CDH安装kafka
- 摘要:前言其实cloudera已经做了这个事了,只是把kafka的包和cdh的parcel包分离了,只要我们把分离开的kafka的服务描述jar包和服务parcel包下载了,就可以实现完美集成了。具体实现的简要步骤可参照cloudera官网提供的文档:http://www.cloudera.com/content/www/en-us/documentation/kafka/latest/topics/kafka_installing.html,下面就是我根据这个文档的集成过程。ka
- 前言
其实cloudera已经做了这个事了,只是把kafka的包和cdh的parcel包分离了,只要我们把分离开的kafka的服务描述jar包和服务parcel包下载了,就可以实现完美集成了。
具体实现的简要步骤可参照cloudera官网提供的文档:http://www.cloudera.com/content/www/en-us/documentation/kafka/latest/topics/kafka_installing.html,
下面就是我根据这个文档的集成过程。
kafka相关包准备
csd包:http://archive.cloudera.com/csds/kafka/
parcel包: http://archive.cloudera.com/kafka/parcels/latest/ ( 根据自己的集群的系统版本下载 )
我用的是centos6.5 x64的系统,所以我下载的parcel包为KAFKA-0.8.2.0-1.kafka1.3.2.p0.56-el6.parcel与KAFKA-0.8.2.0-1.kafka1.3.2.p0.56-el6.parcel.sha1
集成实现
关闭集群,关闭cm服务( 假如不关闭cm服务,会出现在添加kafka服务时找不到相关的服务描述 )
将csd包放到cm安装节点下的 /opt/cloudera/csd目录下,如图 :

- 将parcel包放到cm安装节点下的 /opt/cloudera/parcel-repo目录下,如图:

- 启动cm服务,分配并激活percel包

- 添加kafka服务:

- 启动服务

1.下载 KAFKA 和SPARK2的 Parcel 包(可以从 TD CDH 包里拿到) 并放置到 Cloudera Manager 的 parcel 仓库目录下 (登录 CM 控制台 设置 Parcel配置)

2.对于前面重名的文件可以采取手动改名的形式, 例如 mainifest.json 可以备份以前的json 文件并改名,
3.重启 cloudera server 和 agent 服务
- /opt/cm-5.12.1/etc/init.d/cloudera-scm-server restart
- /opt/cm-5.12.1/etc/init.d/cloudera-scm-agent restart (agent服务器)
4.安装Kafka过程中如果启动失败 需要更改 默认的 Java Heap Size (默认50 M) 改成 512 即可

5.为客流运营平台单独安装 Kafka (需要先安装第二个Zookeeper集群 客源专用)
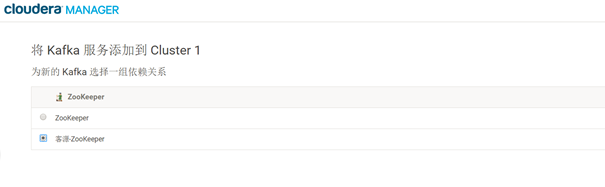
6.然后重新启动 Kafka 服务,并检查其状态 。
CDH安装kafka的更多相关文章
- CDH 安装 kafka
前言 其实cloudera已经做了这个事了,只是把kafka的包和cdh的parcel包分离了,只要我们把分离开的kafka的服务描述jar包和服务parcel包下载了,就可以实现完美集成了. 具体实 ...
- CentOS7安装CDH 第九章:CDH中安装Kafka
相关文章链接 CentOS7安装CDH 第一章:CentOS7系统安装 CentOS7安装CDH 第二章:CentOS7各个软件安装和启动 CentOS7安装CDH 第三章:CDH中的问题和解决方法 ...
- centos7安装kafka 转
CentOS7安装和使用kafka 环境准备 安装kafka之前我们需要做一些环境的准备 1.centOS7系统环境 2.jdk环境 3.可用的zookeeper集群服务 安装jdk ...
- PHP安装kafka插件
在工作中我们经常遇到需要给php安装插件,今天把php安装kafka的插件的步骤整理下,仅供大家参考 1:需要先安装librdkafka git clone https://github.com/ed ...
- 附录E 安装Kafka
E.1 安装Kafka E.1.1 下载Kafka Kafka是由LinkedIn设计的一个高吞吐量.分布式.基于发布订阅模式的消息系统,使用Scala编写,它以可水平扩展.可靠性.异步通信 ...
- Windows 安装Kafka
Windows 7 安装Apache kafka_2.11-0.9.0.1 下载所需文件 Zookeeper: http://www.apache.org/dyn/closer.cgi/zoo ...
- Redis安装,mongodb安装,hbase安装,cassandra安装,mysql安装,zookeeper安装,kafka安装,storm安装大数据软件安装部署百科全书
伟大的程序员版权所有,转载请注明:http://www.lenggirl.com/bigdata/server-sofeware-install.html 一.安装mongodb 官网下载包mongo ...
- cdh 安装记录
安装文件准备 CDH 下载地址:http://archive.cloudera.com/cdh5/parcels/latest/ 下载操作系统对应的版本: 1.CDH-5.3.0-1.cdh5.3.0 ...
- ambari安装集群下安装kafka manager
简介: 不想通过kafka shell来管理kafka已创建的topic信息,想通过管理页面来统一管理和查看kafka集群.所以选择了大部分人使用的kafka manager,我一共有一台主机mast ...
随机推荐
- 你的Android不好用,都是因为这几点原因
Android早已是全球最大.用户最多的移动操作系统,不过它离全球最好用还差得很远. 大家随手就能举出些曾经历过的糟心体验,如手机卡顿!电量不禁用!广告弹窗老是出现!不过很少有人会追根寻底的去问为何如 ...
- Python学习笔记020——数据库中的数据类型
1 数值类型 数值类型分为有符号signed和无符号unsigned两种. 1.1 整型 int (1)bigint 极大整型(8个字节) 范围 :-2**64 ~ 2**64 - 1 -922337 ...
- AspxPivotGrid和WebChartControl数据联动处理日志
AspxPivotGrid具有很好的表格样式体验,WebChartControl也是个很内容丰富的做图控件,我希望实现的功能是这样的, 处理题库统计分析图表,用户点AspxPivotGrid绑定知识点 ...
- unity 查看prefab层次
点那个箭头,可以展开:
- 【转】获取scrollTop兼容各浏览器的方法,以及body和documentElement是啥?
1.各浏览器下 scrollTop的差异 IE6/7/8: 对于没有doctype声明的页面里可以使用 document.body.scrollTop 来获取 scrollTop高度 : 对于有do ...
- malefile
什么是makefile?或许很多Winodws的程序员都不知道这个东西,因为那些Windows的IDE都为你做了这个工作,但我觉得要作一个好的和professional的程序员,makefile还是要 ...
- php 读取功能分割大文件实例详解
在php中,对于文件的读取时,最快捷的方式莫过于使用一些诸如file.file_get_contents之类的函数.但当所操作的文件是一个比较大的文件时,这些函数可能就显的力不从心, 下面将从一个需求 ...
- TCP数据流
1. 引言 如果按照分组数量计算,约有一半的TCP报文段包含成块数据(如FTP.电子邮件等),另一半则包含交互数据(如telnet和rlogin).如果按照字节计算,则成块数据与交互数据的比例约为90 ...
- GIS(一)——在js版搜索地图上加入Marker标记
因为我们做的是有关于旅游方面的项目,所以涉及到了地图功能.我接到的当中一个任务就是,在地图上显示指定的几个景点,并在地图上加上标记. 我们项目用的是搜狗地图.使用的是js版本号.大家有兴趣的话,能够參 ...
- SourceInsight-Symbol not found
使用SourceInsight查看源代码时,发现点击查看相关类型时,无法关联到其代码,出现 symbol not found, 然而明明在我的头文件有定义的 网上查了一下主要是因为新建工程导入文件后, ...