TOP100summit:【分享实录】链家网大数据平台体系构建历程
本篇文章内容来自2016年TOP100summit 链家网大数据部资深研发架构师李小龙的案例分享。
编辑:Cynthia
李小龙:链家网大数据部资深研发架构师,负责大数据工具平台化相关的工作。专注于数据仓库、任务流调度、元数据管理、自助报表等领域。之前在百度从事了四年的数据仓库和工具平台的研发工作。
导读:链家网大数据部门负责收集加工公司各产品线的数据,并为链家集团各业务部门提供数据支撑。本文分享链家网大数据部成立后,在发展变革中遇到的一些问题和挑战,架构团队是如何构建一站式的数据平台来解决获取数据的效率问题,如何构建多层次系统来组建大数据架构体系。重点介绍团队早期作为数据报表支持者,向当下数据平台方转变的这一历程,通过对数据处理流程的梳理,构建一体化的数据接入/计算/展示的开放平台,提升数据运转效率,快速满足集团内数据需求。
一、背景简介
链家网自2014年成立后,全面推进020战略,打造线上线下房产服务闭环,公司业务迅速增长,覆盖全国28个地区,门店数量超过8000家。随着链家集团积累数据的不断增多,在2015年专门成立了大数据部,推进集团内各公司数据资产的整合,以数据驱动公司业务的发展。
链家将房地产交易大数据分为物的数据、人的数据、行为数据三大块来进行研究。
● 物的数据主要是构建了全国的楼盘字典,拥有专业的摄影测量团队实地勘测,收录了7000万套房屋的详细信息,包括小区周边、人文素养等等。
● 人的数据,包括买家、业主、经纪人三方,目前在全国有13万经纪人,对经纪人的背景、从业年限、资历、专业能力、历史行为有详细记录,给客户更加精准的参考。目前链家网服务的买家和卖家超过两千多万,对用户进行画像,然后推荐更加合适的房屋。
● 行为数据,包括线上行为和多样的线下行为,譬如线上的浏览日志,线下的看房行程等。
通过分析这些数据,找到与业务的结合点,目前大数据在链家网具体的应用场景有房屋估价、智能推荐、房客图谱、BI报表。
二、大数据从0到1的架构落地
大数据部成立以后,借鉴业界成熟的数据仓库方案,设计的早期架构图如图1所示:

图1 数据仓库早期架构
在这个阶段我们主要做了三件事:
● 搭建hadoop集群,初期只有10多台机器,随着业务的发展,集群规模也在不断增长。
● 采用HIVE构建数据仓库,数据仓库里的数据来源于业务方的mysql数据库和log日志。
● 定制化报表开发,按照业务方的需求,case by case做一些BI报表展示,满足业务方对数据的分析。
这个架构简单清晰,这样做有三个好处:
● 使用开源的组件,方便扩展和运维;
● 采用业界成熟的数据仓库方案,数据仓库分层模型设计;
● 有利于技术人员培养,技术团队在成长初期技术选型需要考虑市场上人员情况,所以选择了使用范围广的技术。
具体讲讲HIVE数据仓库的模型,该模型一共分为5层。
● 最下面是STG层,用来存储源数据,保持与数据源完全一致;
● 第二层是ODS层,会进行数据清理等工作,譬如不同业务系统的城市编码不一致,有的001代表北京,有的110代表北京,在ODS层进行维度编码的统一处理。还有不同业务系统的金钱单位不一致,有的是元、有的是分,在此统一采用分为单位,保留两位小数;
● 最上面是报表层,根据业务需求进行加工处理,产出报表数据。至于数据仓库遵循的范式结构,目前没有严格一致地规范,星型模型和雪花模型都有采用。
早期的大数据架构落地后,支撑了将近一年时间,从2015年初到2016年初,取得了不错的效果。
● 收集汇总了集团内各个分公司、各条产品线的数据,便于交叉分析。通过对比分析数据,能帮助业务系统更好的发展。
● 支撑集团内大部分报表需求,帮助运营人员改进决策,数据驱动。 巧妇难为无米之炊,当数据仓库积累了大量历史数据,数据挖掘的同学就能进行深度分析。
三、大数据平台化体系的建设
为什么要做平台化?
主要原因还是随着公司业务的快速发展,数据需求迅速增多,早期的大数据架构遇到一些新挑战。
● 数据需求快速增长:链家业务增长到全国多个城市,各个城市的报表需求很多,而且由于各个地方的政策不太一样,报表需求也有所差异,此外还有大量的临时统计数据需求。为了能快速响应需求,我们提出平台化,通过提供各种数据处理和探索工具,让用户自助高效地获取一些数据。
● 数据治理亟需规范:各条产品线的数据都进入仓库以后,由于需求很急迫,一些建模规范未能有效执行,导致仓库里数据冗余繁杂,wiki更新维护不及时,难以清晰掌握数据仓库里数据整体概况。指标定义不清晰,一些数据需求人员按照自己的理解制定指标含义,结果上线后,发现不同的人对指标理解不一致,导致返工。
● 数据安全迫在眉睫:对数据的申请需要进行集中的审批管理,对数据的使用需要进行持续的追踪备案,防止数据泄露。
为了解决存在的这些问题,我们提出了新的平台化架构图。平台化架构数据流图如图2所示:
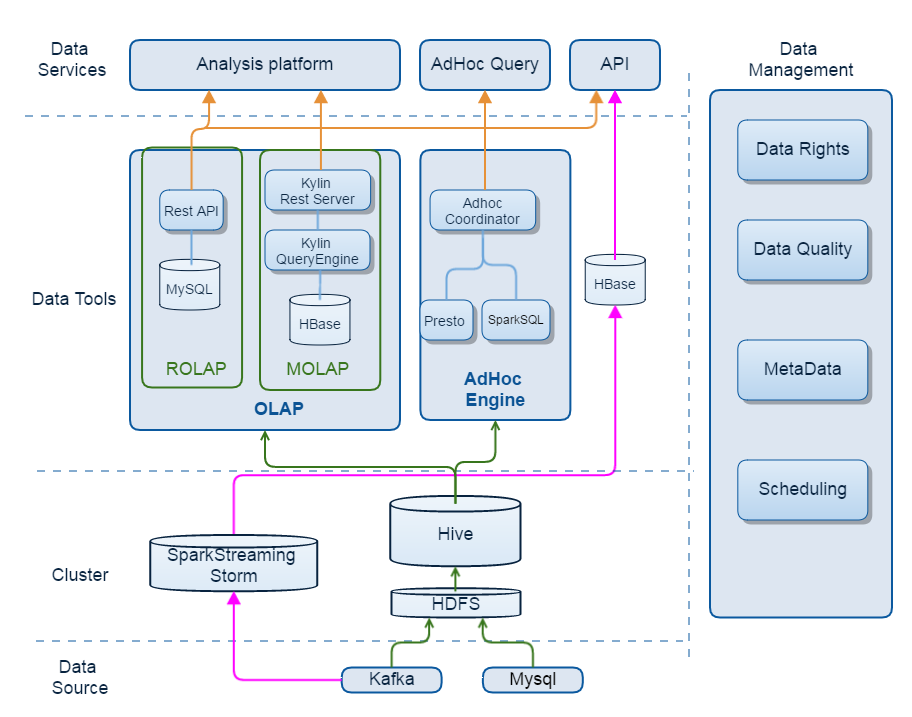
图2 平台化架构数据流图
对比新老架构图可以看出,首先是多了红色的实时数据流部分,日志log采用flume对接Kafka消息队列,然后使用SparkStreaming/Storm进行日志的分析处理,处理后的结果写入到Hbase供API服务使用。
另外,在OLAP部分,引入了Kylin作为MOLAP处理引擎,会定期将Hive里面的星型模型数据处理后写入Hbase,然后Kylin对外提供数据分析服务,提供亚秒级的查询速度。
图中右边是数据治理相关组件,有数据权限、数据质量、元数据等。在新的平台化架构图中,我们将大数据工程平台分为三层,由上到下分别是应用层、工具层、基础层,如图3所示:

图3 大数据工程平台
3.1 应用层
应用层,主要面向数据开发人员和数据分析师,重点解决三类问题:
● BI报表产出速度如何加快,缩短业务方从提出数据需求到报表产出的时间周期。
● 数据治理,对公司的核心数据指标进行统一定义,对元数据进行管理,集中数据的审批流程。
● 数据流转集中管控,数据在各个系统间的流转统一走元数据管理平台,能很方便排查定位问题。
为了加快BI报表产出,我们开发了地动仪自助报表,在数据源已经就绪的情况下,目标是5分钟完成一个通用报表的配置,得到类似 excel表格、柱状图这种图表效果,目前已经支持 mysql、presto 、kylin等各种数据源。另外,如果需要定制化的Dashboard报表,自助报表也支持复用一些图表组件。
元数据管理系统
元数据对公司的所有数据信息进行管理维护,通过数据地图,可以看到公司数据仓库里的所有数据以及数据信息的变更情况,方便用户进行搜索查询。指标图书馆对指标进行详细的描述定义,而且可以对每个指标关联的维度进行管理,维度表以及维度取值的描述。另外,基于元数据我们还可以做数据血缘关系,方便追踪数据的上下游关系,能够快速定位排查问题。
元数据管理系统上线后,取得了以下三个成果:
● 所有表的创建修改都经过元数据系统,可以实时清晰掌握仓库里的数据情况。
● 成立了公司级别的数据委员会,统一制定公司的核心指标,各个部门可以自定义二级指标。
● 数据的接入和流出都通过元数据系统集中管控,所有的日志接入、mysql接入通过元数据来配置,数据申请也是走的元数据,方便集中管理运维。
3.2 工具层
工具层定位于通用工具组件的开发,为上层应用提供能力支撑,同时解决用户在使用大数据计算中遇到的实际困难。譬如ETL作业任务很多、追踪排查问题比较麻烦、数据修复时间长、Hue hive查询速度比较慢、一个sql需要等待几分钟。
图4是实际工作中一个典型的数据任务链路图,抽取了作业链路中的一部分。
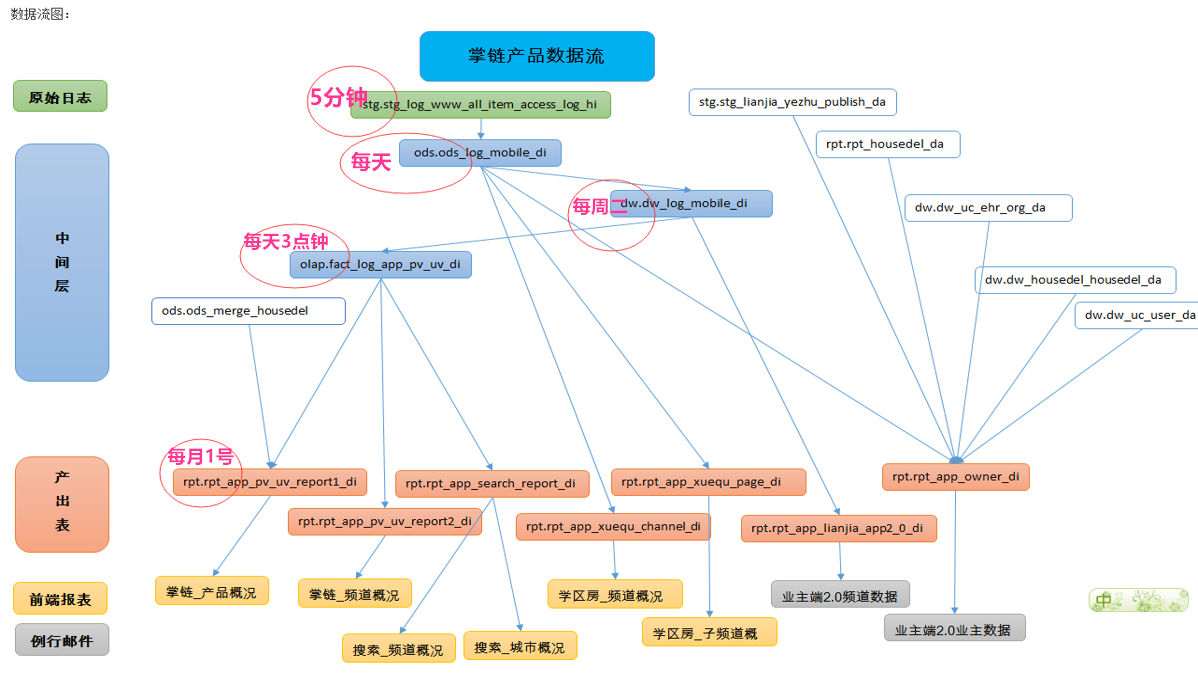
图4 数据任务链路图
从图中我们可以看到以下信息:
● 任务链路特别长,可能有6层之多;
● 任务种类多,既有mysql导入任务,也有hive-sql加工任务,还有发送邮件的任务;
● 依赖类型比较复杂,有小时级别依赖分钟任务,也有日周月季互相依赖的任务。
对于这种复杂的数据链路,之前我们采用oozie+python+shell解决,任务量有5000多个,维护困难,且遇到数据修复问题,难以迅速定位。为了解决这些问题,我们参考了oozie、airflow等开源软件,自主研发了新的任务调度系统。
在新的任务调度系统上,用户可以自助运维,对任务进行上线或者重跑,而且可以实时看到任务的运行日志。以前可能要登陆到集群机器上上查看日志,非常麻烦。
调度系统上线后,取得了非常好的效果:
● 任务配置简单,在图形上简单的拖曳即可操作。
● 提供常用的ETL组件,零编码。举个例子,以前发送数据邮件,需要自己写脚本,目前在我们界面只需配置收件人和数据表即可。
● 一键修复追溯,将排查问题修复数据的时间由一人天缩减到10分钟。
● 集群的资源总是紧张的,目前我们正在做的智能调度、错峰运行,保证高优先级任务优先运行。
Adhoc即席查询,之前我们使用的hue,速度比较慢。通过调研市面上的各种快速查询工具,我们采用了Presto和Spark SQL双引擎,架构图如图5所示:
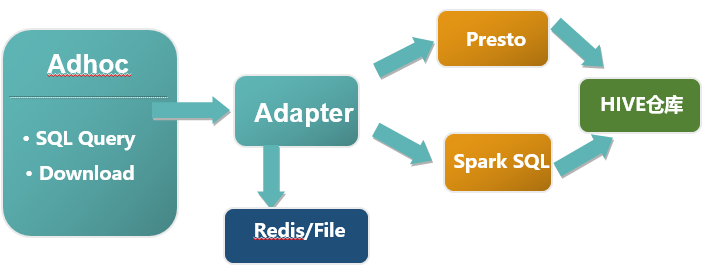
图5 双引擎架构图
3.3 基础层
基础层偏重于集群底层能力的建设和完善。遇到的问题集中在两个方面:
● 任务量剧增,目前每天有一万多JOB,造成集群资源相当紧张,排队严重。
● 集群的数据安全需要规划,而且由于多个部门都在使用集群,之前未划分账号和队列,大家共同使用。
针对这些问题,我们在基础层做了一些改进。
在集群性能优化方面,通过划分单独的账号队列,资源预留,保证核心作业的执行,同时与应用层的权限管理打通,对不同的目录按照用户归属限制不同的权限。随着集群数据的膨胀,不少冷数据无人管理,我们在梳理后,将冷数据迁移到AWS S3存储。
四、案例启示
● 传统企业或者初创团队如何快速落地大数据,首先要采用成熟的业界方案,大的互联网公司的做法可以直接借鉴,稳定的开源软件直接使用;其次要深入梳理公司业务,找到契合点,譬如链家网的房屋估价、个性化搜索、交叉报表分析。
● 面对公司业务的迅速增长,平台化思维是解决问题的一个法宝。首先要通过梳理用户的流程和使用习惯,将这些服务自动化,让用户能自助排查一些问题;其次平台化开发的产品,先得实实在在解决用户痛点问题,自己愿意使用,然后才能推广给其他人使用。
● 平台化的产品需要梳理清楚流程,制定规范。先通过梳理调研公司的现状,然后规范流程,当然梳理的过程比较痛苦,需要很多人配合;制定了标准以后,需要保证标准的权威性和执行力,可以成立公司级别的数据治理委员会,发布核心指标,保证流程的推广执行。
更多TOP100案例信息及日程请前往[官网]查阅。包含产品、团队、架构、运维、大数据、人工智能等多个技术专场,4天时间集中分享2017年最值得学习的100个研发案例实践。本平台共送出10张开幕式单天免费体验票,数量有限,先到先得。免费体验票申请入口
TOP100summit:【分享实录】链家网大数据平台体系构建历程的更多相关文章
- 海豚调度5月Meetup:6个月重构大数据平台,帮你避开调度升级改造/集群迁移踩过的坑
当今许多企业都有着技术架构的DataOps程度不够.二次开发成本高.迁移成本高.集群部署混乱等情况,团队在技术选型之后发现并不适合自己的需求,但是迁移成本和难度又比较大,甚至前团队还留下了不少坑,企业 ...
- 携程实时大数据平台演进:1/3 Storm应用已迁到JStorm
携程大数据平台负责人张翼分享携程的实时大数据平台的迭代,按照时间线介绍采用的技术以及踩过的坑.携程最初基于稳定和成熟度选择了Storm+Kafka,解决了数据共享.资源控制.监控告警.依赖管理等问题之 ...
- 大数据平台迁移实践 | Apache DolphinScheduler 在当贝大数据环境中的应用
大家下午好,我是来自当贝网络科技大数据平台的基础开发工程师 王昱翔,感谢社区的邀请来参与这次分享,关于 Apache DolphinScheduler 在当贝网络科技大数据环境中的应用. 本次演讲主要 ...
- 分享系列--面试JAVA架构师--链家网
本月7日去了一趟链家网面试,虽然没有面上,但仍有不少收获,在此做个简单的分享,当然了主要是分享给自己,让大家见笑了.因为这次是第一次面试JAVA网站架构师相关的职位,还是有些心虚的,毕竟之前大部分时间 ...
- Scrapy实战篇(一)之爬取链家网成交房源数据(上)
今天,我们就以链家网南京地区为例,来学习爬取链家网的成交房源数据. 这里推荐使用火狐浏览器,并且安装firebug和firepath两款插件,你会发现,这两款插件会给我们后续的数据提取带来很大的方便. ...
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- python链家网高并发异步爬虫and异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- Pyspider爬虫简单框架——链家网
pyspider 目录 pyspider简单介绍 pyspider的使用 实战 pyspider简单介绍 一个国人编写的强大的网络爬虫系统并带有强大的WebUI.采用Python语言编写,分布式架构, ...
随机推荐
- teamviwer安装提示 Verification of your Teamviewer version failed!.
打开cmd输入 regsvr32 c:\windows\SysWOW64\wintrust.dll 就可以了.
- pycahrm使用docstrings来指定变量类型、返回值类型、函数参数类型
py里面不需要显示声明类型,这和java c这些静态语言不同,虽然python这样做少了一些代码和写代码的困难度,但还是非常多的弊端的,运行速度 代码安全, 这些都是语言本身带来的本的弊端,这些没办法 ...
- Mybatis数据库连接报错:对实体 "characterEncoding" 的引用必须以 ';' 分隔符结尾
Mybatis数据库连接报错:对实体 "characterEncoding" 的引用必须以 ';' 分隔符结尾 ============================== 蕃薯耀 ...
- Git 单机版
Git 是一个分布式的开源版本控制系统,也就是说,每台机器都可以充当控制中心,我从本机拉取代码,再提交代码到本机,不需要依赖网络,各自开发各自的 如何创建 git 仓库: [root@localhos ...
- Nginx 默认虚拟主机
一台服务器可以配置多个网站,每个网站都称为一个虚拟主机,默认的虚拟主机可以通过 default_server 来指定:: [root@localhost ~]$ cat /usr/local/ngin ...
- 使用 urllib 处理 Cookies 信息
如何获取 Cookies : import urllib.request import http.cookiejar cookies = http.cookiejar.CookieJar() # 先声 ...
- php pear包打包方法
一)首先下载工具onion 浏览器打开,服务器上wget测试无法正常下载 地址:https://raw.github.com/c9s/Onion/master/onion 二)在临时目录下,建立相关目 ...
- web基础----->jersey整合jetty开发restful应用(一)
这里介绍一个jersey与jetty整合开发restful应用的知识.将过去和羁绊全部丢弃,不要吝惜那为了梦想流下的泪水. jersey与jetty的整合 一.创建一个maven项目,pom.xml的 ...
- Entity Framework6的在线下载安装
Entity Framework6的在线下载安装 Entity Framework 简单介绍: 看名字就知道肯定是关于数据模型的…… Entity Framework:微软官方提供的ORM()工具,O ...
- C语言工具:LCC-Win32+v3.0
LCC-Win32+v3.0(带汉化).rar 小巧精悍的工具 安装步骤: 1.先安装 LCC-Win32V3.0.exe 假如安装目录为:C:\lcc 2.再安装 LCC-Win32V3.0汉化补 ...