iOS 抓取 HTML ,CSS XPath 解析数据
以前我们获取数据的方式都是使用 AFN 来 Get JSON 数据,比如 点我查看 JSON 数据.http://news-at.zhihu.com/api/4/news/latest
但例如下面的百度贴吧,和豆瓣读书等网站..并不提供我们获取数据的 API
百度贴吧:

豆瓣读书:

这时我们可以解析他们的 HTML 来获取我们想要的数据.
工具准备
这时我们需要2个工具,Firefox 和FireBug.
你可以在 http://www.firefox.com.cn/download/下载 FireFox 浏览器,然后在其右上角菜单的附加组件管理器中下载 FireBug 插件.
FireBug 有很强大的 JavaScript 调试功能,还能实时编辑 HTML CSS,是前端同学喜爱的一个工具.
下载安装好以后,点击右上角的 Bug(虫子)图标来使用 FireBug 调试当前网页.
如果你不了解 XPath ,可以学习 w3school 的教程.

Ono 开源库
Ono 是一个 Github 上的开源项目,它能方便我们解析 XML,HTML 标签,并且支持 CSS XPath 搜索特定节点.
你可能没听过这个库,但其作者你肯定知道. Mattt Thompson,它是 AFN 的作者,还是博客 NSHipster 的作者.
Swift 版本类似的开源库 Ji
Java 或 Android 可以使用 Jsoup
开始
准备工作都 Ok 了..我们开始编码.新建一个空白工程,注意,如果要在 Info.plist 中添加两行 App Transport Security Settings,和 Allow Arbitrary Loads YES, 来允许 HTTP 传输。

然后使用 CocoaPods 添加第三方库 pod 'Ono'.
这里,要解析的 HTMl 数据就用我的博客了
再创建一个 Post 类继承自 NSObject,代表每一篇文章 ,修改 .h 文件如下
#import
@class ONOXMLElement;
@interface Post : NSObject
@property (copy,nonatomic) NSString *title; //文章标题
@property (copy,nonatomic) NSString *postDate; //文章发表时间
@property (copy,nonatomic) NSString *postUrl; //文章正文内容的 Url
+(NSArray*)getNewPosts; //获取所有文章
+(instancetype)postWithHtmlStr:(ONOXMLElement*)element; //用 HTMl 数据创建 Post 类
@end
在.m 文件中导入 Ono,并添加一个常量 Url.
#import
static NSString *const kUrlStr=@"http://BigPi.me";
然后我们可以用 AFN 等下载该 Url 的 HTML数据,再使用 XPath 获取代表每一篇文章的 XPath,
先打开 FireFox 和 FireBug ,点击下面的图标

在适当移动鼠标,点击选择网页上的一篇文章,
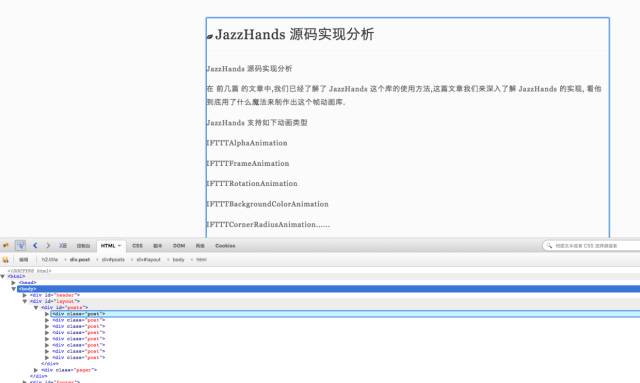
这时我们可以看到,下面 FireBug 的 HTMl 树展开了,我们可以发现,每一个
标签都包含一篇文章的数据.
我们右键
,复制其 XPath

复制出来的结果 //*[@id="posts"],这个节点下面的每一个子节点都代表一篇文章,我们现在来使用这个 XPath 获取所有的 HTML 数据.在 Post.m 添加如下方法:
+(NSArray*)getNewPosts{
NSMutableArray *array=[NSMutableArray array];
NSData *data= [NSData dataWithContentsOfURL:[NSURL URLWithString:kUrlStr]]; //下载网页数据
NSError *error;
ONOXMLDocument *doc=[ONOXMLDocument HTMLDocumentWithData:data error:&error];
ONOXMLElement *postsParentElement= [doc firstChildWithXPath:@"//*[@id='posts']"]; //寻找该 XPath 代表的 HTML 节点,
//遍历其子节点,
[postsParentElement.children enumerateObjectsUsingBlock:^(ONOXMLElement *element, NSUInteger idx, BOOL * _Nonnull stop) {
NSLog(@"%@",element);
}];
return array;
}
并在ViewController.m 中调用这个方法:
@implementation ViewController
- (void)viewDidLoad {
[super viewDidLoad];
[Post getNewPosts];
}
@end
运行后查看 Console, 我们已经可以获取到每篇文章的 HTMl 了,然后我们再来解析每篇文章的具体数据.
切换到 FireBug,展开其中一篇文章的节点

我们可以看到<h2 class="title">节点下的
<a href="/post/jazzhands/jazzhands-yuan-ma-shi-xian-fen-xi">
<i class="fa fa-leaf"></i>
JazzHands 源码实现分析</a>
标签中,有文章的具体Url, 和文章标题,
<div class="info">节点下的,
<span class="date">
<i class="fa fa-clock-o"></i>
2016-03-04 21:39</span>
标签有文章发布的时间,此时我们可以右键点击节点,复制文章标题,发布时间等节点的 XPath,
但这里我们使用相对的 XPath.
每篇文章的 HTML 结构如下:
文章标题 Url等内容
所以我们的
文章 Url XPath : “h2/a”
文章标题 XPath : a 标签的 href 属性值
文章发布时间 XPath : “div[2]/span[1]”
接下来我们来解析每一篇文章的详细数据
在 Post.m 中添加方法:
+(instancetype)postWithHtmlStr:(ONOXMLElement*)element{
Post *p=[Post new];
ONOXMLElement *titleElement= [element firstChildWithXPath:@"h2/a"]; // 根据 XPath 获取含有文章标题的 a 标签
p.postUrl= [titleElement valueForAttribute:@"href"]; //获取 a 标签的 href 属性
p.title= [titleElement stringValue];
ONOXMLElement *dateElement= [element firstChildWithXPath:@"div[2]/span[1]"]; //根据 XPath 获取文章发布时间 span 标签
p.postDate= [dateElement stringValue];
return p;
}
然后修改 +(NSArray*)getNewPosts方法:如下
...
[postsParentElement.children enumerateObjectsUsingBlock:^(ONOXMLElement *element, NSUInteger idx, BOOL * _Nonnull stop) {
//NSLog(@"%@",element);
Post *post=[Post postWithHtmlStr:element];
if(post){
[array addObject:post];
}
}];
...
最后因为我们我们获取到的 HTMl 的文章 Url 是相对 Url, 类似
/post/jazzhands/jazzhands-yuan-ma-shi-xian-fen-xi
所以我们在 Setter 方法中拼接域名 , http://BigPi.me
-(void)setPostUrl:(NSString *)postUrl{
_postUrl=[kUrlStr stringByAppendingString:postUrl];
}
我们在下图位置打断点查看结果:

运行起来,结果如下:

至此我们已经能使用 FireBug + Ono + XPath 来解析 HTML 数据
我就使用这个办法获取我们学校教务管理系统 HTML,制作了一个统计成绩,计算绩点的 App.
补充
FireBug 是一个很强大前端调试工具.
还可以使用 正则表达式 来解析 HTML 数据.不过从 StackOverflow 讨论 来看 ,并推荐使用正则来解析 HTML 数据.
RayWonderLich 有一篇比较老的教程 ,使用类似的技术解析 HTML
最最后,很重要的一点,HTML 数据可能经常会变动,尤其那个网页还不是我们自己能管理的网页,所以 XPath 随时可能解析失败,
如果你一定要使用 XPath 来解析 HTML 数据,可以在服务端进行这个操作,然后修改成 API 的形式,让手机端像以前一样 GET JSON 数据.
同时,服务端还可以设置异常处理,缓存等策略.
本文 Demo 可以在 https://github.com/iShawnWang/BlogDemo/tree/master/ParseHTMLDemo中获取
iOS 抓取 HTML ,CSS XPath 解析数据的更多相关文章
- Hawk: 20分钟无编程抓取大众点评17万数据
1. 主角出场:Hawk介绍 Hawk是沙漠之鹰开发的一款数据抓取和清洗工具,目前已经在Github开源.详细介绍可参考:http://www.cnblogs.com/buptzym/p/545419 ...
- ios 抓取真机的网络包
一直被如何从真机上抓包所困扰!今天偶然看到了最简单有效的方法!分享一下: 原地址链接 http://blog.csdn.net/phunxm/article/details/38590561 通过 R ...
- IOS抓取与反抓取
目录 IOS抓取基础知识 IOS抓取方式 iOS破解 模拟器 黑雷苹果模拟器 介绍 局限 改机软件 常用改机软件 检测 可更改属性 注入与Hook(越狱下实现作弊) 注入方式 Hook方式 重打包(非 ...
- SQL Server定时自动抓取耗时SQL并归档数据发邮件脚本分享
SQL Server定时自动抓取耗时SQL并归档数据发邮件脚本分享 第一步建库和建表 USE [master] GO CREATE DATABASE [MonitorElapsedHighSQL] G ...
- SQL Server定时自动抓取耗时SQL并归档数据脚本分享
原文:SQL Server定时自动抓取耗时SQL并归档数据脚本分享 SQL Server定时自动抓取耗时SQL并归档数据脚本分享 第一步建库 USE [master] GO CREATE DATABA ...
- 测试开发Python培训:抓取新浪微博评论提取目标数据-技术篇
测试开发Python培训:抓取新浪微博评论提取目标数据-技术篇 在前面我分享了几个新浪微博的自动化脚本的实现,下面我们继续实现新的需求,功能需求如下: 1,登陆微博 2,抓取评论页内容3,用正则表 ...
- 爬虫系列二(数据清洗--->xpath解析数据)
一 xpath介绍 XPath 是一门在 XML 文档中查找信息的语言.XPath 用于在 XML 文档中通过元素和属性进行导航. XPath 使用路径表达式在 XML 文档中进行导航 XPath 包 ...
- xpath解析数据
xpath解析数据 """ xpath 也是一种用于解析xml文档数据的方式 xml path w3c xpath搜索用法 在 XPath 中,有七种类型的节点:元素.属 ...
- 利用wireshark抓取远程linux上的数据包
原文发表在我的博客主页,转载请注明出处. 前言 因为出差,前后准备总结了一周多,所以博客有所搁置.出差真是累人的活计,不过确实可以学习到很多东西,跟着老板学习做人,学习交流的技巧.入正题~ wires ...
随机推荐
- [转]xshell实现端口转发
原文: https://www.cnblogs.com/linxizhifeng/p/8657795.html https://blog.csdn.net/qq_34039315/article/de ...
- OpenStack云桌面系列【2】—OpenStack和Spice
OpenStack和VNC Openstack默认安装的訪问控制台基于VNC的.我们从Horizon进入主机实例的控制台,就是noVNC.我在之前的一篇文章里专门对noVNC也做过測试(http:// ...
- 配置windows失败,不能进入系统
曾经,遇到过<配置windows失败,还原更新,请勿关机>,可多次尝试都无效. 包括: 1. 安全模式(进不了系统) 2. 带命令的安全模式 3. 最后一次正确的配置 4 ...
- tomcat7部署多个web应用不同编码,端口
1个tomcat部署多个web应用可以设置不同编码,端口,server.xml配置如下: <?xml version='1.0' encoding='utf-8'?><Server ...
- 微信小程序 - 3d轮播图组件(基础)
<!-- 目前仅支持data数据源来自banner,请看测试案例 ################ 以上三种形式轮播: 1. basic 2. 3d 3. book basic即普通轮播 3d即 ...
- Struts2(九)OGNL标签一与Struts2标签
一.什么是OGNL Object Graph Navigation Language对象图导航语言. 是Struts2默认的表达式语言,开源,功能更强大.和EL表达式有点相似 存取对象的属性,调用对 ...
- JavaScript正则式练习
使用正则式匹配第一个数字和最后一个数字,使用环视 str2 = 09051 : Fast Food Restaurants - Concession Stands/Snack Bars Delicat ...
- Stingray验证机制
Filter 系统中的验证使用的是Filter库来完成,利用Filter配置几个属性和参数就实现了表单验证,简化了工作.基本原理很简单,在onload之后按照属性查找元素,然后绑定相应的change/ ...
- 远程IPC种植木马
要实现代码例如以下: ///////////////////////////////////////////////////////////////////////////////////// typ ...
- 算法笔记_222:串中取3个不重复字母(Java)
目录 1 问题描述 2 解决方案 1 问题描述 从标准输入读入一个由字母构成的串(不大于30个字符). 从该串中取出3个不重复的字符,求所有的取法. 取出的字符,要求按字母升序排列成一个串. 不同 ...