Hadoop2.0的基本构成总览
Hadoop1.x和Hadoop2.0构成图对比
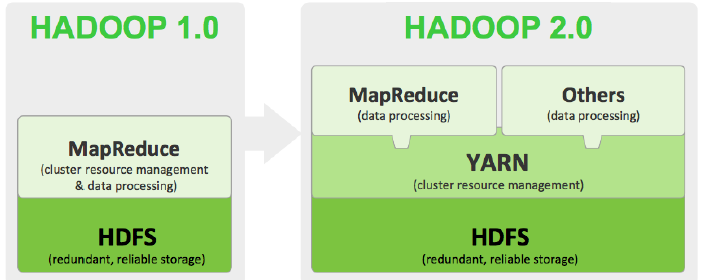
Hadoop1.x构成: HDFS、MapReduce(资源管理和任务调度);运行时环境为JobTracker和TaskTracker;
Hadoop2.0构成:HDFS、MapReduce/其他计算框架、YARN; 运行时环境为YARN
1、HDFS:HA、NameNode Federation
2、MapReduce/其他计算框架:运行在YARN之上的MapReduce通常称之为MapReduce2.0(MRv2)
3、YARN:资源管理系统(Yet Another Resource Negotiator),在其之上可以运行各种计算框架,如:MapReduce、Storm、Spark等;
HDFS2.0
解决HDFS1.0中单点故障和内存受限问题
解决单点故障: HDFS HA(High Available)
通过主备NameNode,当主NameNode发生故障时则切换到备NameNode;
解决内存受限问题: HDFS Federation
水平扩展,支持多个NameNode;
每个NameNode分管一部分目录;不同的NameNode可以分管不同的应用;
所有NameNode共享所有DataNode存储的资源;
HDFS2.0和HDFS1.0相比、仅是架构上发生了变化,使用方式不变,对HDFS使用者来说是透明的。比如说hdfs shell命令:
hadoop fs -ls /luogankun
hadoop fs -mkdir /luogankun/data
在HDFS1.0和HDFS2.0中用法是一致的。
YARN
Hadoop2.0新引入的资源管理系统
YARN核心思想:将MRv1中JobTracker的资源管理和任务调度分开,分别由ResourceManager和ApplicationMaster进程实现;
ResourceManager:负责整个集群的资源管理;整个集群只有一个;
ApplicationMaster:负责应用程序相关的事务,比如:任务调度、任务监控和任务容错;一个应用程序对应一个ApplicationMaster;
YARN引入的好处:使得多个计算框架可以运行在一个集群中,比如:MapReduce、Spark、Storm等;
MapReduce On YARN
运行在YARN之上的MapReduce称为MRv2;
将MapReduce作业直接运行在YARN上,而不是运行在由JobTracker和TaskTracker构建的MRv1之上;在Hadoop2.0中并不存在JobTracker和TaskTracker;
MRv2的模块基本功能:
1、YARN:负责资源管理和调度;
2、MRAppMaster:负责一个应用程序/作业的任务切分、任务调度、任务监控和容错;
3、Map/Reduce Task:任务驱动引擎,与MRv1一致;
每个应用程序/作业对应一个MRAppMaster,所以:
1、单个应用程序/作业运行失败,不会影响其他应用程序/作业;
2、负责应用程序/作业相关的事务,包括将从YARN分配得到的资源二次分配给内部的任务、任务切分、任务健康和容错等;

Hadoop2.0的基本构成总览的更多相关文章
- hadoop入门(3)——hadoop2.0理论基础:安装部署方法
一.hadoop2.0安装部署流程 1.自动安装部署:Ambari.Minos(小米).Cloudera Manager(收费) 2.使用RPM包安装部署:Apache ...
- Hadoop2.0(HDFS2)以及YARN设计的亮点
YARN总体上仍然是Master/Slave结构,在整个资源管理框架中,ResourceManager为Master,NodeManager为Slave,ResouceManager负责对各个Node ...
- 实战:ADFS3.0单点登录系列-总览
本系列将以一个实际项目为背景,介绍如何使用ADFS3.0实现SSO.其中包括SharePoint,MVC,Exchange等应用程序的SSO集成. 整个系列将会由如下几个部分构成: 实战:ADFS3. ...
- hadoop2.0 和1.0的区别
1. Hadoop 1.0中的资源管理方案Hadoop 1.0指的是版本为Apache Hadoop 0.20.x.1.x或者CDH3系列的Hadoop,内核主要由HDFS和MapReduce两个系统 ...
- Hadoop2.0重启脚本
Hadoop2.0重启脚本 方便重启带ha的集群,写了这个脚本 #/bin/bash sh /opt/zookeeper-3.4.5-cdh4.4.0/bin/zkServer.sh restart ...
- ganglia监控hadoop2.0配置方法
ganglia监控hadoop2.0配置方法前提:hadoop2.0集群已安装ganglia监控工具第一步:Hadoop用户登录集群每一个节点,修改文件:vi /opt/hadoop-2.0.0-cd ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- hadoop-2.0.0-cdh4.2.1源码编译总结
经过一个星期多的努力,这两个包的编译工作总算告一段落. 首先看一下这一篇文章: 在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/arch ...
- hadoop2.0 eclipse 源码编译
在eclipse下编译hadoop2.0源码 http://www.cnblogs.com/meibenjin/archive/2013/07/05/3172889.html hadoop cdh4编 ...
随机推荐
- ZOJ 17届校赛 How Many Nines
If we represent a date in the format YYYY-MM-DD (for example, 2017-04-09), do you know how many 9s w ...
- opencv-python教程学习系列3-视频操作
前言 opencv-python教程学习系列记录学习python-opencv过程的点滴,本文主要介绍视频的获取和保存,坚持学习,共同进步. 系列教程参照OpenCV-Python中文教程: 系统环境 ...
- 洛谷 1020:导弹拦截(DP,LIS)
题目描述 某国为了防御敌国的导弹袭击,发展出一种导弹拦截系统.但是这种导弹拦截系统有一个缺陷:虽然它的第一发炮弹能够到达任意的高度,但是以后每一发炮弹都不能高于前一发的高度.某天,雷达捕捉到敌国的导弹 ...
- CTF中图片隐藏文件分离方法
CTF中图片隐藏文件分离方法 0x01 分析 这里我们以图片为载体,给了这样的一样图片:2.jpg 首先我们需要对图片进行分析,这里我们需要用到kali里面的一个工具 binwalk ,想要了解这 ...
- 2017年最新cocoapods安装教程(解决淘宝镜像源无效以及其他源下载慢问题)
首先,先来说一下一般的方法吧,就是把之前的淘宝源替换成一个可用的的源: 使用终端查看当前的源 gem sources -l gem sources -r https://rubygems.org/ # ...
- dbt- 数据构建工具
dbt(数据构建工具)是一个命令行工具,只需编写select语句即可转换仓库中的数据. dbt处理将这些select语句转换为表和视图.DBT帮助做T的ELT(提取,加载和转换) 的过程-它不提取或加 ...
- android 学习过程中登陆失效的个人理解
今天在学习的过程中,要做登陆失效的功能,所以就找了些资料.好好看了一下.研究了一番,慢慢的做出来了! 比方:你在一个手机端登陆了账号,在另外的一个手机端也登陆了账号,此时.前一个手机端的账号会提示登陆 ...
- 用户态监控网络接口up、down事件
网上搜索(https://blog.csdn.net/qq123386926/article/details/50695725)可以直接使用netlink现成的接口实现: #include <s ...
- JVM监控
jconsole 说明: 首先JConsole这个是JDK里面自带的工具 在JAVA_HOME/bin目录下,今天主要测试远程监控JVM 第一步:设置好需要远程机器的Tomcat 修改Tomcat下 ...
- 单变量微积分笔记21——三角替换2(tan和sec)
tan和sec常用公式 我一直认为三角函数中只有sin和cos是友好的,其它都是变态.现在不得不接触一些变态: 这些变态的相关等式: 等式的证明 这个稍有点麻烦,先要做一些前置工作. 三角替换 示例1 ...