Sizzle源码分析:二 词法分析
上一篇我们了解了Sizzle的整体流程,下面我开始一点点分析各个流程,我们进行查询的第一步就是词法分析tokenize,同样先了解下思路,如果是#div_test > span input[checked=true]会发生什么:
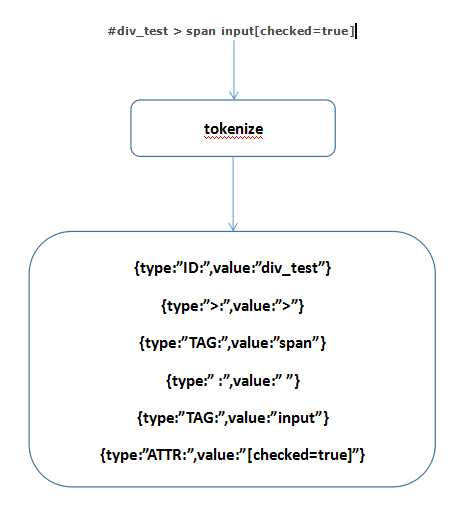
一个字符串的每个节点都被分析为以下数据结构:{type:'对应的Token类型',value:'匹配到的字符串', matches:'正则匹配到的一个结构'}
type包括有TAG, ID, CLASS, ATTR, CHILD, PSEUDO, NAME,表示每个字符串的类型
value是指字符串本身的值
match正则匹配到的一个结构
我们通过console打印出来的数据结构是下面:

首先说明一下下面代码中tokens数组和groups数组的关系,
比如#div_test span 那么我们分析后的结果是一个tokens数组,包含两个元素div_test和span [{type:"ID",value:"div_test"},{type:"TAG",value:"span"}]
如果是 #div_test span,#sp_test span,那么是两组tokens数组 一个包含div_test和span 一个包含sp_test和span 那这两组tokens就形成一个二维数组groups
[
[{type:"ID",value:"div_test"},{type:"TAG",value:"span"}]
[{type:"ID",value:"sp_test "},{type:"TAG",value:"span"}]
]
代码总体思路是
1. 如果有逗号,会过滤掉这个逗号,比如"div1,div2"第二次循环是selector的值是",div2"需要删掉前面的逗号,然后为groups新增元素
2. 如果是关系运算符 > + 空格 ~开头,直接压入数组
3. 然后开始分析 ID,TAG,CLASS,ATTR,CHILD,PSEUDO选择符,如果匹配到了相关选择符,再看看是否需要预处理,如果需要再进行预处理返回(只有部分选择符需要,后面详解),然后压入数组,删除相关选择符字符串
4. 继续下一个循环直到结束
//把字符串转换为token数组,格式为{type:'对应的Token类型',value:'匹配到的字符串', matches:'正则匹配到的一个结构'}
function tokenize(selector, parseOnly) {
var matched, match, tokens, type,
soFar, groups, preFilters,
cached = tokenCache[selector + " "];
if (cached) {//如果有缓存直接读取缓存
return parseOnly ? 0 : cached.slice(0);
}
soFar = selector;
groups = []; //这是最后要返回的二维数组
//预处理器,对token进行预处理
//预处理,有的选择器,比如属性选择器与伪类从选择器组分割出来,还要再细分
//属性选择器要切成属性名,属性值,操作符;伪类要切为类型与传参;
//子元素过滤伪类还要根据an+b的形式再划分
preFilters = Expr.preFilter;
while (soFar) {//对选择符逐个字符分析
//如果第一个字符是逗号,跳过逗号,并且压入第一个空token分组,groups是个二维数组,每个元素代表一个token数组,
if (!matched || (match = rcomma.exec(soFar))) {
if (match) {
soFar = soFar.slice(match[0].length) || soFar;
}
groups.push(tokens = []);
}
matched = false;
//如果开头的字符是关系选择符 > + 空格 ~ 将他直接压入tokens数组,并且删除selector相关部分
if ((match = rcombinators.exec(soFar))) {
matched = match.shift();
tokens.push({
value: matched,
// Cast descendant combinators to space
type: match[0].replace(rtrim, " ")
});
soFar = soFar.slice(matched.length);
}
/*然后开始分析ID,TAG,CLASS,ATTR,CHILD,PSEUDO
matchExpr 过滤正则
ATTR: /^\[[\x20\t\r\n\f]*((?:\\.|[\w-]|[^\x00-\xa0])+)[\x20\t\r\n\f]*(?:([*^$|!~]?=)[\x20\t\r\n\f]*(?:(['"])((?:\\.|[^\\])*?)\3|((?:\\.|[\w#-]|[^\x00-\xa0])+)|)|)[\x20\t\r\n\f]*\]/
CHILD: /^:(only|first|last|nth|nth-last)-(child|of-type)(?:\([\x20\t\r\n\f]*(even|odd|(([+-]|)(\d*)n|)[\x20\t\r\n\f]*(?:([+-]|)[\x20\t\r\n\f]*(\d+)|))[\x20\t\r\n\f]*\)|)/i
CLASS: /^\.((?:\\.|[\w-]|[^\x00-\xa0])+)/
ID: /^#((?:\\.|[\w-]|[^\x00-\xa0])+)/
PSEUDO: /^:((?:\\.|[\w-]|[^\x00-\xa0])+)(?:\(((['"])((?:\\.|[^\\])*?)\3|((?:\\.|[^\\()[\]]|\[[\x20\t\r\n\f]*((?:\\.|[\w-]|[^\x00-\xa0])+)[\x20\t\r\n\f]*(?:([*^$|!~]?=)[\x20\t\r\n\f]*(?:(['"])((?:\\.|[^\\])*?)\8|((?:\\.|[\w#-]|[^\x00-\xa0])+)|)|)[\x20\t\r\n\f]*\])*)|.*)\)|)/
TAG: /^((?:\\.|[\w*-]|[^\x00-\xa0])+)/
bool: /^(?:checked|selected|async|autofocus|autoplay|controls|defer|disabled|hidden|ismap|loop|multiple|open|readonly|required|scoped)$/i
needsContext: /^[\x20\t\r\n\f]*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\([\x20\t\r\n\f]*((?:-\d)?\d*)[\x20\t\r\n\f]*\)|)(?=[^-]|$)/i
*/
for (type in Expr.filter) {
if ((match = matchExpr[type].exec(soFar)) && (!preFilters[type] ||(match = preFilters[type](match)))) {
matched = match.shift();
tokens.push({
value : matched,
type : type,
matches: match
});
soFar = soFar.slice(matched.length);
}
}
if (!matched) {
break;
}
} // Return the length of the invalid excess
// if we're just parsing
// Otherwise, throw an error or return tokens
return parseOnly ?
soFar.length :
soFar ?
Sizzle.error(selector) :
// Cache the tokens
tokenCache(selector, groups).slice(0);
}
这里判断选择符的过程就是通过遍历Expr.filter来判断,我们来看看这个东西:
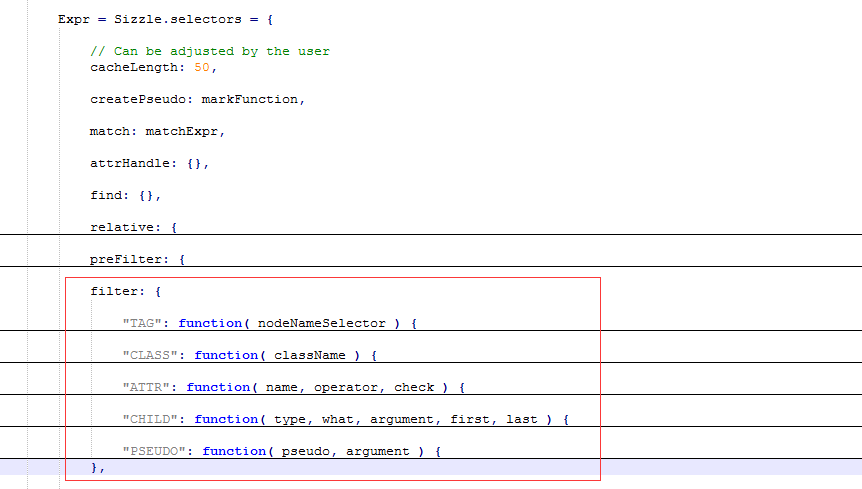
除了这5个,后面还根据浏览器兼容性新增了ID类型,为何要遍历这个对象呢,因为Sizzle里面把选择器字符串的类型就分了这么几种
ID:ID选择符
Class:类选择符
Tag:标签选择符
ATTR:属性标签
CHILD:包括(only|first|last|nth|nth-last)-(child|of-type)等等对子类的标签
PSEUDO:其他伪类选择符
对这些类型进行正则匹配之后,token数组就基本建立起来了,整个词法分析过程也就完成了。
顺便介绍下toSelector函数,他的过程刚好相反,就是把tokens字符串里面的值还原为字符串形式。
function toSelector( tokens ) {
var i = 0,
len = tokens.length,
selector = "";
for ( ; i < len; i++ ) {
selector += tokens[i].value;
}
return selector;
}
Sizzle源码分析:二 词法分析的更多相关文章
- Fresco 源码分析(二) Fresco客户端与服务端交互(1) 解决遗留的Q1问题
4.2 Fresco客户端与服务端的交互(一) 解决Q1问题 从这篇博客开始,我们开始讨论客户端与服务端是如何交互的,这个交互的入口,我们从Q1问题入手(博客按照这样的问题入手,是因为当时我也是从这里 ...
- Sizzle源码分析 (一)
Sizzle 源码分析 (一) 2.1 稳定 版本 Sizzle 选择器引擎博大精深,下面开始阅读它的源代码,并从中做出标记 .先从入口开始,之后慢慢切入 . 入口函数 Sizzle () 源码 19 ...
- 框架-springmvc源码分析(二)
框架-springmvc源码分析(二) 参考: http://www.cnblogs.com/leftthen/p/5207787.html http://www.cnblogs.com/leftth ...
- Tomcat源码分析二:先看看Tomcat的整体架构
Tomcat源码分析二:先看看Tomcat的整体架构 Tomcat架构图 我们先来看一张比较经典的Tomcat架构图: 从这张图中,我们可以看出Tomcat中含有Server.Service.Conn ...
- 十、Spring之BeanFactory源码分析(二)
Spring之BeanFactory源码分析(二) 前言 在前面我们简单的分析了BeanFactory的结构,ListableBeanFactory,HierarchicalBeanFactory,A ...
- Vue源码分析(二) : Vue实例挂载
Vue源码分析(二) : Vue实例挂载 author: @TiffanysBear 实例挂载主要是 $mount 方法的实现,在 src/platforms/web/entry-runtime-wi ...
- 多线程之美8一 AbstractQueuedSynchronizer源码分析<二>
目录 AQS的源码分析 该篇主要分析AQS的ConditionObject,是AQS的内部类,实现等待通知机制. 1.条件队列 条件队列与AQS中的同步队列有所不同,结构图如下: 两者区别: 1.链表 ...
- Sizzle源码分析:一 设计思路
一.前言 DOM选择器(Sizzle)是jQuery框架中非常重要的一部分,在H5还没有流行起来的时候,jQuery为我们提供了一个简洁,方便,高效的DOM操作模式,成为那个时代的经典.虽然现在Vue ...
- ABP源码分析二:ABP中配置的注册和初始化
一般来说,ASP.NET Web应用程序的第一个执行的方法是Global.asax下定义的Start方法.执行这个方法前HttpApplication 实例必须存在,也就是说其构造函数的执行必然是完成 ...
- spring源码分析(二)Aop
创建日期:2016.08.19 修改日期:2016.08.20-2016.08.21 交流QQ:992591601 参考资料:<spring源码深度解析>.<spring技术内幕&g ...
随机推荐
- 关于uuid与自增列的选择
关于uuid与自增列的选择 在db交流群里看到有人提问,说他的userName 登录名是唯一的,可以用其做主键嘛,如果用自增列,那又要多一列. 后面又说,如果要用主键ID,用uuid会不会好一些呢?作 ...
- Flask系列(八)flask-session组件
一.简介 flask-session是flask框架的session组件,由于原来flask内置session使用签名cookie保存,该组件则将支持session保存到多个地方,如: redis:保 ...
- Linux下编译安装MySQL5.6
[准备工作] 所有操作需要在root用户下 本机测试案例系统信息:centos7.3 安装路径:/usr/local/mysql [安装MySQL] 先安装如下依赖包: $ yum -y instal ...
- 利用HBase的快照功能来修改表名
hbase的快照功能常常被用来做数据的恢复的,但是由于项目的特殊需求需要改hbase表的表名.在官网上通过快照功能来修改hbase表名的用法: 下面展示用shell命令的和Java api两种方式: ...
- Deep Learning(2)
二.Deep Learning的基本思想和方法 实际生活中,人们为了解决一个问题,如对象的分类(对象可是是文档.图像等),首先必须做的事情是如何来表达一个对象,即必须抽取一些特征来表示一个对象,如文本 ...
- oracle连接数据库报错:ORA-01034: ORACLE not available(Oracle 不存在),ORA-27101: shared memory realm does not exist
花一天半的时间解决客户端连接服务端的oracle数据库,无法连接问题.ORA-01034: ORACLE not available(Oracle 不存在),ORA-27101: shared mem ...
- 文件下载—SSM框架文件下载
1.准备上传下载的api组件 <dependency> <groupId>commons-io</groupId> <artifactId>common ...
- LA 4287 有相图的强连通分量
大白书P322 , 一个有向图在添加至少的边使得整个图变成强连通图, 是计算整个图有a个点没有 入度, b 个点没有出度, 答案为 max(a,b) ; 至今不知所云.(求教) #include &l ...
- Python 中的多维字典
Python中的dict可以实现迅速查找.那么有没有像数组有二维数组一样,有二维的字典呢?比如我需要对两个关键词进行查找的时候.2D dict 可以通过 dict_2d = {'a': {'a': 1 ...
- Float类型出现舍入误差的原因(round 取位)
在练习时,输入如下代码: 结果不准确. 原因:https://blog.csdn.net/bitcarmanlee/article/details/51179572 浮点数一个普遍的问题就是在计算机的 ...