JDK 8 - java.util.HashMap 实现机制分析
官方文档对 HashMap 的定义:
public class HashMap<K,V>
extends AbstractMap<K,V>
implements Map<K,V>, Cloneable, Serializable
UML Class Diagram:
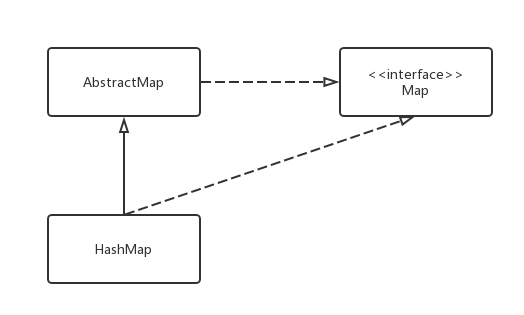
HashMap 实现了 Map interface。
HashMap 是一个数据结构,如同一个 DBMS 一样,基本功能其实就是增删改查。
| Operations | Time Complexity | Notes |
| get, put | O(1) | assuming the hash function has dispersed the elements properly among the buckets |
| iteration over collection views | proportional to the capacity plus the size | do not set the initial capacity too high or the load factor too low |
- 不保证迭代顺序,也不保证顺序一直不变。
- 非同步,允许null值(key&value)
- 迭代的时间复杂度:O(capacity+#mappings),与容量和元素数量有关(若对迭代性能要求高,不要将capacity设置过高,load factor设置过小,避免空闲空间过多)。
- 内部数组长度为2的幂次方(为了高效实现取模运算),元素下标通过hash&(length-1)计算得到;hash&(length-1) == hash%length,这两个操作等价但不等效,前者更高效(使用了位与运算)。
1、 根据 key 查询 map
调用 get(Object key) 方法:
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
hash(key):
/**
* Computes key.hashCode() and spreads (XORs) higher bits of hash
* to lower. Because the table uses power-of-two masking, sets of
* hashes that vary only in bits above the current mask will
* always collide. (Among known examples are sets of Float keys
* holding consecutive whole numbers in small tables.) So we
* apply a transform that spreads the impact of higher bits
* downward. There is a tradeoff between speed, utility, and
* quality of bit-spreading. Because many common sets of hashes
* are already reasonably distributed (so don't benefit from
* spreading), and because we use trees to handle large sets of
* collisions in bins, we just XOR some shifted bits in the
* cheapest possible way to reduce systematic lossage, as well as
* to incorporate impact of the highest bits that would otherwise
* never be used in index calculations because of table bounds.
*/
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这个方法计算 key 的哈希值,可以看到如果 key == null,哈希值为 0;
否则,调用 Object.hashCode() 计算 key 的哈希值,再将这个哈希值的低16位与自己的高16位按位异或,最后返回这个异或值。
从注释看,设计者为了降低 key collision,综合考虑了 速度、实用、质量三个指标,再加上一般情况下key 的分布已经很均匀了,所以仅仅利用了key哈希值的高16位进行异或,最后得到了比较理想的结果。
然后调用了 getNode(int hash, Object key),这个方法为 final,子类无法覆盖:
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
// 如果table != null && not empty && 根据 hash 找到对应位置的元素也不为null
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
// 如果哈希值相等 &&(key相同或相等),则找到了元素,直接返回
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
// 不是要找的元素,查找这个元素的下一个元素
if ((e = first.next) != null) {
// 是一棵树,调用 getTreeNode 查找
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
// 是一个链表,顺序查找
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
2、往 map 里插入数据
直接调用的是 put(K key, V value):
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
又调用了putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict),这个方法为 final,子类无法覆盖:
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果 table is null or is empty,调用resize()初始化table,默认大小16,负载因子0.75
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 根据hash找到对应位置的元素,如果这个元素为null则直接新增node;其中 (n - 1) & hash 使用了位与运算(&),比取余运算(%)更高效
if ((p = tab[i = (n - 1) & hash]) == null)
// 直接新建一个node并放到这个位置
tab[i] = newNode(hash, key, value, null);
// 不为null,则进一步检查
else {
Node<K,V> e; K k;
// 第一个元素就是我们要找的元素,最后e要么为空,要么保存了我们要找的元素
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 是一棵树,调用putTreeVal()方法
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
// 是一个链表,遍历这个链表
else {
for (int binCount = 0; ; ++binCount) {
// 没有找到,则在最后新增一个node,只有在这种情况下e==null
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 如果binCount>=TREEIFY_THRESHOLD - 1,则将链表转换为树
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 找到元素,跳出循环
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
// 没有找到元素,且没有到最后一个元素,则继续遍历下一个元素p
p = e;
}
}
// e != null 说明我们要找的元素存在于map中,就是e这个元素
if (e != null) { // existing mapping for key
V oldValue = e.value;
// 更新对应的 value
if (!onlyIfAbsent || oldValue == null)
e.value = value;
// 空方法,由LinkedHashMap覆盖
afterNodeAccess(e);
// 返回旧值,其他情况说明key原来不存在,返回null
return oldValue;
}
}
// 改变了map的结构,自增modCount
++modCount;
// 自增size,如果size超过了阈值,则调用resize()对容量增加一倍
if (++size > threshold)
resize();
// 空方法,由LinkedHashMap覆盖
afterNodeInsertion(evict);
return null;
}
3、HashMap使用的树是红黑树
HashMap的节点分为普通的节点 Node, 树节点 TreeNode。
Node:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
// 省略部分代码
}
TreeNode 相比于 Node,增加了 before, after, parent, left, right, prev 等“指针”。
static final class TreeNode<K,V> extends LinkedHashMap.Entry<K,V> {
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red;
TreeNode(int hash, K key, V val, Node<K,V> next) {
super(hash, key, val, next);
}
/**
* Returns root of tree containing this node.
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
if ((p = r.parent) == null)
return r;
r = p;
}
}
// 省略部分代码
}
JDK 8 - java.util.HashMap 实现机制分析的更多相关文章
- JDK 8 - java.util.HashSet 实现机制分析
JDK 8 Class HashSet<E> Doc: public class HashSet<E> extends AbstractSet<E> impleme ...
- java.util.HashMap源码分析
在java jdk8中对HashMap的源码进行了优化,在jdk7中,HashMap处理“碰撞”的时候,都是采用链表来存储,当碰撞的结点很多时,查询时间是O(n). 在jdk8中,HashMap处理“ ...
- JDK1.8源码(七)——java.util.HashMap 类
本篇博客我们来介绍在 JDK1.8 中 HashMap 的源码实现,这也是最常用的一个集合.但是在介绍 HashMap 之前,我们先介绍什么是 Hash表. 1.哈希表 Hash表也称为散列表,也有直 ...
- java:警告:[unchecked] 对作为普通类型 java.util.HashMap 的成员的put(K,V) 的调用未经检查
java:警告:[unchecked] 对作为普通类型 java.util.HashMap 的成员的put(K,V) 的调用未经检查 一.问题:学习HashMap时候,我做了这样一个程序: impor ...
- LinkedHashMap和HashMap的比较使用 由于现在项目中用到了LinkedHashMap,并不是太熟悉就到网上搜了一下。 ? import java.util.HashMap; impo
LinkedHashMap和HashMap的比较使用 由于现在项目中用到了LinkedHashMap,并不是太熟悉就到网上搜了一下. import java.util.HashMap; import ...
- java.util.HashMap和java.util.HashTable (JDK1.8)
一.java.util.HashMap 1.1 java.util.HashMap 综述 java.util.HashMap继承结构如下图 HashMap是非线程安全的,key和value都支持nul ...
- java.lang.ClassCastException: java.util.HashMap cannot be cast to java.lang.String
问题背景:从前端传来的json字符串中取某些值,拼接成json格式入参调外部接口. 报如下错: java.lang.ClassCastException: java.util.HashMap cann ...
- EL1008E: Property or field 'timestamp' cannot be found on object of type 'java.util.HashMap
2018-06-22 09:50:19.488 INFO 20096 --- [nio-8081-exec-2] o.a.c.c.C.[Tomcat].[localhost].[/] : ...
- 原子类java.util.concurrent.atomic.*原理分析
原子类java.util.concurrent.atomic.*原理分析 在并发编程下,原子操作类的应用可以说是无处不在的.为解决线程安全的读写提供了很大的便利. 原子类保证原子的两个关键的点就是:可 ...
随机推荐
- Ubuntu: 无法使用su命令
Ubuntu 无法使用su命令解决方案 在Ubuntu上编译Qt环境时发现无法使用su命令切换到root用户,通过网上查找发现解决方案如下: xt@xt-ubuntu:~$ su密码: su:认证失败 ...
- INSPIRED启示录 读书笔记 - 前言
好的产品具备三个基本条件 价值.可用性.可行性,三者缺一不可 产品经理日常工作 1.人员是指负责定义和开发产品的团队成员的角色和职责 2.流程是指探索.开发富有创意的产品时,反复应用的和成功的实践经验 ...
- Spark总结1
安装jdk 下载spark安装包 解压 重点来了: 配置 spark: 进入 conf ----> spark-env.sh.template文件 cd conf/ mv spark-env ...
- 【P2325】王室联邦(树的遍历+贪心)
在肖明 #神#的推荐下,我尝试了这个题,一开始想的是暴力枚举所有的点,然后bfs层数,试着和肖明 #神#说了这种方法之后, #神#轻蔑的一笑,说这不就是一个贪心么,你只需要先建树,然后从底下向上遍历, ...
- Python OS导入一个文件夹所有文件
import os path = 'F:/save_file/seminarseries/' for root, dirs, files in os.walk(path): print(root) 这 ...
- (转)Openstack Cascading和Nova Cell
Openstack是看着AWS成长起来的,这点毋庸置疑:所以AWS大规模商用已成事实的情况下,Openstack也需要从架构和产品实现上进行优化,以满足大规模商用的要求.从已有的实现来看其中两种方式值 ...
- js判断是pc还是移动端
//判断pc还是移动端 var isM = function () { var ua = navigator.userAgent; /* navigator.userAgent 浏览器发送的用户代理标 ...
- spring: 在表达式中使用类型
如果要在SpEL中访问类作用域的方法和常量的话,要依赖T()这个关键的运算符.例如,为了在SpEL中表达Java的Math类,需要按照如下的方式使用T()运算符: T{java.lang.Math} ...
- java: InputStreamReader将字节的输入流变成字符的输入流,OutputStreamWriter将字符的输出流变成字节的输出流
InputStreamReader:将字节的输入流变成字符的输入流, OutputStreamWriter:将字符的输出流变成字节的输出流 //将缓冲区的内容读取,可以一次读取 //可以接收键盘的输入 ...
- 如果看看机器ip和域名ip
1.如果查看一个机器IP ifconfig或hostname -i //linux ipconfig //windows 2.查看一个域名对应ip ping www.baidu.com 下面会显示域名 ...