关键词抽取:pagerank,textrank
摘抄自微信公众号:AI学习与实践
TextRank,它利用图模型来提取文章中的关键词。由 Google 著名的网页排序算法 PageRank 改编而来的算法。
PageRank
PageRank 是一种通过网页之间的超链接来计算网页重要性的技术,以 Google 创办人 Larry Page 之姓来命名,Google 用它来体现网页的相关性和重要性。
PageRank 通过网络浩瀚的超链接关系来确定一个页面的等级,把从 A 页面到 B 页面的链接解释为 A 页面给 B 页面投票,Google 根据 A 页面(甚至链接到 A的页面)的 等级和投票 目标的等级来决定 B 的等级。
简单的说,一个高等级的页面可以使其他低等级页面的等级提升。
整个互联网可以看作是一张有向图图,网页是图中的节点,网页之间的链接就是图中的边。如果网页 A 存在到网页 B 的链接,那么就有一条从网页 A 指向网页 B 的有向边。
构造完图后,使用下面的公式来计算网页 i的重要性(PR值):

TextRank
TextRank 公式在 PageRank 公式的基础上,为图中的边引入了权值的概念:

用
TextRank 算法计算图中各节点的得分时,同样需要给图中的节点指定任意的初值,通常都设为1。然后递归计算直到收敛,即图中任意一点的误差率小于给定的极限值时就可以达到收敛,一般该极限值取 0.0001。
使用 TextRank 提取关键词
现在是要提取关键词,如果把单词视作图中的节点(即把单词看成句子),那么所有边的权值都为 0(两个单词没有相似性),所以通常简单地把所有的权值都设为 1。
此时算法退化为 PageRank,因而把关键字提取算法称为 PageRank 也不为过。
我们把文本拆分为单词,过滤掉停用词(可选),并只保留指定词性的单词(可选),就得到了单词的集合。假设一段文本依次由下面的单词组成:
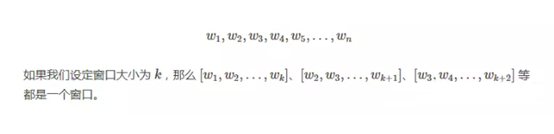
现在将每个单词作为图中的一个节点,同一个窗口中的任意两个单词对应的节点之间存在着一条边。然后利用投票的原理,将边看成是单词之间的互相投票,经过不断迭代,每个单词的得票数都会趋于稳定。
一个单词的得票数越多,就认为这个单词越重要。
使用 TextRank 提取摘要
自动摘要,就是从文章中自动抽取关键句。人类对关键句的理解通常是能够概括文章中心的句子,而机器只能模拟人类的理解,即拟定一个权重的评分标准,给每个句子打分,之后给出排名靠前的几个句子。
基于 TextRank 的自动文摘属于自动摘录,通过选取文本中重要度较高的句子形成文摘。
依然使用 TextRank 公式:

关键词抽取:pagerank,textrank的更多相关文章
- 数据挖掘:基于Spark+HanLP实现影视评论关键词抽取(1)
1. 背景 近日项目要求基于爬取的影视评论信息,抽取影视的关键字信息.考虑到影视评论数据量较大,因此采用Spark处理框架.关键词提取的处理主要包含分词+算法抽取两部分.目前分词工具包较为主流的,包括 ...
- 关键词提取算法TextRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank. ...
- 自然语言处理工具hanlp关键词提取图解TextRank算法
看一个博主(亚当-adam)的关于hanlp关键词提取算法TextRank的文章,还是非常好的一篇实操经验分享,分享一下给各位需要的朋友一起学习一下! TextRank是在Google的PageRan ...
- 关键词提取算法-TextRank
今天要介绍的TextRank是一种用来做关键词提取的算法,也可以用于提取短语和自动摘要.因为TextRank是基于PageRank的,所以首先简要介绍下PageRank算法. 1.PageRank算法 ...
- 【API进阶之路】逆袭!用关键词抽取API搞定用户需求洞察
摘要: 老大说,我这份用关键词抽取API搞定的用户需求洞察报告,简直比比市场调研的科班人士做得还好. 最近这半个月的午饭,那可是相当不错,市场老大天天请吃饭,不是外面下馆子,就是从家带饺子.说是感谢我 ...
- 使用 Node.js 对文本内容分词和关键词抽取
npm install nodejieba var nodejieba = require("nodejieba"); var result = nodejieba.cut(&qu ...
- python 结巴分词简介以及操作
中文分词库:结巴分词 文档地址:https://github.com/fxsjy/jieba 代码对 Python 2/3 均兼容 全自动安装:easy_install jieba 或者 pip in ...
- Spark项目应用-电子商务大数据分析总结
一. 数据采集(要求至少爬取三千条记录,时间跨度超过一星期)数据采集到本地文件内容 爬取详见:python爬取京东评论 爬取了将近20000条数据,156个商品种类,用时2个多小时,期间中断数 ...
- TextRank:关键词提取算法中的PageRank
很久以前,我用过TFIDF做过行业关键词提取.TFIDF仅仅从词的统计信息出发,而没有充分考虑词之间的语义信息.现在本文将介绍一种考虑了相邻词的语义关系.基于图排序的关键词提取算法TextRank [ ...
随机推荐
- 利用 log-pilot + elasticsearch + kibana 搭建 kubernetes 日志解决方案
开发者在面对 kubernetes 分布式集群下的日志需求时,常常会感到头疼,既有容器自身特性的原因,也有现有日志采集工具的桎梏,主要包括: 容器本身特性: 采集目标多:容器本身的特性导致采集目标多, ...
- (原)torch模型转pytorch模型
转载请注明出处: http://www.cnblogs.com/darkknightzh/p/7839263.html 目前使用的torch模型转pytorch模型的程序为: https://gith ...
- Python装饰器几个有用又好玩的例子
装饰器是一种巧妙简洁的魔术,类似于Java中的面向切面编程,我们可以再函数执行前.执行后.抛出异常时做一些工作.利用装饰器,我们可以抽象出一些共同的逻辑,简化代码.而简化代码的同时,就是在增加代码鲁棒 ...
- Centos7-Lvs+Keepalived架构
Centos7-Lvs+Keepalived架构 LVS+Keepalived 介绍 1 . LVS LVS 是一个开源的软件,可以实现 LINUX 平台下的简单负载均衡. LVS 是 Lin ...
- 在家赚钱,威客网站的使用方法 CSDN项目频道、SXSOFT、任务中国、猪八戒四个网站的线上交易 三种交易模式(1)悬赏模式(2)招标模式(3)直接交易模式
在家赚钱,威客网站的使用方法 很显然,<让猪八戒飞一会儿>作者对威客这一行业不熟悉,<让猪八戒飞一会儿>文章中错误有一些,不一一指出.我在CSDN项目频道.SXSOFT.任务中 ...
- 树莓派进阶之路 (012) - 树莓派配置文档 config.txt 说明
原文连接:http://elinux.org/RPi_config.txt 由于树莓派并没有传统意义上的BIOS, 所以现在各种系统配置参数通常被存在”config.txt”这个文本文件中. 树莓派的 ...
- 【java】break outer,continue outer的使用
break默认是结束当前循环,有时我们在使用循环时,想通过内层循环里的语句直接跳出外层循环,java提供了使用break直接跳出外层循环,此时需要在break后通过标签指定外层循环.java中的标签是 ...
- 数十种TensorFlow实现案例汇集:代码+笔记
这是使用 TensorFlow 实现流行的机器学习算法的教程汇集.本汇集的目标是让读者可以轻松通过案例深入 TensorFlow. 这些案例适合那些想要清晰简明的 TensorFlow 实现案例的初学 ...
- JavaScript三种方式改变标签css
原文地址:https://www.cnblogs.com/xiangru0921/p/6514225.html <body> <div id="div">这 ...
- 【C语言】练习3-5
题目来源:<The C programming language>中的习题P51 练习2-1: 编写函数itob(n, s, b),将整数n转换为以b为底的数,并将转换结果以字符的形 ...