Data Warehouse 简介
数据仓库定义
数据仓库之父Bill Inmon在1991年出版的“Building the Data Warehouse”一书中所提出的定义被广泛接受:数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrated)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(Decision Making Support)。
数据仓库特点
1. 面向主题。操作型数据库的数据组织面向事务处理任务,各个业务系统之间各自分离,而数据仓库中的数据是按照一定的主题域进行组织。主题是一个抽象的概念,是指用户使用数据仓库进行决策时所关心的重点方面,一个主题通常包含多个操作型信息系统。
2. 集成的。面向事务处理的操作型数据库通常与某些特定的应用相关,数据库之间相互独立,并且往往是异构的。而数据仓库中的数据是在对原有分散的数据库数据抽取、清理的基础上经过系统加工、汇总和整理得到的,必须消除元数据中的不一致性,以保证数据仓库内的信息是关于整个企业的一致的全局信息。
3. 相对稳定的。操作型数据库中的数据通常实时更新,数据根据需要及时发生变化。数据仓库的数据主要供企业决策分析之用,所涉及的数据操作主要是数据查询,一旦某个数据进入数据仓库以后,一般情况下将被长期保留,也就是数据仓库中一般有大量的查询操作,但修改和删除操作很少,通常只需要定期的加载、刷新。
4.反映历史变化。操作型数据库主要关心当前某一个时间段内的数据,而数据仓库中的数据通常包含历史信息,系统记录了企业从过去某一时点(如开始应用数据仓库的时点)到目前的各个阶段的信息,通过这些信息,可以对企业的发展历程和未来趋势做出定量分析和预测。
数据仓库中的数据
包括元数据、粒度数据、当前详细数据,历史数据、档案数据。
1. 元数据:最重要的部分,关于数据的数据。也称为数据仓库的结构,是所有数据的集成体现。仓库开发者使用元数据来管理和控制仓库的建立和维护。
2. 粒度数据:定义为数据仓库所保持的信息的概要程度。不同粒度表示为不同级别的汇总数据。汇总数据是信息仓库的特点,所有的企业数据分类(按部门、地区、功能等)需要的信息都不同,同时有效的信息仓库设计是为不同风格提供的,轻量级汇总数据为整个企业组成部分服务。通过企业数据分类找到详细和汇总数据。但是它依旧比仓库中的详细数据少得多。高度汇总数据是企业执行的主要依据,它来自根据企业组成部分的轻量级汇总数据或来自当前详细数据。这一层的 数据容量比其他任何一个都少,代表一个折衷的积累,用来支持广泛的各式的需要和兴趣。通过高度汇总,执行者能够使用“钻取”到达逐步增加的详细层。
3. 当前详细数据:是信息仓库的核心,存放大量数据。数据来自业务操作数据库,通过主题来组织,不是代表特定应用,而是代表整个企业。在仓库中数据粒度最低,当数据精确化时,其中的每一个数据实体都是一个快照、一个时刻,表示一个瞬间。一旦需要经常支持企业需求,数据随即进行更新。
4. 历史数据:以前的有意义数据(一般两年以上),给企业带来延续的利益和价值。包含巨大的数据量,可以用来预测和趋势分析。包括:旧数据(原始或汇总形式)、描述旧数据特征的元数据。
数据仓库的基本架构
数据仓库的目的是构建面向分析的集成化数据环境,为企业提供决策支持(Decision Support)。其实数据仓库本身并不“生产”任何数据,同时自身也不需要“消费”任何的数据,数据来源于外部,并且开放给外部应用,这也是为什么叫“仓库”,而不叫“工厂”的原因。因此数据仓库的基本架构主要包含的是数据流入流出的过程,可以分为三层——源数据、数据仓库、数据应用:
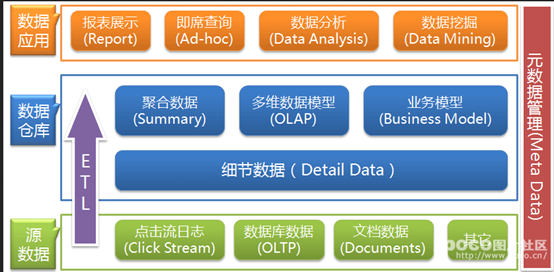
从图中可以看出数据仓库的数据来源于不同的源数据,并提供多样的数据应用,数据自自下而上流入数据仓库后向上层开放应用,而数据仓库只是中间集成化数据管理的一个平台。
数据仓库的数据来源
数据仓库从各数据源获取数据及在数据仓库内的数据转换和流动都可以认为是ETL(抽取Extra, 转化Transfer, 装载Load)的过程,ETL是数据仓库的流水线,也可以认为是数据仓库的血液,它维系着数据仓库中数据的新陈代谢,而数据仓库日常的管理和维护工作的大部分精力就是保持ETL的正常和稳定。
数据仓库的数据存储
数据仓库并不需要储存所有的原始数据,同时数据仓库需要储存部分细节数据。简单地解释下:
1. 为什么不需要所有原始数据?数据仓库面向分析处理,但是某些源数据对于分析而言没有价值或者其可能产生的价值远低于储存这些数据所需要的数据仓库的实现和性能上的成本。比如我们知道用户的省份、城市足够,至于用户究竟住哪里可能只是物流商关心的事,或者用户在博客的评论内容可能只是文本挖掘会有需要,但将这些冗长的评论文本存在数据仓库就得不偿失;
2. 为什么要存细节数据?细节数据是必需的,数据仓库的分析需求会时刻变化,而有了细节数据就可以做到以不变应万变。如果我们只存储根据某些需求搭建起来的数据模型,那么显然对于频繁变动的需求会手足无措;
数据仓库基于维护细节数据的基础上在对数据进行处理,使其真正地能够应用于分析
主要包括三个方面:
1. 数据的聚合
这里的聚合数据指的是基于特定需求的简单聚合(基于多维数据的聚合体现在多维数据模型中),简单聚合可以是网站的总Pageviews、Visits、Unique Visitors等汇总数据,也可以是Avg. time on page、Avg. time on site等平均数据,这些数据可以直接地展示于报表上。
2. 多维数据模型
多维数据模型提供了多角度多层次的分析应用,比如基于时间维、地域维等构建的销售星形模型、雪花模型,可以实现在各时间维度和地域维度的交叉查询,以及基于时间维和地域维的细分。所以数据仓库面向特定群体的数据集市都是基于多维数据模型进行构建的。
3. 业务模型
这里的业务模型指的是基于某些数据分析和决策支持而建立起来的数据模型,比如我之前介绍过的用户评价模型、关联推荐模型、RFM分析模型等,或者是决策支持的线性规划模型、库存模型等;同时,数据挖掘中前期数据的处理也可以在这里完成。
数据仓库的数据应用
1. 报表展示
报表几乎是每个数据仓库的必不可少的一类数据应用,将聚合数据和多维分析数据展示到报表,提供了最为简单和直观的数据。
2. 即时查询
理论上数据仓库的所有数据(包括细节数据、聚合数据、多维数据和分析数据)都应该开放即时查询,即时查询提供了足够灵活的数据获取方式,用户可以根据自己的需要查询获取数据。
3. 数据分析
数据分析大部分基于构建的业务模型展开,当然也可以使用聚合的数据进行趋势分析、比较分析、相关分析等,而多维数据模型提供了多维分析的数据基础;同时从细节数据中获取一些样本数据进行特定的分析也是较为常见的一种途径。
4. 数据挖掘
数据挖掘用一些高级的算法可以让数据展现出各种令人惊讶的结果。数据挖掘可以基于数据仓库中已经构建起来的业务模型展开,但大多数时候数据挖掘会直接从细节数据上入手,而数据仓库为挖掘工具诸如SAS、SPSS等提供数据接口。
元数据
数据仓库环境中一个重要方面是元数据。元数据是关于数据的数据。只要有程序和数据,元数据就是信息处理环境的一部分。但是在数据仓库中,元数据扮演一个新的重要角色。也正因为有了元数据,可以最有效地利用数据仓库。元数据使得最终用户/ DSS分析员能够探索各种可能性。
元数据在数据仓库的上层,并且记录数据仓库中对象的位置。典型地,元数据记录:
l 程序员所知的数据结构。
l DSS(决策支持系统)分析员所知的数据结构。
l 数据仓库的源数据。
l 数据加入数据仓库时的转换。
l 数据模型。
l 数据模型和数据仓库的关系。
l 抽取数据的历史记录。
数据集市
数据集市(Data Market)是一种更小、更集中的数据仓库。简单地说,原始数据从数据仓库流入不同的部门以支持这些部门的定制化使用。这些部门级的数据库就称为数据集市。一个数据集市就是一个部门的数据集合。数据集市是为特定部门的决策支持而组织起来的一批数据和业务规则,习惯上称它们为“主题域”。不同部门有不同的“主题域”,因而也就有不同的数据集市。例如,财务部门有自己的数据集市,市场部门也有自己的数据集市,它们之间可能有关联,但相互不同且在本质上互为独立。
尽管数据集市与数据仓库在很多方面有类似之处,但它们之间却存在着区别。主要体现在:
(1)面向的对象不同。数据仓库面向的是整个企业,为整个企业提供所需的数据;数据集市则面向各个部门。
(2)数据粒度不一样。数据仓库中的数据粒度非常小;数据集市中的数据主要是概括级的数据。
内容来源于网络
Data Warehouse 简介的更多相关文章
- 混合 Data Warehouse 和 Big Data 倉庫的新架構
(讀書筆記)許多公司,儘管想導入 Big Data,仍必須繼續用 Data Warehouse 來管理結構化的營運數據.系統記錄.而 Big Data 的出現,為 Data Warehouse 提供了 ...
- Azure SQL Data Warehouse
Azure SQL Data Warehouse & AWS Redshift Amazon Redshift Amazon Redshift 是一种快速.完全托管的 PB 级数据仓库,可方便 ...
- 场景4 Data Warehouse Management 数据仓库
场景4 Data Warehouse Management 数据仓库 parallel 4 100% —> 必须获得指定的4个并行度,如果获得的进程个数小于设置的并行度个数,则操作失败 para ...
- 浅析基于微软SQL Server 2012 Parallel Data Warehouse的大数据解决方案
作者 王枫发布于2014年2月19日 综述 随着越来越多的组织的数据从GB.TB级迈向PB级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代.对海量数据的处理.分析能力,日益成为组织在这个 ...
- 转:浅析基于微软SQL Server 2012 Parallel Data Warehouse的大数据解决方案
综述 随着越来越多的组织的数据从GB.TB级迈向PB级,标志着整个社会的信息化水平正在迈入新的时代 – 大数据时代.对海量数据的处理.分析能力,日益成为组织在这个时代决胜未来的关键因素,而基于大数据的 ...
- Data Warehouse
Knowledge Discovery Process OLTP & OLAP 联机事务处理(OLTP, online transactional processing)系统:涵盖组织机构大部 ...
- DataBase vs Data Warehouse
Database https://en.wikipedia.org/wiki/Database A database is an organized collection of data.[1] A ...
- data warehouse 1.0 vs 2.0
data warehouse 1.01. EDW goal, separate data marts reqlity2. batch oriented etl3. IT driven BI - das ...
- Azure SQL 数据库仓库Data Warehouse (1) 入门
<Windows Azure Platform 系列文章目录> 在之前的项目中遇到了客户使用SQL数据仓库的场景,在这里记录一下 1.什么是SQL 数据库仓库 (SQL DW) SQL D ...
随机推荐
- spring DelegatingFilterProxy管理过滤器
安全过滤器链 Spring Security的web架构是完全基于标准的servlet过滤器的.它没有在内部使用servlet或任何其他基于servlet的框架(比如spring mvc),所以它没有 ...
- [巩固C#] 二、什么是反射、反射可以做些什么
阅读目录 关闭 什么是反射,反射能干嘛? 获取类型的相关信息 获取类型本身信息(命名空间名.全名.是否是抽象.是否是类..... 获取类型成员信息(通过Tyep中的方法GetMembers ...
- MongoDB Windows环境搭建
简介 MongoDB 是由C++语言编写的,是一个基于分布式文件存储的开源数据库系统. 在高负载的情况下,添加更多的节点,可以保证服务器性能. MongoDB 旨在为WEB应用提供可扩展的高性能数据存 ...
- 负载均衡配置下的不同服务器【Linux】文件同步问题
负载均衡配置下的不同服务器[Linux]文件同步问题2017年04月13日 22:04:28 守望dfdfdf 阅读数:2468 标签: linux负载均衡服务器 更多个人分类: 工作 问题编辑版权声 ...
- Vue之组件间传值
标签: Vue Vue之父子组件传值 父向子传递通过props 子向父传递通过$emit 演示地址 代码示例如下: <!DOCTYPE html> <html lang=" ...
- CSS Grid 布局学习笔记
CSS Grid 布局学习笔记 好久没有写博客了, MDN 上关于 Grid 布局的知识比较零散, 正好根据我这几个月的实践对 CSS Grid 布局做一个总结, 以备查阅. 1. 基础用法 Grid ...
- ZIP文件流压缩和解压
前面写了一篇文章 "ZIP文件压缩和解压", 介绍了" SharpZipLib.Zip " 的使用, 最近的项目中,在使用的过程中, 遇到一些问题. 比如, 现 ...
- lucene中文学习地址推荐
Lucene原理与代码分析http://www.cnblogs.com/forfuture1978/category/300665.html Lucene5.5学习(1)-初尝Lucene全文检索引擎 ...
- C#设计模式--适配器模式(结构型模式)
一.适配器模式介绍: 适配器模式:将一个类的接口,转换成客户希望的另外一个接口.adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作 例子分析(充电器充电): 模式中的角色: 安 ...
- “System.OutOfMemoryException”类型的未经处理的异常在 mscorlib.dll 中发生
在VS中写程序遇到这样的问题.但数据规模小的时候不出现,但数据规模大的时候就出现.但我的电脑用32G内存.处理的文本也不是很多,在文本alignment时出错.