爬取伯乐在线文章(五)itemloader
ItemLoader
在我们执行scrapy爬取字段中,会有大量的CSS或是Xpath代码,当要爬取的网站多了,要维护起来很麻烦,为解决这类问题,我们可以根据scrapy提供的loader机制。
导入ItemLoader
from scrapy.loader import ItemLoader
实例化ItemLoader对象
要使用Itemloader,必须先将它实例化。查看一下ItemLoader的源码,有2个重要的传入参数,item和response

# 通过ItemLoader对象实例化item
item_loader = ItemLoader(item=JobBoleArticleItem(), response=response)
# 针对CSS选择器
item_loader.add_css('title', '.entry-header h1::text')
item_loader.add_css('create_date', '.entry-meta .entry-meta-hide-on-mobile::text')
item_loader.add_css('praise_num', '.vote-post-up h10::text')
item_loader.add_css('collect_num', '.post-adds .bookmark-btn::text')
item_loader.add_css('comment_num', '.post-adds .hide-on-480::text')
# 针对直接取值的情况
item_loader.add_value('url', response.url)
item_loader.add_value('url_object_id', get_md5(response.url))
item_loader.add_value('front_image_url', [front_image_url])
# 把结果返回给item对象
article_item = item_loader.load_item()
Debug调试查看情况
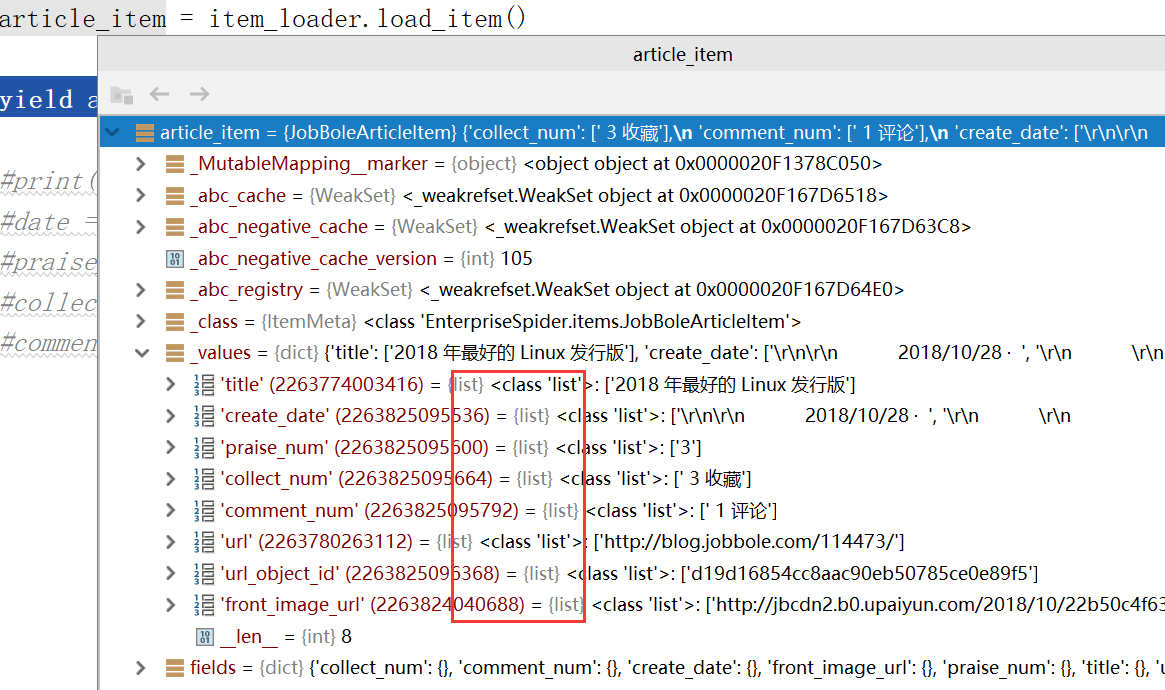
调用默认的item方法目前有2个问题:
(1)默认情况下传入的都是一些list
(2)像parise_num和comment_num传入的一些值我们还需要在进行一次过滤,加一些处理函数
MapCompose
如果解决上面两个问题?如何取list第一个值,如何在某些字段上加一些处理函数?为了解决这个问题,我们需要重新修改items.py,需要导入MapCompose类
from scrapy.loader.processors import MapCompose

MapCompose里面可以传入任意多的函数,也可以传入一些lambda表达式
title = scrapy.Field(
# 代表当item传入值的时候,我们可以对这些值进行一些预处理,MapCompose可以传入任意多个函数
input_processor = MapCompose(lambda x:x+"-jobbole")
)
此时在进行Debug调试,title上会添加-jobbole

我们可以在加入一个函数,现在MapCompose里面有一个lambda表达式,一个函数,Debug看是否能够连续处理

Debug

经测试可以从左到右依次连续进行处理
TakeFirst
那如何获取list中的第一个值,此时需要TakeFirst函数
导入
from scrapy.loader.processors import MapCompose, TakeFirst
调用
create_date = scrapy.Field(
input_processor = MapCompose(date_convert),
output_processor = TakeFirst()
)
Debug调试,此时获取的create_time就是一个date类型的值了而不是一个list
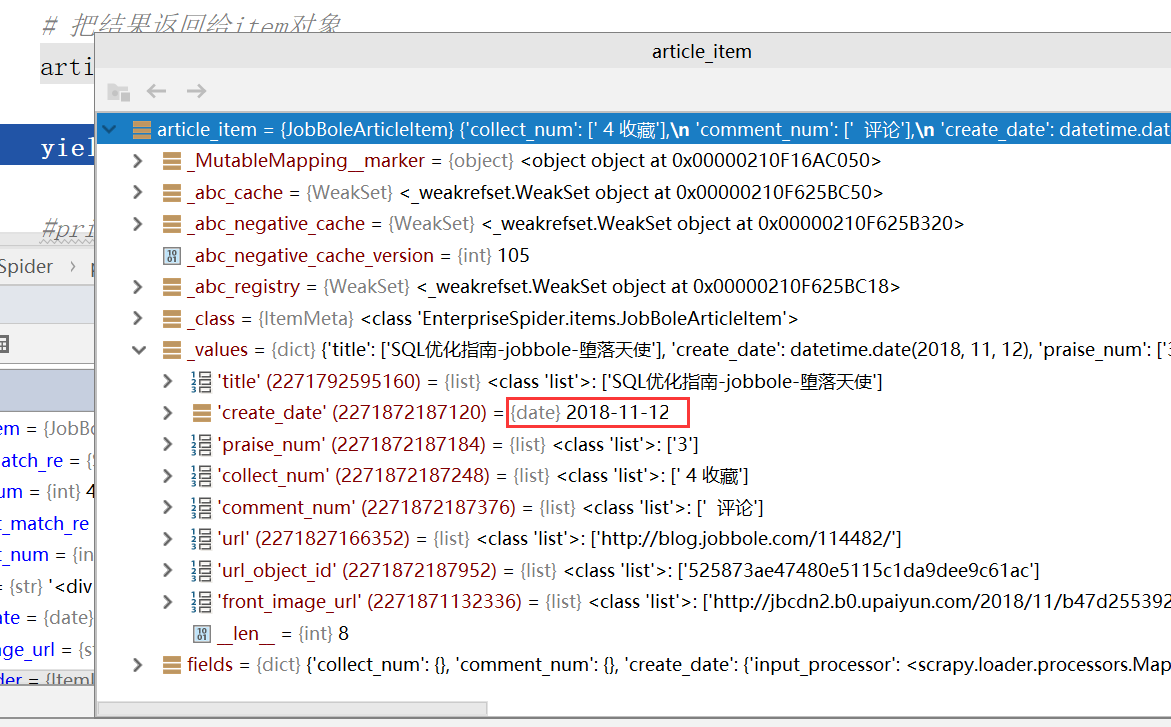
自定义ItemLoader
如果所有的字段都去第一个值,是否每个字段都需要添加
output_processor = TakeFirst()
此时太麻烦,我们可以自己定义一个ItemLoader,需要继承scrapy的ItemLoader类
from scrapy.loader import ItemLoader
class ArticleItemLoader(ItemLoader):
pass
查看ItemLoader的源码,有一个默认的

修改默认的default_output_processor方法
class ArticleItemLoader(ItemLoader):
default_output_processor = TakeFirst()
在修改我们爬虫里面ItemLoader为我们自定义的ItemLoader,在jobbole.py里面修改
from EnterpriseSpider.items import JobBoleArticleItem, ArticleItemLoader
# 通过ItemLoader对象实例化item
item_loader = ArticleItemLoader(item=JobBoleArticleItem(), response=response)
Debug调试,此时item返回的是单个的值而不是一个list
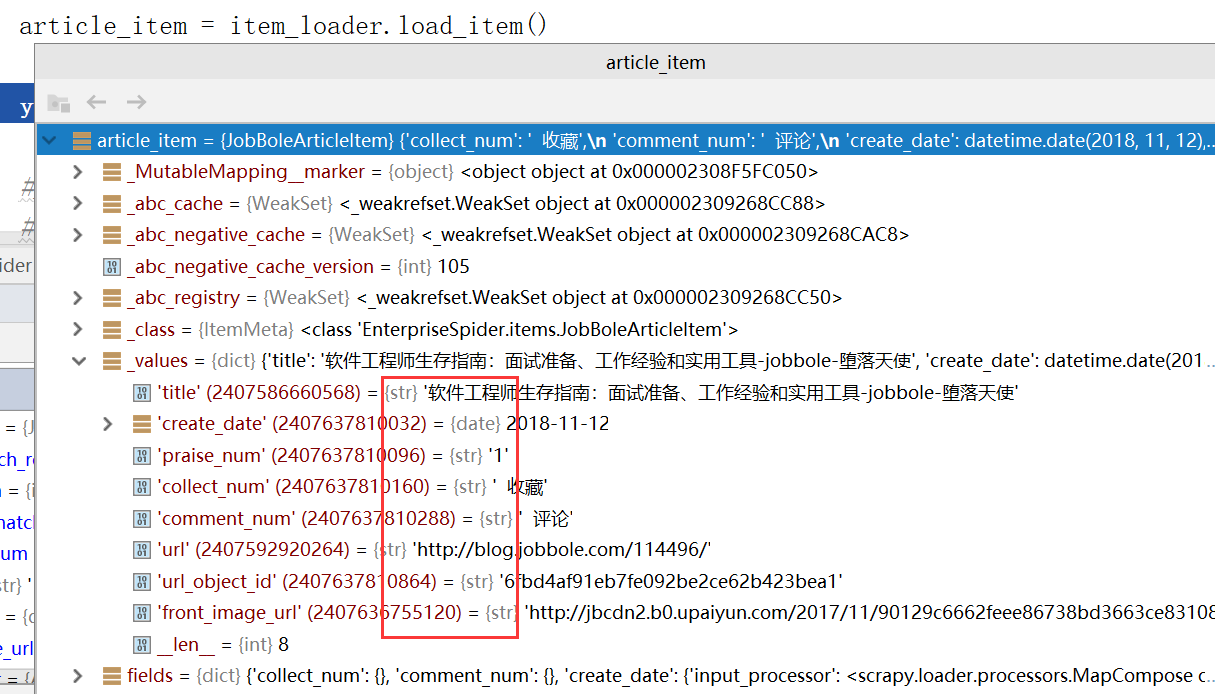
图片下载处理
此时返回的front_image_url是一个字符串,此时在交给ImagePipeline进行下载的时候就会抛出异常,我们必须覆盖掉默认的output_processor方法
def return_value(value):
return value
front_image_url = scrapy.Field(
output_processor=MapCompose(return_value)
)
此时还需要修改插入数据库的语句,还需要修改ArticleImagePipeline
class ArticleImagePipeline(ImagesPipeline):
def item_completed(self, results, item, info):
if "front_image_url" in item:
for ok, value in results:
image_file_path = value["path"]
item["front_image_url"] = image_file_path
return item
default_output_processor
爬取伯乐在线文章(五)itemloader的更多相关文章
- 爬取伯乐在线文章(四)将爬取结果保存到MySQL
Item Pipeline 当Item在Spider中被收集之后,它将会被传递到Item Pipeline,这些Item Pipeline组件按定义的顺序处理Item. 每个Item Pipeline ...
- 第三天,爬取伯乐在线文章代码,编写items.py,保存数据到本地json文件中
一. 爬取http://blog.jobbole.com/all-posts/中的所有文章 1. 编写jobbole.py简单代码 import scrapy from scrapy. ...
- 爬取伯乐在线文章(二)通过xpath提取源文件中需要的内容
爬取说明 以单个页面为例,如:http://blog.jobbole.com/110287/ 我们可以提取标题.日期.多少个评论.正文内容等 Xpath介绍 1. xpath简介 (1) xpath使 ...
- Scrapy爬取伯乐在线文章
首先搭建虚拟环境,创建工程 scrapy startproject ArticleSpider cd ArticleSpider scrapy genspider jobbole blog.jobbo ...
- scrapy爬取伯乐在线文章数据
创建项目 切换到ArticleSpider目录下创建爬虫文件 设置settings.py爬虫协议为False 编写启动爬虫文件main.py
- python爬虫scrapy框架——爬取伯乐在线网站文章
一.前言 1. scrapy依赖包: 二.创建工程 1. 创建scrapy工程: scrapy staratproject ArticleSpider 2. 开始(创建)新的爬虫: cd Artic ...
- 爬虫实战——Scrapy爬取伯乐在线所有文章
Scrapy简单介绍及爬取伯乐在线所有文章 一.简说安装相关环境及依赖包 1.安装Python(2或3都行,我这里用的是3) 2.虚拟环境搭建: 依赖包:virtualenv,virtualenvwr ...
- Scrapy爬取伯乐在线的所有文章
本篇文章将从搭建虚拟环境开始,爬取伯乐在线上的所有文章的数据. 搭建虚拟环境之前需要配置环境变量,该环境变量的变量值为虚拟环境的存放目录 1. 配置环境变量 2.创建虚拟环境 用mkvirtualen ...
- Scrapy基础(六)————Scrapy爬取伯乐在线一通过css和xpath解析文章字段
上次我们介绍了scrapy的安装和加入debug的main文件,这次重要介绍创建的爬虫的基本爬取有用信息 通过命令(这篇博文)创建了jobbole这个爬虫,并且生成了jobbole.py这个文件,又写 ...
随机推荐
- 设计模式—模板方法的C++实现
这是Bwar在2009年写的设计模式C++实现,代码均可编译可运行,一直存在自己的电脑里,曾经在团队技术分享中分享过,现搬到线上来. 1. 模板方法简述 1.1 目的 定义一个操作中的算法骨架,而将一 ...
- 通过示例学习JavaScript闭包
译者按: 在上一篇博客,我们通过实现一个计数器,了解了如何使用闭包(Closure),这篇博客将提供一些代码示例,帮助大家理解闭包. 原文: JavaScript Closures for Dummi ...
- WORLD 文件格式的保存
1,.docx 高版本格式. 该格式,高版本可以打开低版本的文件,低版本不一定能打开高版本的文件 2,.doc 兼容模式 高低版本都可以打开该格式的文件 3, .PDF文件格式 我把WORLD ...
- vuejs2.0与1.x版本中怎样使用js实时访问input的值的变化
vuejs 2.0中js实时监听input 在2.0的版本中,vuejs把v-el 和 v-ref 合并为一个 ref 属性了,可以在组件实例中通过 $refs 来调用.这意味着 v-el:my-el ...
- GitHub for Windows离线安装包
国内安装github客户端,真的很痛!! 偶然找到了离线安装包,感谢作者的资源分享!!! 地址:http://download.csdn.net/download/lyg468088/8723039? ...
- Python运维开发:运算符与数据类型(二)
python对象的相关术语: python程序中保存的所有数据都是围绕对象这个概念展开的: 程序中存储的所有数据都是对象 每个对象都有一个身份.一个类型和一个值 例如,school='MaGe Lin ...
- wangEditor更改默认高度
在使用WangEditor时觉得高度太低,默认是300px;想调下高度,借鉴https://blog.csdn.net/qq_31384551/article/details/83240188, 网址 ...
- CSS布局---居中方法
在web页面布局中居中是我们常遇到的情况,而居中分为水平居中与垂直居中 文本的居中 CSS中对文本的居中做的非常友好,我们是需要text-align, line-height 两个属性就可以控制文本的 ...
- SQL 中事务的分类
先讲下事务执行流程: BEGIN和COMMIT PRINT @@TRANCOUNT --@@TRANCOUNT统计事务数量 BEGIN TRAN PRINT @@TRANCOUNT BEGIN TRA ...
- SQL Server 2005 sp_send_dbmail出现Internal error at FormatRowset (Reason: Not enough storage is available to complete this operation)
案例环境: 操作系统: Windows 2003 SE 32bit(SP2) 数据库版本:Microsoft SQL Server 2005 - 9.00.5069.00 (Intel X86) Au ...