数据挖掘(二)——Knn算法的java实现
1、K-近邻算法(Knn)
其原理为在一个样本空间中,有一些已知分类的样本,当出现一个未知分类的样本,则根据距离这个未知样本最近的k个样本来决定。
举例:爱情电影和动作电影,它们中都存在吻戏和动作,出现一个未知分类的电影,将根据以吻戏数量和动作数量建立的坐标系中距离未知分类所在点的最近的k个点来决定。
2、算法实现步骤
(1)计算所有点距离未知点的欧式距离
(2)对所有点进行排序
(3)找到距离未知点最近的k个点
(4)计算这k个点所在分类出现的频率
(5)选择频率最大的分类即为未知点的分类
3、java实现
Point类
public class Point {
private long id;
private double x;
private double y;
private String type;
public Point(long id,double x, double y) {
this.x = x;
this.y = y;
this.id = id;
}
public Point(long id,double x, double y, String type) {
this.x = x;
this.y = y;
this.type = type;
this.id = id;
}
//get、set方法省略
}
Distance类
public class Distance {
// 已知点id
private long id;
// 未知点id
private long nid;
// 二者之间的距离
private double disatance;
public Distance(long id, long nid, double disatance) {
this.id = id;
this.nid = nid;
this.disatance = disatance;
}
//get、set方法省略
}
比较器CompareClass类
import java.util.Comparator;
//比较器类
public class CompareClass implements Comparator<Distance>{ public int compare(Distance d1, Distance d2) {
return d1.getDisatance()>d2.getDisatance()?20 : -1;
} }
KNN主类
/**
*
1、输入所有已知点
2、输入未知点
3、计算所有已知点到未知点的欧式距离
4、根据距离对所有已知点排序
5、选出距离未知点最近的k个点
6、计算k个点所在分类出现的频率
7、选择频率最大的类别即为未知点的类别
*
* @author fzj
*
*/
public class KNN { public static void main(String[] args) { // 一、输入所有已知点
List<Point> dataList = creatDataSet();
// 二、输入未知点
Point x = new Point(5, 1.2, 1.2);
// 三、计算所有已知点到未知点的欧式距离,并根据距离对所有已知点排序
CompareClass compare = new CompareClass();
Set<Distance> distanceSet = new TreeSet<Distance>(compare);
for (Point point : dataList) {
distanceSet.add(new Distance(point.getId(), x.getId(), oudistance(point,
x)));
}
// 四、选取最近的k个点
double k = 5; /**
* 五、计算k个点所在分类出现的频率
*/
// 1、计算每个分类所包含的点的个数
List<Distance> distanceList= new ArrayList<Distance>(distanceSet);
Map<String, Integer> map = getNumberOfType(distanceList, dataList, k); // 2、计算频率
Map<String, Double> p = computeP(map, k); x.setType(maxP(p));
System.out.println("未知点的类型为:"+x.getType());
} // 欧式距离计算
public static double oudistance(Point point1, Point point2) {
double temp = Math.pow(point1.getX() - point2.getX(), 2)
+ Math.pow(point1.getY() - point2.getY(), 2);
return Math.sqrt(temp);
} // 找出最大频率
public static String maxP(Map<String, Double> map) {
String key = null;
double value = 0.0;
for (Map.Entry<String, Double> entry : map.entrySet()) {
if (entry.getValue() > value) {
key = entry.getKey();
value = entry.getValue();
}
}
return key;
} // 计算频率
public static Map<String, Double> computeP(Map<String, Integer> map,
double k) {
Map<String, Double> p = new HashMap<String, Double>();
for (Map.Entry<String, Integer> entry : map.entrySet()) {
p.put(entry.getKey(), entry.getValue() / k);
}
return p;
} // 计算每个分类包含的点的个数
public static Map<String, Integer> getNumberOfType(
List<Distance> listDistance, List<Point> listPoint, double k) {
Map<String, Integer> map = new HashMap<String, Integer>();
int i = 0;
System.out.println("选取的k个点,由近及远依次为:");
for (Distance distance : listDistance) {
System.out.println("id为" + distance.getId() + ",距离为:"
+ distance.getDisatance());
long id = distance.getId();
// 通过id找到所属类型,并存储到HashMap中
for (Point point : listPoint) {
if (point.getId() == id) {
if (map.get(point.getType()) != null)
map.put(point.getType(), map.get(point.getType()) + 1);
else {
map.put(point.getType(), 1);
}
}
}
i++;
if (i >= k)
break;
}
return map;
} public static ArrayList<Point> creatDataSet(){ Point point1 = new Point(1, 1.0, 1.1, "A");
Point point2 = new Point(2, 1.0, 1.0, "A");
Point point3 = new Point(3, 1.0, 1.2, "A");
Point point4 = new Point(4, 0, 0, "B");
Point point5 = new Point(5, 0, 0.1, "B");
Point point6 = new Point(6, 0, 0.2, "B"); ArrayList<Point> dataList = new ArrayList<Point>();
dataList.add(point1);
dataList.add(point2);
dataList.add(point3);
dataList.add(point4);
dataList.add(point5);
dataList.add(point6); return dataList;
}
}
4、运行结果
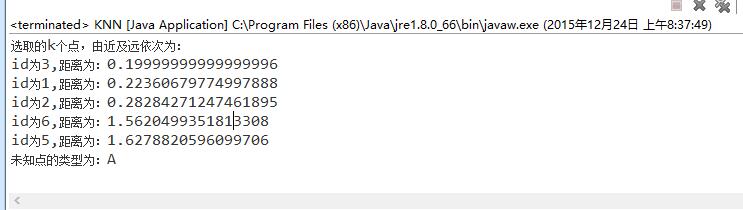
参考
[1] 《机器学习实战》
数据挖掘(二)——Knn算法的java实现的更多相关文章
- 数据挖掘之KNN算法(C#实现)
在十大经典数据挖掘算法中,KNN算法算得上是最为简单的一种.该算法是一种惰性学习法(lazy learner),与决策树.朴素贝叶斯这些急切学习法(eager learner)有所区别.惰性学习法仅仅 ...
- KNN算法java实现代码注释
K近邻算法思想非常简单,总结起来就是根据某种距离度量检测未知数据与已知数据的距离,统计其中距离最近的k个已知数据的类别,以多数投票的形式确定未知数据的类别. 一直想自己实现knn的java实现,但限于 ...
- KNN算法介绍及源码实现
一.KNN算法介绍 邻近算法,或者说K最邻近(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一.所谓K最近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它 ...
- 深入浅出KNN算法(一) KNN算法原理
一.KNN算法概述 KNN可以说是最简单的分类算法之一,同时,它也是最常用的分类算法之一,注意KNN算法是有监督学习中的分类算法,它看起来和另一个机器学习算法Kmeans有点像(Kmeans是无监督学 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
- KNN算法 - 数据挖掘算法(3)
(2017-04-10 银河统计) KNN算法即K Nearest Neighbor算法.这个算法是机器学习里面一个比较经典的.相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法 ...
- 机器学习之二:K-近邻(KNN)算法
一.概述 K最近邻(k-Nearest Neighbor,KNN)分类算法,是一个理论上比较成熟的方法,也是最简单的机器学习算法之一.该方法的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中 ...
- 深入浅出KNN算法(二) sklearn KNN实践
姊妹篇: 深入浅出KNN算法(一) 原理介绍 上次介绍了KNN的基本原理,以及KNN的几个窍门,这次就来用sklearn实践一下KNN算法. 一.Skelarn KNN参数概述 要使用sklearnK ...
- CRC16算法之二:CRC16-CCITT-XMODEM算法的java实现
CRC16算法系列文章: CRC16算法之一:CRC16-CCITT-FALSE算法的java实现 CRC16算法之二:CRC16-CCITT-XMODEM算法的java实现 CRC16算法之三:CR ...
随机推荐
- pytorch 损失函数
pytorch损失函数: http://blog.csdn.net/zhangxb35/article/details/72464152?utm_source=itdadao&utm_medi ...
- 解决Ubuntu自带编译器不好使问题
解决Ubuntu自带编译器不好使问题 1.删除Ubuntu自带的tiny版本,这个版本用起来很别扭不好使. 2.安装full版本的vim 3.显示效果:full版本. 之前自带的版本:
- 【Solidity】学习(3)
函数 重定义 不支持重定义,会在编译时候报错 pragma solidity ^0.4.0; contract test { uint public a =100; function changeA ...
- LeetCode刷题:第一题 两数之和
从今天开始刷LeetCode 第一题:两数之和 题目描述: 给定一个整数数组 nums 和一个目标值 target,请你在该数组中找出和为目标值的那 两个 整数,并返回他们的数组下标. 你可以假设每种 ...
- logminer日志挖掘
参考自:https://blog.csdn.net/yes_is_ok/article/details/79296614 原文转自:http://blog.itpub.net/26736162/vie ...
- 在码云(gitee)上展开程序类课程教学
码云主要提供了源代码管理(Git/SVN)功能,最近又推出了高校版让普通老师也能利用起来以供教学使用. 学生与老师不仅能利用其管理代码,更重要的是我们的程序教学能通过对git的使用来引入业界流行的软件 ...
- Android开发 - 掌握ConstraintLayout(十一)复杂动画!如此简单!
介绍 本系列我们已经介绍了ConstraintLayout的基本用法.学习到这里,相信你已经熟悉ConstraintLayout的基本使用了,如果你对它的用法还不了解,建议您先阅读我之前的文章. 使用 ...
- Android P正式版即将到来:后台应用保活、消息推送的真正噩梦
1.前言 对于广大Android开发者来说,Android O(即Android 8.0)还没玩热,Andriod P(即Andriod 9.0)又要来了. 下图上谷歌官方公布的Android P ...
- 音视频编解码——LAME
一.LAME简介 LAME是目前非常优秀的一种MP3编码引擎,在业界,转码成Mp3格式的音频文件时,最常用的就是LAME库.当达到320Kbit/s时,LAME编码出来的音频质量几乎可以和CD的音质相 ...
- Javascript高级编程学习笔记(65)—— 事件(9)复合事件
复合事件 复合事件是 DOM3 中新增的一类事件,用于处理 IME 的输入序列 IME(输入法编辑器)通常用于输入物理键盘上找不到的字符,而这种输入方式通常需要同时按住多个键,但最终只输入一个字符 复 ...