hx/blog/static/183991413 ...
- MySQL泛泛而谈(3W字)
下面对于MySQL进行相关介绍,文档的内容较为基础,仅仅设计操作,少量原理,大佬请绕道哦. 废话少说,开冲! 一.MySQL架构介绍 1-MySQL简介 概述 MySQL是一个关系型数据库管理系统,由 ...
- hive 的分隔符、orderby sort by distribute by的优化
一.Hive 分号字符 分号是SQL语句结束标记,在HiveQL中也是,可是在HiveQL中,对分号的识别没有那么智慧,比如: select concat(cookie_id,concat(';',' ...
- 记一次mysql关于limit和orderby的优化
针对于大数据量查询,我们一般使用分页查询,查询出对应页的数据即可,这会大大加快查询的效率: 在排序和分页同时进行时,我们一定要注意效率问题,例如: select a.* from table1 a i ...
- 【C#代码实战】群蚁算法理论与实践全攻略——旅行商等路径优化问题的新方法
若干年前读研的时候,学院有一个教授,专门做群蚁算法的,很厉害,偶尔了解了一点点.感觉也是生物智能的一个体现,和遗传算法.神经网络有异曲同工之妙.只不过当时没有实际需求学习,所以没去研究.最近有一个这样 ...
- 深入浅出聊优化:从Draw Calls到GC
前言: 刚开始写这篇文章的时候选了一个很土的题目...<Unity3D优化全解析>.因为这是一篇临时起意才写的文章,而且陈述的都是既有的事实,因而给自己“文(dou)学(bi)”加工留下的 ...
- SQL优化案例—— RowNumber分页
将业务语句翻译成SQL语句不仅是一门技术,还是一门艺术. 下面拿我们程序开发工程师最常用的ROW_NUMBER()分页作为一个典型案例来说明. 先来看看我们最常见的分页的样子: WITH CTE AS ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
随机推荐
- eclipse不支持sun.*包的问题处理
在项目中使用BASE64Decoder,eclipse的编辑器莫名报错, Multiple markers at this line - Access restriction: The type BA ...
- all about
1.三次握手和四次挥手?2.什么是OSI七层结构?3.http vs https?4.what is Ping?基于什么协议?使用方法?5.DNS?6.cookie vs session?7.LDAP ...
- PHP中 PCRE正则表达式模式修饰符“u” 的使用。
u (PCRE_UTF8) 此修正符打开一个与 perl 不兼容的附加功能. 模式字符串被认为是utf-8的. 这个修饰符 从 unix 版php 4.1.0 或更高,win32版 php 4.2.3 ...
- CSS3中的一些属性
1. 可匹配部分字符串 2. box-sizing属性 3. CSS3多栏布局 1.可匹配部分字符串 /*^运算符,匹配字符串首部*/ a[href^='http://website'] /*$运算符 ...
- 高手养成计划基础篇-Linux第二季
高手养成计划基础篇-Linux第二季 本文来源:i春秋社区-分享你的技术,为安全加点温度 前言 前面我们学习了文件处理命令和文件搜索命令,简单的了解了一下Linux,但是仅仅了解这样还不行,遇 ...
- Android7.0适配APK安装
Android7.0适配APK安装 适配的原因 对于面向Android7.0的应用,Android框架执行的StrictMode API政策禁止在您的应用外部公开file://URL.如果一项包含文件 ...
- lazy-init 懒加载的艺术
懒加载是一种加载方式,加载单例对象一般有两种方式,一是在启动时就立即创建好,另一种则是在需要用到的时候再去加载即懒加载.懒加载一般会针对单例场景,且一般是针对在加载消耗较大费时,且不一定会用到的场景. ...
- SpringBoot中集成redis
转载:https://www.cnblogs.com/zeng1994/p/03303c805731afc9aa9c60dbbd32a323.html 不是使用注解而是代码调用 需要在springbo ...
- 寒假小软件开发记录06--apk生成
先在strings.xml中修改了软件名称,再修改软件图标. 在Android模式下,进入Image Asset,进行图标的修改: android studio中,build->generate ...
- .Net Core新建解决方案,添加项目引用,使用VSCode调试
并不是我自己琢磨的,是看了别人学习的,因为写的都不完整,所以就整理一下记录后面忘了回看. 反正.Net Core是跨平台的,就不说在什么系统上了.假设我要建一个名为Doggie的解决方案,里面包含了一 ...