python编码问题 decode与encode
参考:
http://www.jb51.net/article/17560.htm
如果要在python2的py文件里面写中文,则必须要添加一行声明文件编码的注释,否则python2会默认使用ASCII编码。
# -*- coding:utf-8 -*-
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode('gb2312'),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode('gb2312'),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码
代码中字符串的默认编码与代码文件本身的编码一致。
如:s='中文'
如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。
如果字符串是这样定义:s=u'中文'
则该字符串的编码就被指定为unicode了,即python的内部编码,而与代码文件本身的编码无关。因此,对于这种情况做编码转换,只需要直接使用encode方法将其转换成指定编码即可。
如果一个字符串已经是unicode了,再进行解码则将出错,因此通常要对其编码方式是否为unicode进行判断:
isinstance(s, unicode) #用来判断是否为unicode
用非unicode编码形式的str来encode会报错
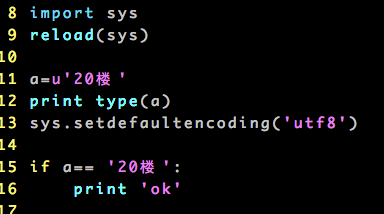
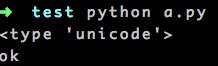
#coding=utf8a='20楼'
print type(a)
print sys.getdefaultencoding()
aa = a.decode('utf8')
if aa.find(u'楼'):
print 'ok'
else:
print 'no'
输出:
<type 'str'> ascii ok
参数ignore作用
比如,若要将某个String对象s从gbk内码转换为UTF-8,可以如下操作 s.decode('gbk').encode('utf-8′) 可是,在实际开发中,我发现,这种办法经常会出现异常: UnicodeDecodeError: ‘gbk' codec can't decode bytes in position 30664-30665: illegal multibyte sequence 这 是因为遇到了非法字符——尤其是在某些用C/C++编写的程序中,全角空格往往有多种不同的实现方式,比如\xa3\xa0,或者\xa4\x57,这些 字符,看起来都是全角空格,但它们并不是“合法”的全角空格(真正的全角空格是\xa1\xa1),因此在转码的过程中出现了异常。 这样的问题很让人头疼,因为只要字符串中出现了一个非法字符,整个字符串——有时候,就是整篇文章——就都无法转码。
解决办法: s.decode('gbk', ‘ignore').encode('utf-8′) 因为decode的函数原型是decode([encoding], [errors='strict']),可以用第二个参数控制错误处理的策略,默认的参数就是strict,代表遇到非法字符时抛出异常; 如果设置为ignore,则会忽略非法字符; 如果设置为replace,则会用?取代非法字符; 如果设置为xmlcharrefreplace,则使用XML的字符引用。
python文档
decode( [encoding[, errors]]) Decodes the string using the codec registered for encoding. encoding defaults to the default string encoding. errors may be given to set a different error handling scheme. The default is 'strict', meaning that encoding errors raise UnicodeError. Other possible values are 'ignore', 'replace' and any other name registered via codecs.register_error, see section 4.8.1.
python编码问题 decode与encode的更多相关文章
- Python—编码与解码(encode()和decode())
编码与解码 decode英文意思是解码,encode英文原意是编码. Python 里面的编码和解码也就是 unicode 和 str 这两种形式的相互转化.编码是 unicode -> str ...
- python之分析decode、encode、unicode编码转换
decode()方法使用注册编码的编解码器的字符串进行解码.它默认为默认的字符串编码.decode函数可以将一个普通字符串转换为unicode对象.decode是将普通字符串按照参数中的编码格式进行解 ...
- pyhton字符编码问题--decode和encode方法
1 decode和encode方法 字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成uni ...
- 【Python】关于decode和encode
#-*-coding:utf-8 import sys ''' *首先要搞清楚,字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码, 即先将 ...
- Python 编码错误的本质原因
转载自:https://foofish.net/python-unicode-error.html 不论你是有着多年经验的 Python 老司机还是刚入门 Python 不久的新贵,你一定遇到过Uni ...
- python编码encode和decode
计算机里面,编码方法有很多种,英文的一般用ascii,而中文有unicode,utf-8,gbk,utf-16等等. unicode是 utf-8,gbk,utf-16这些的父编码,这些子编码都能转换 ...
- Python编码介绍——encode和decode
在 python 源代码文件中,如果你有用到非ASCII字符,则需要在文件头部进行字符编码的声明,声明如下: # code: UTF-8 因为python 只检查 #.coding 和编码字符串,所以 ...
- python编码encode decode(解惑)
关于python 字符串编码一直没有搞清楚,今天总结了一下. Python 字符串类型 Python有两种字符串类型:str 与 unicode. 字符串实例 # -*- coding: utf-8 ...
- Python中解码decode()与编码encode()与错误处理UnicodeDecodeError: 'gbk' codec can't decode byte 0xab
编码方法encoding() 描述 encode() 方法以指定的编码格式编码字符串,默认编码为 'utf-8'.将字符串由string类型变成bytes类型. 对应的解码方法:bytes decod ...
随机推荐
- Qt5.3.2_CentOS6.4(x86)_代码文件编码
1.1.1.Qt5.3.2_MinGW 在Windows中安装时,默认的文件编码是 UTF8. 1.2.在 CentOS6.4中安装 qt-opensource-linux-x86-5.3.2.run ...
- 安装gcc4.8.5
安装gcc4.8.51. g++ --version, 4.4.7不支持c++112. 升级gcc-c++, 下载gcc https://gcc.gnu.org/ 官网,镜像下载地址https: ...
- php入门之数据类型
String(字符串), Integer(整型), Float(浮点型), Boolean(布尔型), Array(数组), Object(对象), NULL(空值),资源. 返回类型 getType ...
- JVM中对象的内存布局与访问定位
一.对象的内存布局 已主流的HotSpot虚拟机来说, 在HotSpot虚拟机中,对象在内存中存储的布局可以分为3块区域:对象头(Header).实例数据(Instance Data)和对齐填 ...
- C# 导出HTML为Excel
最近在项目中需要Excel导出,有多个Sheet页,每个Sheet页的内容比较多,且不是规整的表格,绑定值是个比较麻烦的事,便考虑直接将HTML转换为Excel文件进行导出. 一.使用JS方法将HTM ...
- 从零开始学习Vue(一)
因为最近有个项目的需求是,微信公众号+IOS/Android APP, 界面都很类似. 以往的做法是APP是调用JSON接口,后台只负责提供接口. 而H5,我以前都是用Jquery,用来写手机网站总是 ...
- Jpa实体类生成图解
Jpa实体类生成图解 创建连接 创建项目
- POJ 1008 简单模拟题
e.... 虽然这是一道灰常简单的模拟题.但是米做的时候没有读懂第二个日历的计时方法.然后捏.敲完之后华丽的WA了进一个点.坑点就在一年的最后一天你是该输出本年的.e ...但是我好想并没有..看di ...
- cas Cas20ProxyReceivingTicketValidationFilter
Cas20ProxyReceivingTicketValidationFilter 继承AbstractTicketValidationFilter,这里有几个模板方法.例如getTicketVal ...
- sgu187&&spoj7734
题解: splay翻转(只有翻转 sgu ac,spoj tle 代码: #pragma GCC optimize(2) #include<cstdio> #include<cstr ...