[NLP] TextCNN模型原理和实现
1. 模型原理
1.1 论文
Yoon Kim在论文(2014 EMNLP) Convolutional Neural Networks for Sentence Classification提出TextCNN。
将卷积神经网络CNN应用到文本分类任务,利用多个不同size的kernel来提取句子中的关键信息(类似于多窗口大小的ngram),从而能够更好地捕捉局部相关性。
1.2 网络结构
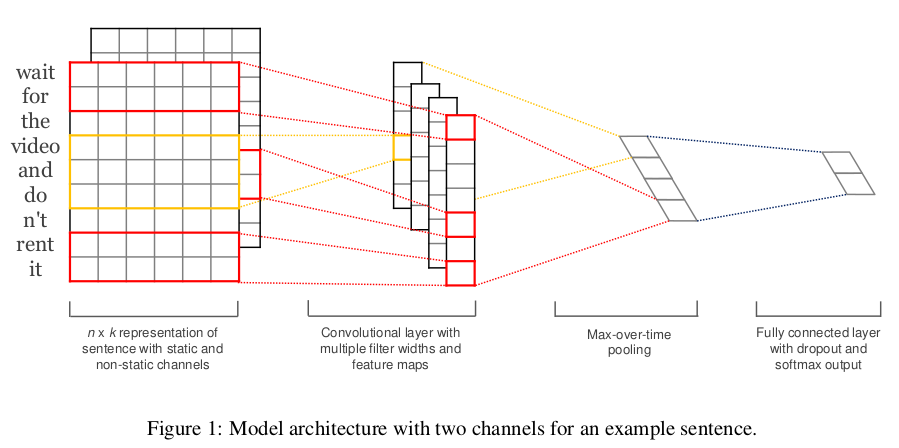
TextCNN的详细过程原理图如下:
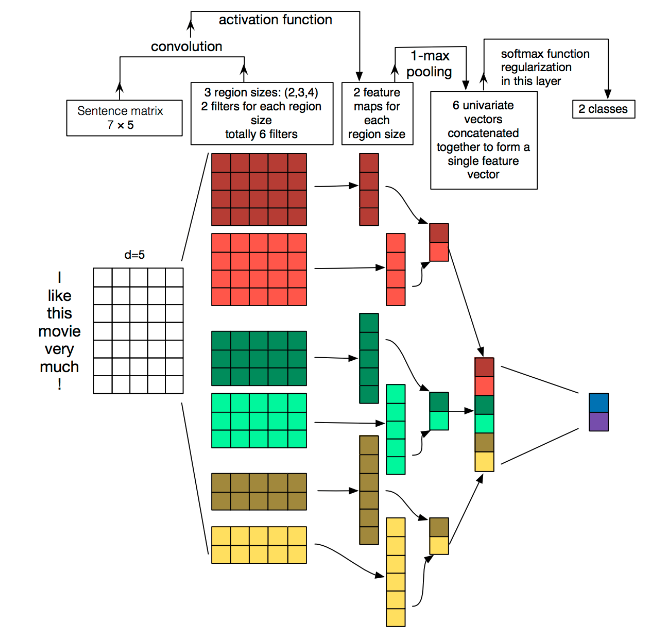
TextCNN详细过程:
- Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
- Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
- MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
- FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
通道(Channels):
- 图像中可以利用 (R, G, B) 作为不同channel;
- 文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):
- 图像是二维数据;
- 文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。
Pooling层:
利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
比如在情感分析场景,举个例子:
“我觉得这个地方景色还不错,但是人也实在太多了”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
2. 实现
基于Keras深度学习框架的实现代码如下:
import logging from keras import Input
from keras.layers import Conv1D, MaxPool1D, Dense, Flatten, concatenate, Embedding
from keras.models import Model
from keras.utils import plot_model def textcnn(max_sequence_length, max_token_num, embedding_dim, output_dim, model_img_path=None, embedding_matrix=None):
""" TextCNN: 1. embedding layers, 2.convolution layer, 3.max-pooling, 4.softmax layer. """
x_input = Input(shape=(max_sequence_length,))
logging.info("x_input.shape: %s" % str(x_input.shape)) # (?, 60) if embedding_matrix is None:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length)(x_input)
else:
x_emb = Embedding(input_dim=max_token_num, output_dim=embedding_dim, input_length=max_sequence_length,
weights=[embedding_matrix], trainable=True)(x_input)
logging.info("x_emb.shape: %s" % str(x_emb.shape)) # (?, 60, 300) pool_output = []
kernel_sizes = [2, 3, 4]
for kernel_size in kernel_sizes:
c = Conv1D(filters=2, kernel_size=kernel_size, strides=1)(x_emb)
p = MaxPool1D(pool_size=int(c.shape[1]))(c)
pool_output.append(p)
logging.info("kernel_size: %s \t c.shape: %s \t p.shape: %s" % (kernel_size, str(c.shape), str(p.shape)))
pool_output = concatenate([p for p in pool_output])
logging.info("pool_output.shape: %s" % str(pool_output.shape)) # (?, 1, 6) x_flatten = Flatten()(pool_output) # (?, 6)
y = Dense(output_dim, activation='softmax')(x_flatten) # (?, 2)
logging.info("y.shape: %s \n" % str(y.shape)) model = Model([x_input], outputs=[y])
if model_img_path:
plot_model(model, to_file=model_img_path, show_shapes=True, show_layer_names=False)
model.summary()
return model
特征:这里用的是词向量表示方式
- 数据量较大:可以直接随机初始化embeddings,然后基于语料通过训练模型网络来对embeddings进行更新和学习。
- 数据量较小:可以利用外部语料来预训练(pre-train)词向量,然后输入到Embedding层,用预训练的词向量矩阵初始化embeddings。(通过设置weights=[embedding_matrix])。
- 静态(static)方式:训练过程中不再更新embeddings。实质上属于迁移学习,特别是在目标领域数据量比较小的情况下,采用静态的词向量效果也不错。(通过设置trainable=False)
- 非静态(non-static)方式:在训练过程中对embeddings进行更新和微调(fine tune),能加速收敛。(通过设置trainable=True)
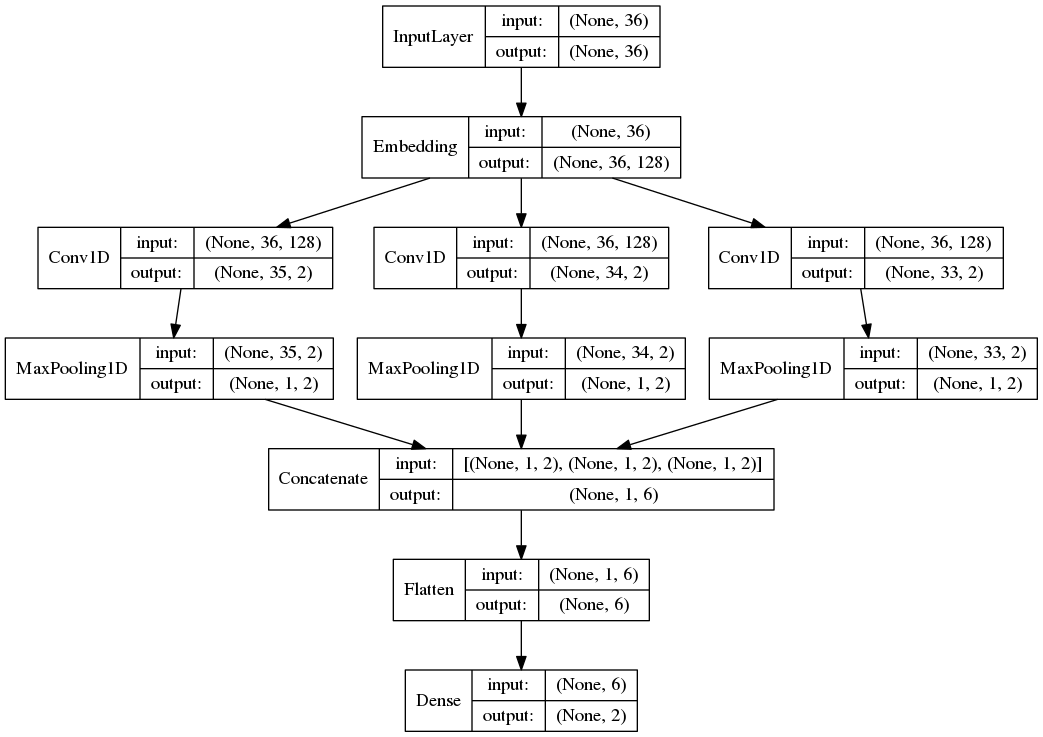
plot_model()画出的TextCNN模型结构图如下:
参考:https://zhuanlan.zhihu.com/p/25928551
[NLP] TextCNN模型原理和实现的更多相关文章
- 基于Text-CNN模型的中文文本分类实战 流川枫 发表于AI星球订阅
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 基于Text-CNN模型的中文文本分类实战
Text-CNN 1.文本分类 转眼学生生涯就结束了,在家待就业期间正好有一段空闲期,可以对曾经感兴趣的一些知识点进行总结. 本文介绍NLP中文本分类任务中核心流程进行了系统的介绍,文末给出一个基于T ...
- 史上最详尽的NLP预处理模型汇总
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 转自 | 磐创AI(公众号ID:xunixs) 作者 | AI小昕 编者按:近年来,自然语言处理(NL ...
- word2vec模型原理与实现
word2vec是Google在2013年开源的一款将词表征为实数值向量的高效工具. gensim包提供了word2vec的python接口. word2vec采用了CBOW(Continuous B ...
- 【转】Select模型原理
Select模型原理利用select函数,判断套接字上是否存在数据,或者能否向一个套接字写入数据.目的是防止应用程序在套接字处于锁定模式时,调用recv(或send)从没有数据的套接字上接收数据,被迫 ...
- Select模型原理
Select模型原理 利用select函数,推断套接字上是否存在数据,或者是否能向一个套接字写入数据.目的是防止应用程序在套接字处于锁定模式时,调用recv(或send)从没有数据的套接字上接收数据, ...
- asp.net请求响应模型原理随记回顾
asp.net请求响应模型原理随记回顾: 根据一崇敬的讲师总结:(会存在些错误,大家可以做参考) 1.-当在浏览器输入url后,客户端会将请求根据http协议封装成为http请求报文.并通过主sock ...
- Actor模型原理
1.Actor模型 在使用Java进行并发编程时需要特别的关注锁和内存原子性等一系列线程问题,而Actor模型内部的状态由它自己维护即它内部数据只能由它自己修改(通过消息传递来进行状态修改),所以使用 ...
- 文本分类实战(二)—— textCNN 模型
1 大纲概述 文本分类这个系列将会有十篇左右,包括基于word2vec预训练的文本分类,与及基于最新的预训练模型(ELMo,BERT等)的文本分类.总共有以下系列: word2vec预训练词向量 te ...
随机推荐
- 【Mac常用shell】
1. 杀掉占用某端口的进程: lsof -i:9000 -> 确认PID kill PID 2. 环境变量: 直接用{PATH}:路径 的办法,经常不好用,我的解决办法: vi ~/.bas ...
- 《剑指offer》第二十一题(调整数组顺序使奇数位于偶数前面)
// 面试题21:调整数组顺序使奇数位于偶数前面 // 题目:输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有 // 奇数位于数组的前半部分,所有偶数位于数组的后半部分. #inclu ...
- Servlet之javax.servlet包
链接 : http://blog.sina.com.cn/s/blog_5d4214c70102wnf1.html
- Oracle数据库system用户忘记了密码怎么办
1.在运行里面输入cmd调出dos窗口,然后在dos窗口中输入sqlplus /nolog 如:D:\oracle\ora92\bin>sqlplus /nolog 2.输入连接命令 如:SQL ...
- LeetCode--119--杨辉三角II
问题描述: 给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行. 在杨辉三角中,每个数是它左上方和右上方的数的和. 示例: 输入: 3 输出: [1,3,3,1] 进阶: 你可以优化你 ...
- Educational Codeforces Round 57题解
A.Find Divisible 沙比题 显然l和2*l可以直接满足条件. 代码 #include<iostream> #include<cctype> #include< ...
- Working routine CodeForces - 706E (链表)
大意: 给定矩阵, q个操作, 每次选两个子矩阵交换, 最后输出交换后的矩阵 双向十字链表模拟就行了 const int N = 1500; int n, m, q; struct _ { int v ...
- poj 1182 (带权并查集)
食物链 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 71361 Accepted: 21131 Description ...
- UVA-10692 Huge Mods
题目大意:计算a1^a2^a3^a4......^an模m的值. 题目解析:幂取模运算的结果一定有周期.一旦找到周期就可把高次幂转化为低次幂.有降幂公式 (a^x)%m=(a^(x%phi(m)+ph ...
- python 小练习12
给你一个整数数列a1,a2,a3,...,an,请你修改(不能删除,只能修改)最少的数字,使得数列严格单调递增. 数列存储在列表L中,你可以直接使用L,L的长度小于100000. 注意:必须保证修改后 ...