TF-IDF理解及其Java实现
TF-IDF
前言
前段时间,又具体看了自己以前整理的TF-IDF,这里把它发布在博客上,知识就是需要不断的重复的,否则就感觉生疏了。
TF-IDF理解
TF-IDF(term frequency–inverse document frequency)是一种用于资讯检索与资讯探勘的常用加权技术, TFIDF的主要思想是:如果某个词或短语在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。TFIDF实际上是:TF * IDF,TF词频(Term Frequency),IDF反文档频率(Inverse Document Frequency)。TF表示词条在文档d中出现的频率。IDF的主要思想是:如果包含词条t的文档越少,也就是n越小,IDF越大,则说明词条t具有很好的类别区分能力。如果某一类文档C中包含词条t的文档数为m,而其它类包含t的文档总数为k,显然所有包含t的文档数n=m + k,当m大的时候,n也大,按照IDF公式得到的IDF的值会小,就说明该词条t类别区分能力不强。但是实际上,如果一个词条在一个类的文档中频繁出现,则说明该词条能够很好代表这个类的文本的特征,这样的词条应该给它们赋予较高的权重,并选来作为该类文本的特征词以区别与其它类文档。这就是IDF的不足之处.
TF公式:
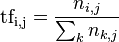
以上式子中  是该词在文件
是该词在文件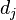 中的出现次数,而分母则是在文件中所有字词的出现次数之和。
中的出现次数,而分母则是在文件中所有字词的出现次数之和。
IDF公式:
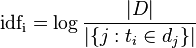
- |D|:语料库中的文件总数
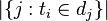 :包含词语
:包含词语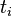 的文件数目(即
的文件数目(即 的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用
的文件数目)如果该词语不在语料库中,就会导致被除数为零,因此一般情况下使用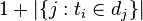
然后

TF-IDF案例
案例:假如一篇文件的总词语数是100个,而词语“母牛”出现了3次,那么“母牛”一词在该文件中的词频就是3/100=0.03。一个计算文件频率 (DF) 的方法是测定有多少份文件出现过“母牛”一词,然后除以文件集里包含的文件总数。所以,如果“母牛”一词在1,000份文件出现过,而文件总数是10,000,000份的话,其逆向文件频率就是 lg(10,000,000 / 1,000)=4。最后的TF-IDF的分数为0.03 * 4=0.12。
TF-IDF实现(Java)
这里采用了外部插件IKAnalyzer-2012.jar,用其进行分词,插件和测试文件可以从这里下载:点击
具体代码如下:
package tfidf; import java.io.*;
import java.util.*; import org.wltea.analyzer.lucene.IKAnalyzer; public class ReadFiles { /**
* @param args
*/
private static ArrayList<String> FileList = new ArrayList<String>(); // the list of file //get list of file for the directory, including sub-directory of it
public static List<String> readDirs(String filepath) throws FileNotFoundException, IOException
{
try
{
File file = new File(filepath);
if(!file.isDirectory())
{
System.out.println("输入的[]");
System.out.println("filepath:" + file.getAbsolutePath());
}
else
{
String[] flist = file.list();
for(int i = 0; i < flist.length; i++)
{
File newfile = new File(filepath + "\\" + flist[i]);
if(!newfile.isDirectory())
{
FileList.add(newfile.getAbsolutePath());
}
else if(newfile.isDirectory()) //if file is a directory, call ReadDirs
{
readDirs(filepath + "\\" + flist[i]);
}
}
}
}catch(FileNotFoundException e)
{
System.out.println(e.getMessage());
}
return FileList;
} //read file
public static String readFile(String file) throws FileNotFoundException, IOException
{
StringBuffer strSb = new StringBuffer(); //String is constant, StringBuffer can be changed.
InputStreamReader inStrR = new InputStreamReader(new FileInputStream(file), "gbk"); //byte streams to character streams
BufferedReader br = new BufferedReader(inStrR);
String line = br.readLine();
while(line != null){
strSb.append(line).append("\r\n");
line = br.readLine();
} return strSb.toString();
} //word segmentation
public static ArrayList<String> cutWords(String file) throws IOException{ ArrayList<String> words = new ArrayList<String>();
String text = ReadFiles.readFile(file);
IKAnalyzer analyzer = new IKAnalyzer();
words = analyzer.split(text); return words;
} //term frequency in a file, times for each word
public static HashMap<String, Integer> normalTF(ArrayList<String> cutwords){
HashMap<String, Integer> resTF = new HashMap<String, Integer>(); for(String word : cutwords){
if(resTF.get(word) == null){
resTF.put(word, 1);
System.out.println(word);
}
else{
resTF.put(word, resTF.get(word) + 1);
System.out.println(word.toString());
}
}
return resTF;
} //term frequency in a file, frequency of each word
public static HashMap<String, Float> tf(ArrayList<String> cutwords){
HashMap<String, Float> resTF = new HashMap<String, Float>(); int wordLen = cutwords.size();
HashMap<String, Integer> intTF = ReadFiles.normalTF(cutwords); Iterator iter = intTF.entrySet().iterator(); //iterator for that get from TF
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
resTF.put(entry.getKey().toString(), Float.parseFloat(entry.getValue().toString()) / wordLen);
System.out.println(entry.getKey().toString() + " = "+ Float.parseFloat(entry.getValue().toString()) / wordLen);
}
return resTF;
} //tf times for file
public static HashMap<String, HashMap<String, Integer>> normalTFAllFiles(String dirc) throws IOException{
HashMap<String, HashMap<String, Integer>> allNormalTF = new HashMap<String, HashMap<String,Integer>>(); List<String> filelist = ReadFiles.readDirs(dirc);
for(String file : filelist){
HashMap<String, Integer> dict = new HashMap<String, Integer>();
ArrayList<String> cutwords = ReadFiles.cutWords(file); //get cut word for one file dict = ReadFiles.normalTF(cutwords);
allNormalTF.put(file, dict);
}
return allNormalTF;
} //tf for all file
public static HashMap<String,HashMap<String, Float>> tfAllFiles(String dirc) throws IOException{
HashMap<String, HashMap<String, Float>> allTF = new HashMap<String, HashMap<String, Float>>();
List<String> filelist = ReadFiles.readDirs(dirc); for(String file : filelist){
HashMap<String, Float> dict = new HashMap<String, Float>();
ArrayList<String> cutwords = ReadFiles.cutWords(file); //get cut words for one file dict = ReadFiles.tf(cutwords);
allTF.put(file, dict);
}
return allTF;
}
public static HashMap<String, Float> idf(HashMap<String,HashMap<String, Float>> all_tf){
HashMap<String, Float> resIdf = new HashMap<String, Float>();
HashMap<String, Integer> dict = new HashMap<String, Integer>();
int docNum = FileList.size(); for(int i = 0; i < docNum; i++){
HashMap<String, Float> temp = all_tf.get(FileList.get(i));
Iterator iter = temp.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
String word = entry.getKey().toString();
if(dict.get(word) == null){
dict.put(word, 1);
}else {
dict.put(word, dict.get(word) + 1);
}
}
}
System.out.println("IDF for every word is:");
Iterator iter_dict = dict.entrySet().iterator();
while(iter_dict.hasNext()){
Map.Entry entry = (Map.Entry)iter_dict.next();
float value = (float)Math.log(docNum / Float.parseFloat(entry.getValue().toString()));
resIdf.put(entry.getKey().toString(), value);
System.out.println(entry.getKey().toString() + " = " + value);
}
return resIdf;
}
public static void tf_idf(HashMap<String,HashMap<String, Float>> all_tf,HashMap<String, Float> idfs){
HashMap<String, HashMap<String, Float>> resTfIdf = new HashMap<String, HashMap<String, Float>>(); int docNum = FileList.size();
for(int i = 0; i < docNum; i++){
String filepath = FileList.get(i);
HashMap<String, Float> tfidf = new HashMap<String, Float>();
HashMap<String, Float> temp = all_tf.get(filepath);
Iterator iter = temp.entrySet().iterator();
while(iter.hasNext()){
Map.Entry entry = (Map.Entry)iter.next();
String word = entry.getKey().toString();
Float value = (float)Float.parseFloat(entry.getValue().toString()) * idfs.get(word);
tfidf.put(word, value);
}
resTfIdf.put(filepath, tfidf);
}
System.out.println("TF-IDF for Every file is :");
DisTfIdf(resTfIdf);
}
public static void DisTfIdf(HashMap<String, HashMap<String, Float>> tfidf){
Iterator iter1 = tfidf.entrySet().iterator();
while(iter1.hasNext()){
Map.Entry entrys = (Map.Entry)iter1.next();
System.out.println("FileName: " + entrys.getKey().toString());
System.out.print("{");
HashMap<String, Float> temp = (HashMap<String, Float>) entrys.getValue();
Iterator iter2 = temp.entrySet().iterator();
while(iter2.hasNext()){
Map.Entry entry = (Map.Entry)iter2.next();
System.out.print(entry.getKey().toString() + " = " + entry.getValue().toString() + ", ");
}
System.out.println("}");
} }
public static void main(String[] args) throws IOException {
// TODO Auto-generated method stub
String file = "D:/testfiles"; HashMap<String,HashMap<String, Float>> all_tf = tfAllFiles(file);
System.out.println();
HashMap<String, Float> idfs = idf(all_tf);
System.out.println();
tf_idf(all_tf, idfs); } }
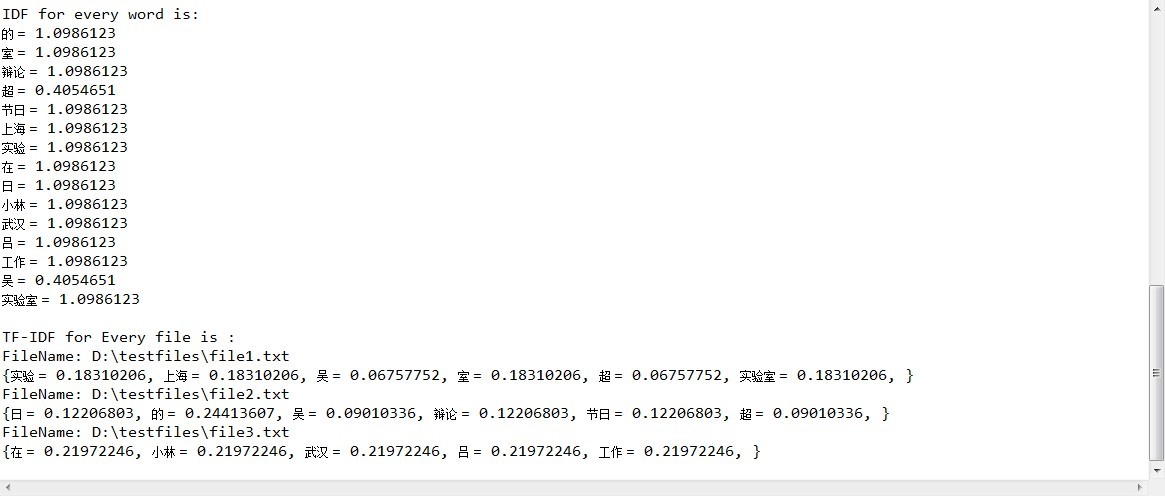
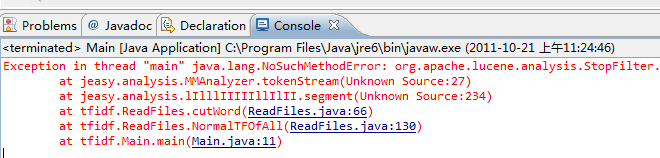
结果如下图:
常见问题
没有加入lucene jar包
lucene包和je包版本不适合
TF-IDF理解及其Java实现的更多相关文章
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- tf idf公式及sklearn中TfidfVectorizer
在文本挖掘预处理之向量化与Hash Trick中我们讲到在文本挖掘的预处理中,向量化之后一般都伴随着TF-IDF的处理,那么什么是TF-IDF,为什么一般我们要加这一步预处理呢?这里就对TF-IDF的 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- 基于TF/IDF的聚类算法原理
一.TF/IDF描述单个term与特定document的相关性TF(Term Frequency): 表示一个term与某个document的相关性. 公式为这个term在document中出 ...
- 使用solr的函数查询,并获取tf*idf值
1. 使用函数df(field,keyword) 和idf(field,keyword). http://118.85.207.11:11100/solr/mobile/select?q={!func ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
随机推荐
- Python-Flask实现电影系统管理后台
代码地址如下:http://www.demodashi.com/demo/14850.html 项目描述 该项目实现电影系统的后台接口,包括用户,电影,场次,订单,评论,优惠券,推荐,收藏等多个模块, ...
- windows下Oracle Tuxedo编译应用前需要配置的相关环境变量
rem (c) BEA Systems, Inc. All Rights Reserved. rem Copyright (c) BEA Systems, Inc. rem All Rights Re ...
- onActivityResult 传递数据
onActivityResult 传递数据 http://www.cnblogs.com/sipher/articles/2435078.html 如下图所示.当菜单项变多时,出现了垂直的滚动条,选项 ...
- ThinkPHP学习(三)
我们已经将数据保存到了后台数据库,那接下来我们肯定要将数据显示出来看看了. 先建立一个要显示数据的模板formlist.html: <!DOCTYPE HTML PUBLIC "-// ...
- LAMP环境搭建实现网站动静分离[转]
目录: 1.环境概述 2.动静分离拓扑图 3.各服务器功能规划 4.各服务器基础环境配置 5.httpd安装配置 6.php安装配置及启用opcache加速功能 7.mysql安装配置 8.wordp ...
- nginx配置文件结构,语法,配置命令解释
摘要: nginx的配置文件类似于一门优雅的编程语言,弄懂了它的规范就可以自定义配置文件了,这个很重要~ 1,结构分析 nginx配置文件中主要包括六块:main,events,http,server ...
- The method getServletContext() is undefined for the type HttpServletRequest
request.getServletContext().getRealPath("/") 已经加入了 sun runtime library但是还是提示错误 是因为 写法过时了改成 ...
- 【java】解析JToolBar类的使用
1.简介 在大部分的Look and Feels下,用户都可以把该工具条拖离原Window组件(除非floatable属性设置为false).为了能够正常的实现拖动效果,该类的实例被建议添加到Bord ...
- 【SQL】SQL中Case When的用法
Case具有两种格式.简单Case函数和Case搜索函数. --简单Case函数 CASE sex ' THEN '男' ' THEN '女' ELSE '其他' END --Case搜索函数 ' T ...
- AndroidStudio升级到2.3版本无法编译的解决方法
上周五as提示更新,于是为了体验新功能还在编码过程中就迫不及待的点击了更新,公司网很快,十几分钟就下载好,然后一重启就懵逼了,提示是否更改依赖版本到2.3以及升级gradle到3.3,点了确定就一直在 ...