Azkaban任务流编写
在Azkaban中,一个project包含一个或多个flows,一个flow包含多个job。job是你想在azkaban中运行的一个进程,可以是Command,也可以是一个Hadoop任务。当然,如果你安装相关插件,也可以运行插件。一个job可以依赖于另一个job,这种多个job和它们的依赖组成的图表叫做flow。本文介绍如何在Azkaban上编写四类任务流:Command、Hive、Java、Hadoop。
1、Command任务编写
这里将模拟一个数据从采集到上传最后入库的整个过程的工作流。涉及的job如下:
create_dir.job:创建对应的目录
get_data1.job:获取数据1
get_data2.job:获取数据2
upload_to_hdfs.job:数据上传到hdfs
insert_to_hive.job:从hdfs入库到hive中
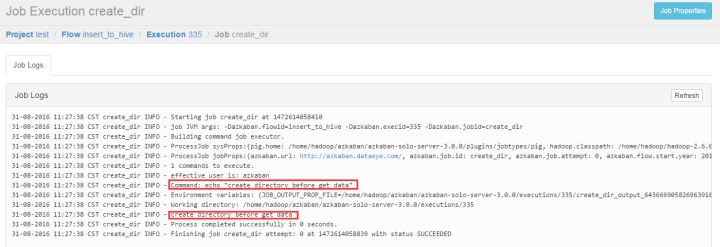
- create_dir.job
type=command
command=echo "create directory before get data"
- get_data1.job
type=command
command=echo "get data from logserver"
dependencies=create_dir
- get_data2.job
type=command
command=echo "get data from ftp"
dependencies=create_dir
- upload_to_hdfs.job
type=command
command=echo "upload to hdfs"
dependencies=get_data1,get_data2
完成后的目录如下
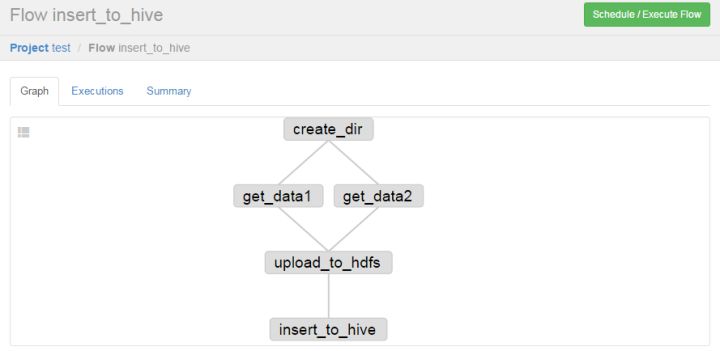
打包成demo.zip压缩包,并上传到Azkaban中,可以看到依赖图如下:
点击执行
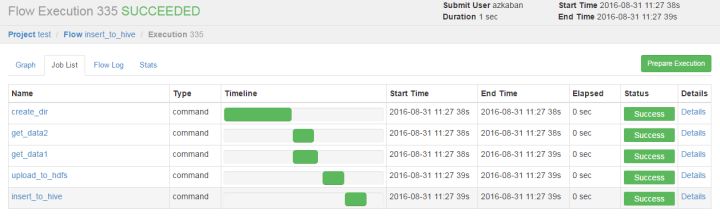
在Job List里可以看到每个job的运行情况
点击Details可以看到每个job执行的日志
Job中的其他配置选项
- 可以定义job依赖另一个flow
type=flow
flow.name=fisrt_flow
- 可以配置多个command命令
type=command
command=echo "hello"
command.1=echo "world"
command.2=echo "azkaban"
- 可以配置job失败重启次数,及间隔时间,比如,上述ftp获取日志,我可以配置重试12次,每隔5分钟一次
type=command
command=echo "retry test"
retries=12
#单位毫秒
retry.backoff=300000
2、Hive任务编写
Hive任务的编写比较简单,在新的目录下新建hive.job文件,内容如下
#定义类型
type=hive
#定义执行HiveSQL的用户
user.to.proxy=azkaban
#固定值
azk.hive.action=execute.query
hive.query.01=drop table words;
hive.query.02=create table words (freq int, word string) row format delimited fields terminated by '\t' stored as textfile;
hive.query.03=describe words;
hive.query.04=load data local inpath "res/input" into table words;
hive.query.05=select * from words limit 10;
hive.query.06=select freq, count(1) as f2 from words group by freq sort by f2 desc limit 10;
以上第四条语句涉及到数据文件,需要在同级目录下新建res文件夹,然后新建input文件,内容如下
11 and
10 the
9 to
9 in
9 of
9 is
9 CLAUDIUS
8 KING
8 this
8 we
7 what
7 us
7 GUILDENSTERN
6 And
5 d
4 ROSENCRANTZ
3 a
2 his
1 QUEEN
1 he
然后打包成zip文件即可上传到azkaban中运行
3、Java任务编写
Java任务比较简单,只需要在类里提供一个run方法即可,如果需要设定参数,着在构造方法中指定Props类,然后在job文件里配置好参数。
Java类如下
package com.dataeye.java;
import org.apache.log4j.Logger;
import azkaban.utils.Props;
public class JavaMain {
private static final Logger logger = Logger.getLogger(JavaMain.class);
private final int fileRows;
private final int fileLine;
public JavaMain(String name, Props props) throws Exception {
this.fileRows = props.getInt("file.rows");
this.fileLine = props.getInt("file.line");
}
public void run() throws Exception {
logger.info(" ### this is JavaMain method ###");
logger.info("fileRows value is ==> " + fileRows);
logger.info("fileLine value is ==> " + fileLine);
}
}
java.job文件如下
type=java
#指定类的全路径
job.class=com.dataeye.java.JavaMain
#指定执行jar包的路径
classpath=lib/*
#用户参数1
file.rows=10
#用户参数2
file.line=50
新建目录,把java.job拷贝到该目录下,然后新建lib文件夹,把以上java类打包成jar文件,放入lib目录下,打包成zip文件,上传到azkaban中。执行成功后的日志如下
31-08-2016 14:41:15 CST simple INFO - INFO Running job simple
31-08-2016 14:41:15 CST simple INFO - INFO Class name com.dataeye.java.JavaMain
31-08-2016 14:41:15 CST simple INFO - INFO Constructor found public com.dataeye.java.JavaMain(java.lang.String,azkaban.utils.Props) throws java.lang.Exception
31-08-2016 14:41:15 CST simple INFO - INFO Invoking method run
31-08-2016 14:41:15 CST simple INFO - INFO Proxy check failed, not proxying run.
31-08-2016 14:41:15 CST simple INFO - INFO ### this is JavaMain method ###
31-08-2016 14:41:15 CST simple INFO - INFO fileRows value is ==> 10
31-08-2016 14:41:15 CST simple INFO - INFO fileLine value is ==> 50
31-08-2016 14:41:15 CST simple INFO - INFO Apparently there isn't a method[getJobGeneratedProperties] on object[com.dataeye.java.JavaMain@591f989e], using empty Props object instead.
31-08-2016 14:41:15 CST simple INFO - INFO Outputting generated properties to /home/hadoop/azkaban/azkaban-solo-server-3.0.0/executions/339/simple_output_6034902760752438337_tmp
31-08-2016 14:41:15 CST simple INFO - Process completed successfully in 0 seconds.
31-08-2016 14:41:15 CST simple INFO - Finishing job simple attempt: 0 at 1472625675501 with status SUCCEEDED
日志中已经打印出run方法中的参数值。
4、Hadoop任务编写
Hadoop相对以上三种类型会复杂一些,需要注意的地方如下
- 必须继承 AbstractHadoopJob 类
public class WordCount extends AbstractHadoopJob
- 必须要有构造方法,参数是String和Props,且要调用super方法
public WordCount(String name, Props props) {
super(name, props);
//other code
}
- 必须提供run方法,且在run方法的最后调用super.run();
public void run() throws Exception{
//other code
super.run();}
下面提供一个 WordCount 任务的例子
WordCount.java类
package com.dataeye.mr;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
import org.apache.log4j.Logger;
import azkaban.jobtype.javautils.AbstractHadoopJob;
import azkaban.utils.Props;
import com.dataeye.mr.maper.WordCountMap;
import com.dataeye.mr.reducer.WordCountReduce;
public class WordCount extends AbstractHadoopJob {
private static final Logger logger = Logger.getLogger(WordCount.class);
private final String inputPath;
private final String outputPath;
private boolean forceOutputOverrite;
public WordCount(String name, Props props) {
super(name, props);
this.inputPath = props.getString("input.path");
this.outputPath = props.getString("output.path");
this.forceOutputOverrite = props.getBoolean("force.output.overwrite", false);
}
public void run() throws Exception {
logger.info(String.format("Hadoop job, class is %s", new Object[] { getClass().getSimpleName() }));
JobConf jobconf = getJobConf();
jobconf.setJarByClass(WordCount.class);
jobconf.setOutputKeyClass(Text.class);
jobconf.setOutputValueClass(IntWritable.class);
jobconf.setMapperClass(WordCountMap.class);
jobconf.setReducerClass(WordCountReduce.class);
jobconf.setInputFormat(TextInputFormat.class);
jobconf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.addInputPath(jobconf, new Path(this.inputPath));
FileOutputFormat.setOutputPath(jobconf, new Path(this.outputPath));
if (this.forceOutputOverrite) {
FileSystem fs = FileOutputFormat.getOutputPath(jobconf).getFileSystem(jobconf);
fs.delete(FileOutputFormat.getOutputPath(jobconf), true);
}
super.run();
}
}
WordCountMap.java类
package com.dataeye.mr.maper;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reporter;
public class WordCountMap extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
private long numRecords = 0L;
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
this.word.set(tokenizer.nextToken());
output.collect(this.word, one);
reporter.incrCounter(Counters.INPUT_WORDS, 1L);
}
if (++this.numRecords % 100L == 0L)
reporter.setStatus("Finished processing " + this.numRecords + " records " + "from the input file");
}
static enum Counters {
INPUT_WORDS;
}
}
WordCountReduce.java类
package com.dataeye.mr.reducer;
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
public class WordCountReduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += ((IntWritable) values.next()).get();
}
output.collect(key, new IntWritable(sum));
}
}
以下是 wc.job 配置文件
type=hadoopJava
job.class=com.dataeye.mr.WordCount
classpath=lib/*
force.output.overwrite=true
input.path=/tmp/azkaban/wordcountjavain
output.path=/tmp/azkaban/wordcountjavaout
注意/tmp/azkaban/wordcountjavain文件是必须先存在hdfs中的。
新增目录,把wc.job文件拷贝到该目录下,然后新增lib目录,把以上java代码打包成jar文件。最后压缩成zip文件,上传到azkaban上执行即可。
以上介绍了四类常用的azkaban任务的编写过程。其他任务类型可以参考Azkaban官网:Azkaban 3.0 Documentation
Azkaban任务流编写的更多相关文章
- springboot集成调用Azkaban
springboot集成调用Azkaban 一. 说明 1.Azkaban是由Linkedin公司推出的一个批量工作流任务调度器,主要用于在一个工作流内以一个特定的顺序运行一组工作和流程,它的配置是通 ...
- solr中通过SFTP访问文件建立索引
需求: 从oracle数据库中根据记录的文件名filename_html(多个文件以逗号隔开),文件路径path,备用文件名bakpath中获取 主机172.21.0.31上对应的html文件内容,并 ...
- 开始食用grpc(之一)
开始食用grpc(之一) 转载请注明出处:https://www.cnblogs.com/funnyzpc/p/9501353.html ``` 记一次和一锅们压马路,路过一咖啡厅(某巴克),随口 ...
- Jmeter 常见逻辑控制器详解
简介 Jmeter有很多逻辑控制器,可以控制请求的执行顺序和执行逻辑,本文就Jmeter常见的逻辑控制器做一个详细的描述,并通过示例让大家了解逻辑控制器的作用. 代码的逻辑分支通常有: 条件判断I ...
- Java多线程编程(6)--线程间通信(下)
因为本文的内容大部分是以生产者/消费者模式来进行讲解和举例的,所以在开始学习本文介绍的几种线程间的通信方式之前,我们先来熟悉一下生产者/消费者模式. 在实际的软件开发过程中,经常会碰到如下场景 ...
- 【OWASP TOP10】2021年常见web安全漏洞TOP10排行
[2021]常见web安全漏洞TOP10排行 应用程序安全风险 攻击者可以通过应用程序中许多的不同的路径方式去危害企业业务.每种路径方法都代表了一种风险,这些风险都值得关注. 什么是 OWASP TO ...
- 云南农职 - 互联网技术学院 - 美和易思大一SCME JAVA高级结业考试机试试题
目录 一.语言和环境 二.实现功能 1.文件复制功能(IO) 2.消息接受站建设 三.评分标准 四.实现代码 一.语言和环境 实现语言:Java. 开发工具:eclipse. 使用技术:IO流+网络编 ...
- day40-网络编程02
Java网络编程02 4.TCP网络通信编程 基本介绍 基于客户端--服务端的网络通信 底层使用的是TCP/IP协议 应用场景举例:客户端发送数据,服务端接收并显示控制台 基于Scoket的TCP编程 ...
- Azkaban各种类型的Job编写
一.概述 原生的 Azkaban 支持的plugin类型有以下这些: command:Linux shell命令行任务 gobblin:通用数据采集工具 hadoopJava:运行hadoopMR任务 ...
随机推荐
- 更改idea快捷键方式为eclipse风格
打开配置窗口 菜单栏中的File-settings 或者快捷键 ctrl+alt+s 设置keymap 在弹出的setting页面中左侧导航中选择Keymap: 在keymaps下拉列表中选择Ecli ...
- Codeforces Round #394 (Div. 2) B. Dasha and friends(暴力)
http://codeforces.com/contest/761/problem/B 题意: 有一个长度为l的环形跑道,跑道上有n个障碍,现在有2个人,给出他们每过多少米碰到障碍,判断他们跑的是不是 ...
- Github Clone to local files
cd to you local files address key the word: git clone -0 github https://github.com/xxxxxxxxx Done... ...
- [转]VS2015编译的程序在其他机器上缺少msvcp120.dll
http://www.lai18.com/content/1159618.html 1. 今天分享一个自己在开发过程中遇到的困难. 用VS2015开发了一个windows客户端(win32项目),在自 ...
- java线程中的interrupt,isInterrupt,interrupted方法
在java的线程Thread类中有三个方法,比较容易混淆,在这里解释一下 (1)interrupt:置线程的中断状态 (2)isInterrupt:线程是否中断 (3)interrupted:返回线程 ...
- JavaScript权威指南--WEB浏览器中的javascript
知识要点 1.客户端javascript window对象是所有客户端javascript特性和API的主要接入点.它表示web浏览器的一个窗口或窗体,并且可以用window表示来引用它.window ...
- JAVA synchronized关键字锁机制(中)
synchronized 锁机制简单的用法,高效的执行效率使成为解决线程安全的首选. 下面总结其特性以及使用技巧,加深对其理解. 特性: 1. Java语言的关键字,当它用来修饰一个方法或者一个代码块 ...
- 关于UDP很好的书籍和文章(整理、持续更新)
文章 告知你不为人知的 UDP:疑难杂症和使用(必看)
- notepad++支持自定义文件类型
场景描述: 使用notepad++编辑less.ejs文件,发现高亮和提示均无效,修改如此需要进行额外的设置: 解决方法: 以less为例, 1.设置 >语言格式设置 >语言里找到CSS, ...
- TCP/UDP协议
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...