<轻量算法>根据核密度估计检测波峰算法 ---基于有限状态自动机和递归实现
原创博客,转载请联系博主!
希望我思考问题的思路,也可以给大家一些启发或者反思!
问题背景:
现在我们的手上有一组没有明确规律,但是分布有明显聚簇现象的样本点,如下图所示:
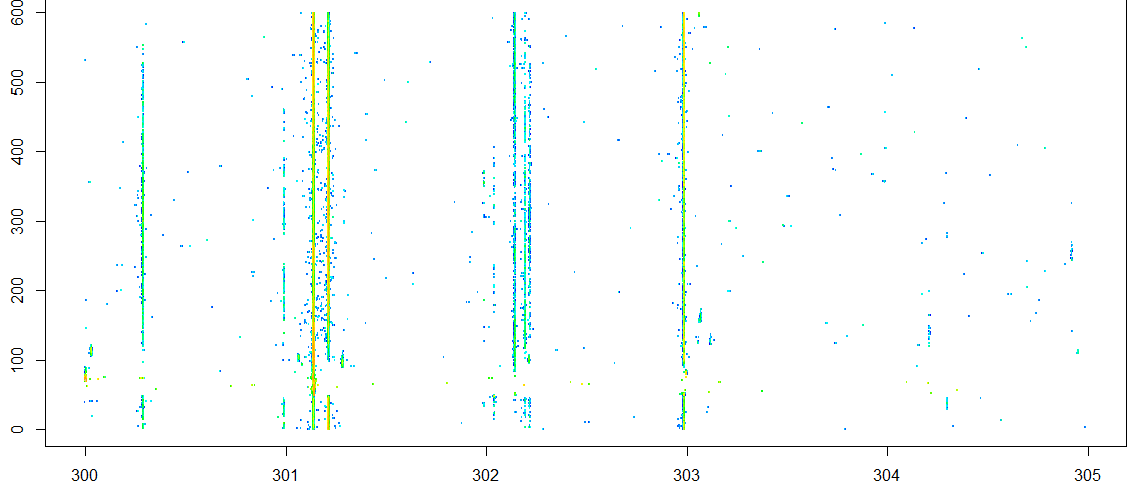

图中数据集是显然是个3维的数据集,包括横纵坐标和色彩(高度),由于数据的分布比较不均匀,我们选择分布比较典型的[300,305)区间的数据点进行处理
我们的目的是找出这个数据空间中数据比较集中的部分,根据肉眼对样本的初步观察,这篇文章将讨论一个从横轴的维度对数据较密集的区域进行识别的一个轻量算法,其实也就是找出数据空间中的所谓“条状物”。
算法思路:
其实如果不限制处理数据的维度,那么一个更准确的算法思路是使用非圆形聚类算法对数据样本进行处理,经过实验结果也确实符合我们的想法。
在这里我们的思路是这样的:
1.首先使用核密度估计算法对样本区间进行一个直观的统计
2.对样本进行归一化
3.对处理后的样本做求导数(这里为了追求效率使用向后差分)
4.通过对样本的统计结果使用有限状态自动机进行扫描,得到一个记录的峰值的结果
这里为了客观衡量算法的效率和准确度我们使用一个 加速比 和 过滤比 作为标准。
过滤比: =得到的“条状物”中的样本的个数/样本的全部个数

加速比: =得到的“条状物”的横轴长度/整个样本横轴区间长度

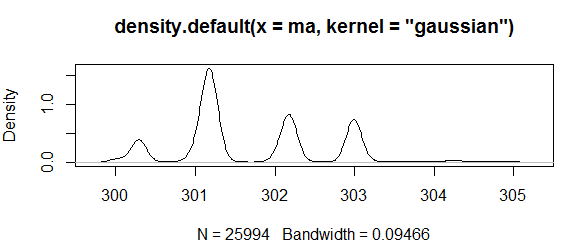
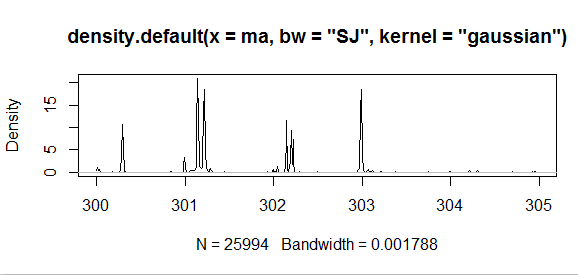
由于核密度估计的核函数有很多种选择,包括高斯核,伽马核,三角核,矩形核等,我们这里选择相对比较平滑的高斯核核函数对样本进行核密度估计统计,而且带宽的选择也有两种一个是迭代计算的,结果拟合得比较真实准确但是速度比较慢,另一种是非迭代计算的,计算速度很快但是结果也过于“平滑”。如下图所示:
非迭代计算核密度估计:
迭代计算核密度估计:
时间消耗对比也非常明显:

所以我们处理的策略是: 用非迭代的核密度估计处理大区间的数据,当区间的长度小于一个阈值的时候,使用迭代的核密度估计对数据进行准确的拟合。
梳理下来总的思路可以用下图来表示:
1.对过大的区间进行等分成“足够小”的大区间
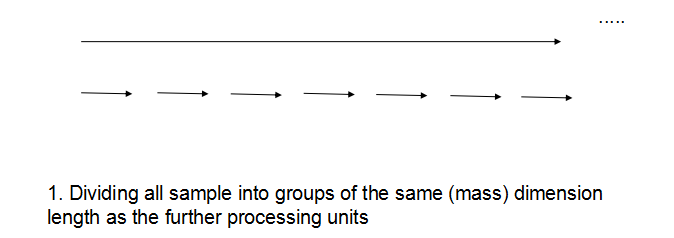
2.对分割后的区间进行递归的“统计+寻峰” (一个普通的递归处理,将起点放入peakStart数组中,终点放入peakEnd数组中)
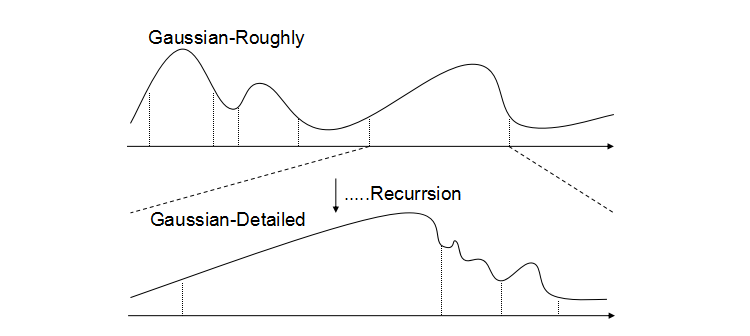
自动机寻峰的思路是这样的:
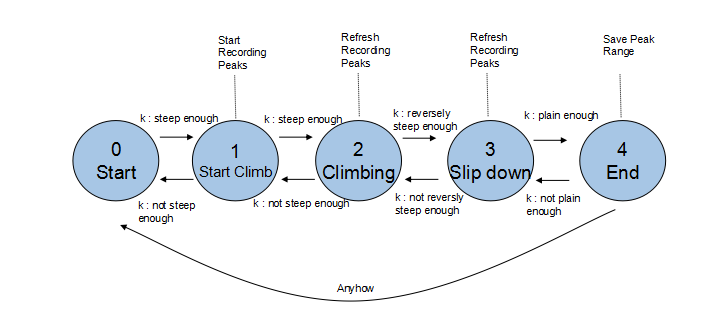
在对样本进行归一化处理和差分求导之后,根据对样本的观察,我们大致了解了这个样本之中峰的大致的形状,由此人工地去设定三个阈值作为自动机寻峰算法的参数:
第一个参数是判断峰开始的斜率阈值
第二个参数是判断到达峰顶的斜率阈值
第三个参数是判断峰结束的斜率阈值
设定这三个阈值是为了防止数据中的快速抖动(平滑/“降噪“后也难以避免)导致自动状态的错误或者出现过多细碎的"小峰"的状况,如下图所示是自动机的状态转换图:
下图是一次自动机寻峰之后的处理结果:

以下是这个算法对几个不同的样本区间进行处理的结果plot图:
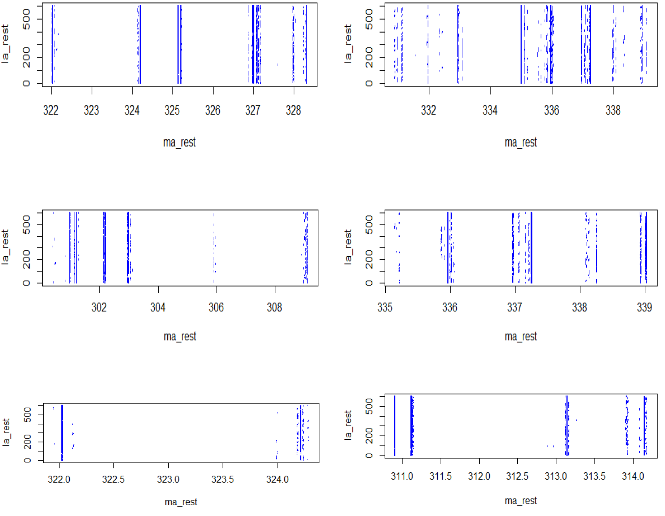
以及过滤比和加速比的结果:

实现代码(R实现):
由于项目中的一些其他原因,尽管这个算法表现不错,但最后也没有运用到项目中去,也就没有深入去做优化和修改。
R代码在我的github中: https://github.com/yue9944882/R_Util/tree/master/FSM_scan_peak
想更细节了解欢迎联系我的邮箱或者评论!
<轻量算法>根据核密度估计检测波峰算法 ---基于有限状态自动机和递归实现的更多相关文章
- 非参数估计:核密度估计KDE
http://blog.csdn.net/pipisorry/article/details/53635895 核密度估计Kernel Density Estimation(KDE)概述 密度估计的问 ...
- kdeplot(核密度估计图) & distplot
Seaborn是基于matplotlib的Python可视化库. 它提供了一个高级界面来绘制有吸引力的统计图形.Seaborn其实是在matplotlib的基础上进行了更高级的API封装,从而使得作图 ...
- 核密度估计 Kernel Density Estimation (KDE) MATLAB
对于已经得到的样本集,核密度估计是一种可以求得样本的分布的概率密度函数的方法: 通过选取核函数和合适的带宽,可以得到样本的distribution probability,在这里核函数选取标准正态分布 ...
- R语言与非参数统计(核密度估计)
R语言与非参数统计(核密度估计) 核密度估计是在概率论中用来估计未知的密度函数,属于非参数检验方法之一,由Rosenblatt (1955)和Emanuel Parzen(1962)提出,又名Parz ...
- 非参数估计——核密度估计(Parzen窗)
核密度估计,或Parzen窗,是非参数估计概率密度的一种.比如机器学习中还有K近邻法也是非参估计的一种,不过K近邻通常是用来判别样本类别的,就是把样本空间每个点划分为与其最接近的K个训练抽样中,占比最 ...
- 运动目标检测ViBe算法
一.运动目标检测简介 视频中的运动目标检测这一块现在的方法实在是太多了.运动目标检测的算法依照目标与摄像机之间的关系可以分为静态背景下运动检测和动态背景下运动检测.先简单从视频中的背景类型来讨论. ...
- AI佳作解读系列(二)——目标检测AI算法集杂谈:R-CNN,faster R-CNN,yolo,SSD,yoloV2,yoloV3
1 引言 深度学习目前已经应用到了各个领域,应用场景大体分为三类:物体识别,目标检测,自然语言处理.本文着重与分析目标检测领域的深度学习方法,对其中的经典模型框架进行深入分析. 目标检测可以理解为是物 ...
- EGADS介绍(二)--时序模型和异常检测模型算法的核心思想
EDADS系统包含了众多的时序模型和异常检测模型,这些模型的处理会输入很多参数,若仅使用默认的参数,那么时序模型预测的准确率将无法提高,异常检测模型的误报率也无法降低,甚至针对某些时间序列这些模型将无 ...
- CVPR2020论文介绍: 3D 目标检测高效算法
CVPR2020论文介绍: 3D 目标检测高效算法 CVPR 2020: Structure Aware Single-Stage 3D Object Detection from Point Clo ...
随机推荐
- HDFS源码分析数据块校验之DataBlockScanner
DataBlockScanner是运行在数据节点DataNode上的一个后台线程.它为所有的块池管理块扫描.针对每个块池,一个BlockPoolSliceScanner对象将会被创建,其运行在一个单独 ...
- shell脚本57问
[1]交互方式.非交互方式.Shell脚本是什么? 经常与linux打交道,肯定对shell这个词不陌生.不明白shell意思的,可以自行翻译:外壳.去壳. 这个翻译结果怎么可以与计算机系统联系起来呢 ...
- 走进Struts2(五)— 值栈和OGNL
值栈 1.值栈是什么? 简单说:就是相应每个请求对象的轻量级的内存数据中心. Struts2引入值栈最大的优点就是:在大多数情况下,用户根本无须关心值栈,无论它在哪里,不用管它里面有什么,仅仅须要去获 ...
- django模板加载静态资源
1. 目录结构 /mysite/setting.py部分配置: # Django settings for mysite project. import os.path TEMPLATE_DIRS = ...
- c#脚本控制shader
如图所示,c#脚本控制shader颜色. public class ControlColor : MonoBehaviour { , , , ); public Material mat; publi ...
- Intellij idea subversion checkout error
Subversion 1.8 and IntelliJ IDEA 13 Unlike its earlier versions, Subversion 1.8 support uses the nat ...
- spring;maven;github;ssm;分层;timestamp;mvn;
[说明]本来还想今天可以基本搭建一个合适的ssm环境呢,结果发现,,太特么复杂了,网上的例子有好多,看了好多,下面的评论或多或少都有说自己运行产生问题的,搞的我也不敢好好下载运行 [说明]没办法,将目 ...
- 做完task1-21的阶段总结
[说明]这是自注册修真院的第七天,也是第七篇日报,觉得是一个好的时机总结一下. 因为任务一虽然看起来仅仅是“完成学员报名的DB设计并读写数据库”,但是做了几天之后就发现在任务“搭建自己的服务器”之前的 ...
- M - 基础DP
M - 基础DP Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Descriptio ...
- python字典中包含列表时:查找字典中某个元素及赋值
直接上代码: 运行效果: