详细讲解MapReduce二次排序过程
我在15年处理大数据的时候还都是使用MapReduce, 随着时间的推移, 计算工具的发展, 内存越来越便宜, 计算方式也有了极大的改变. 到现在再做大数据开发的好多同学都是直接使用spark, hive等工具, 很少有再写MapReduce的了.
这里整理一下MapReduce中经常用到的二次排序的方法, 全当复习.
简介
二次排序(secondary sort)问题是指在Reduce阶段对某个键关联的值排序. 利用二次排序技术,可以对传入Reduce的值完成 升序/降序 排序.
MapReduce框架会自动对Map生成的键完成排序. 所以, 在启动Reduce之前,中间文件 key-value 是按照key有序的(而不是按照值有序). 它们的值得顺序有可能是任意的.
二次排序解决方案
对Reduce中的值排序至少有两种方案, 这两种方案在MapReduce/Hadoop 和 Spark框架中都可以使用.
- 第一种方案是让
Reduce读取和缓存给定key的所有的value, 然后在Reduce中对这些值完成排序.(例如: 把一个key对应的所有value放到一个Array或List中,再排序). 但是这种方式有局限性, 如果数据量较少还可以使用,如果数据量太大,一个Reduce中放不下所有的值,就会导致内存溢出(OutOfMemory). - 第二种方式是使用
MapReduce框架来对值进行排序. 因为MapReduce框架会自动对Map生成的文件的key进行排序, 所以我们把需要排序的value增加到这个key上,这样让框架对这个new_key进行排序,来实现我们的目标.
第二种方法小结:
- 使用值键转换设计模式:构造一个组合的中间key,
new_key(k, v1), 其中v1是次键(secondary key). - 让
MapReduce执行框架完成排序. - 重写分区器,使组合键
(k, v1)按照之前单独的k进行分区.
示例
假设有一组科学实验的温度数据如下:
有4列分别为: 年, 月, 日, 温度.
2000,12,04,10
2000,11,01,20
2000,12,02,-20
2000,11,07,30
2000,11,24,-40
2000,01,12,10
...
我们需要输出每一个年-月的温度,并且值按照升序排序.
所以输出如下:
(2000-11),[-40,20,30]
(2000-01),[10]
(2000-12),[-20,10]
MapReduce二次排序实现细节
要实现二次排序的特性,还需要一些java的插件类, 去告诉MapReduce框架一些信息:
- 如何对
Reduce的键排序. - 如何对
Map产出的数据进行分区,进到不同的Reduce. - 如何对
Reduce中的数据进行分组.
组合键的排序顺序
要实现二次排序, 我们需要控制组合键的排序顺序,以及Reduce处理键的顺序.
首先组合键的组成由(年-月 + 温度)一起组成, 如下图:
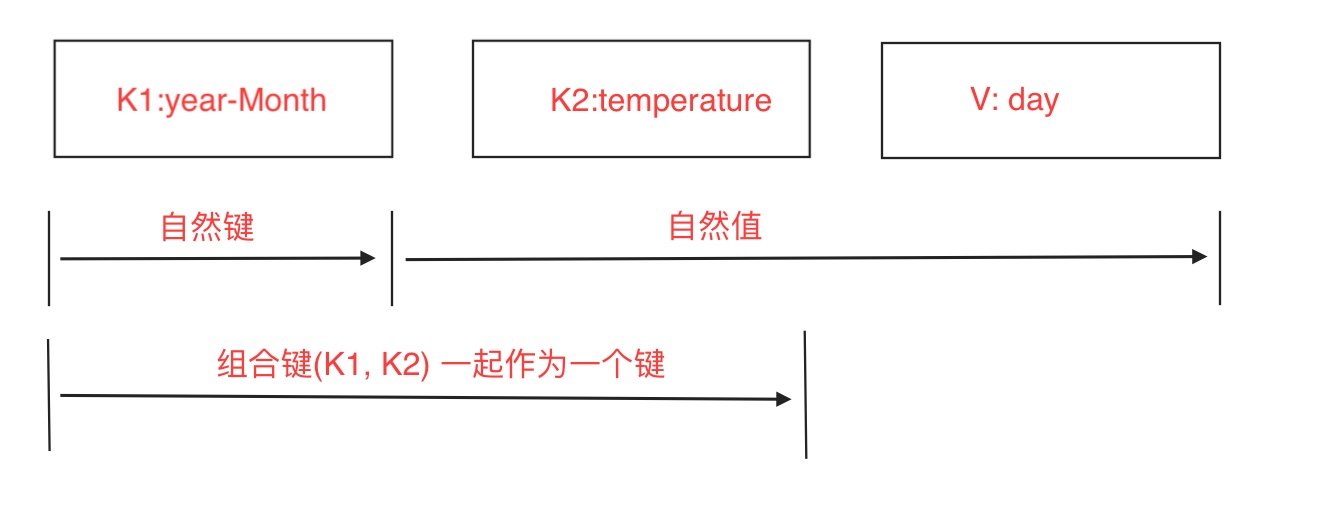 

把temperature的数据放到键中之后, 我们还要指定这个组合键排序方式. 使用DateTemperaturePair对象保存组合键, 重写其compareTo()方法指定排序顺序.
Hadoop中,如果需要持久存储定制数据类型(如DateTemperaturePair),必须实现Writable接口. 如果要比较定制数据类型, 他们还必须实现另外一个接口WritableComparable. 示例代码如下:
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.WritableComparable;
...
public class DateTemperaturePair implements Writable, WritableComparable<DateTemperaturePair> {
private Text yearMonth = new Text(); //自然键
private Text day = new Text();
private IntWritable temperature = new IntWritable(); // 次键
...
@Override
/**
* 这个比较器将控制键的排序顺序
* /
public int compareTo(DateTemperaturePair pair) {
int compareValue = this.yearMonth.compareTo(pair.getYearMonth());
if (compareValue == 0) {
compareValue = temperature.compareTo(pair.getTemperature());
}
return compareValue; //升序排序
//return -1 * compareValue; //降序排序
}
}
定制分区器
分区器默认会根据Map产出的key来决定数据进到哪个Reduce.
在这里,我们需要根据yearMonth来分区把数据入到不同的Reduce中, 但是我们的键已经变成了(yearMonth + temperature)的组合了. 所以需要定制分区器来根据yearMonth进行数据分区,把相同的yearMonth入到一个Reduce中. 代码如下:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class DateTemperaturePartitioner extends Partitioner<DateTemperaturePair, Text> {
@Override
public int getPartition(DatetemperaturePair pair, Text text, int numberOfPartitions) {
//确保分区数非负
return math.abs(pair.getYearMonth().hashCode() % numberOfPartitions);
}
}
Hadoop提供了一个插件体系,允许在框架中注入定制分区器代码. 我们在驱动累中完成这个工作,如下:
import org.apache.hadoop.mapreduce.Job;
...
Job job = ...;
...
job.setPartitionerClass(TemperaturePartitioner.class);
分组比较器
分组比较器会控制哪些键要分组到一个Reduce.reduce()方法中调用.
默认是按照key分配, 这里我们期望的是按照组合key(yearMonth + temperature) 中的yearMonth分配, 所以需要重写分组方法.
如下:
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
public class DateTemperatureGroupingComparator extends WritableComparator {
public DateTemperatureGroupingComparator() {
super(DateTemperaturePair.class, true);
} @Override
/**
* 比较器控制哪些键要分组到一个reduce()方法调用
*/
public int compare(WritableComparable wc1, WritableComparable wc2) {
DateTemperaturePair pair = (DateTemperaturePair) wc1;
DateTemperaturePair pair2 = (DateTemperaturePair) wc12;
return pair.getYearMonth().compareTo(pair2.getYearMonth()); }
}
在驱动类中注册比较器:
job.setGroupingComparatorClass(YearMonthGroupingComparator.class);
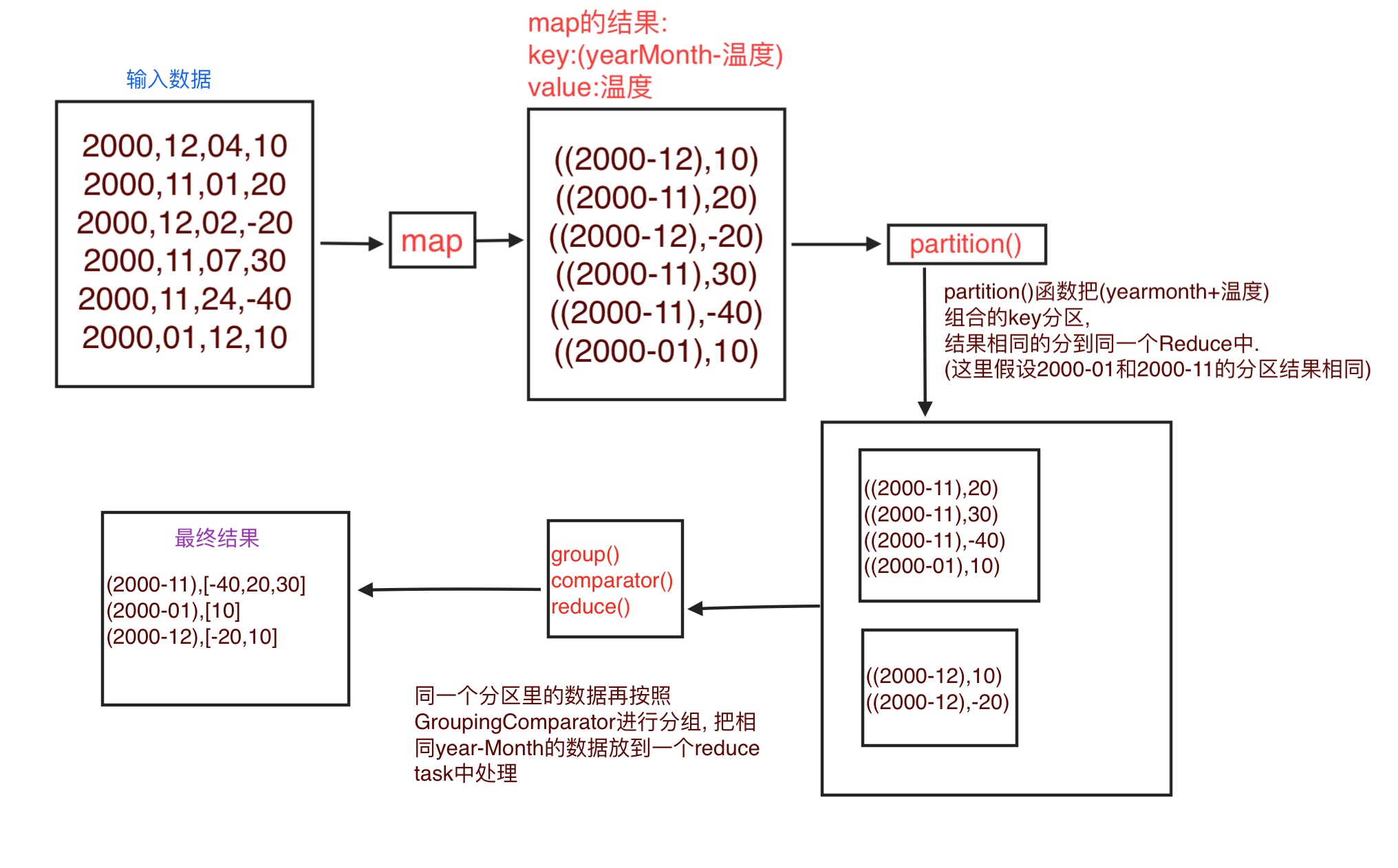
使用插件的数据流

原理总结
MapReduce框架默认会按照key来进行分区,排序,分组.
我们需要排序的时候使用key+value所以我们把key变成了新key, (firstkey, secondkey) 对应为(yearMonth, 温度) .
但是又不想在分区 和 分组的时候使用新key, 所以自己写了Partitioner 和 GroupingComparator 来指定使用组合key中的firstkey来分区,分组.
详细讲解MapReduce二次排序过程的更多相关文章
- Hadoop Mapreduce分区、分组、二次排序过程详解[转]
原文地址:Hadoop Mapreduce分区.分组.二次排序过程详解[转]作者: 徐海蛟 教学用途 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2) ...
- 关于MapReduce二次排序的一点解答
上一篇博客说明了怎么自定义Key,而且用了二次排序的例子来做测试,但没有详细的说明二次排序,这一篇说详细的说明二次排序,为了说明曾经一个思想的误区,特地做了一个3个字段的二次排序来说明.后面称其为“三 ...
- Hadoop学习笔记: MapReduce二次排序
本文给出一个实现MapReduce二次排序的例子 package SortTest; import java.io.DataInput; import java.io.DataOutput; impo ...
- (转)MapReduce二次排序
一.概述 MapReduce框架对处理结果的输出会根据key值进行默认的排序,这个默认排序可以满足一部分需求,但是也是十分有限的.在我们实际的需求当中,往往有要对reduce输出结果进行二次排序的需求 ...
- Hadoop Mapreduce分区、分组、二次排序过程详解
转载:http://blog.tianya.cn/m/post.jsp?postId=53271442 1.MapReduce中数据流动 (1)最简单的过程: map - reduce (2)定制了 ...
- mapreduce二次排序详解
什么是二次排序 待排序的数据具有多个字段,首先对第一个字段排序,再对第一字段相同的行按照第二字段排序,第二次排序不破坏第一次排序的结果,这个过程就称为二次排序. 如何在mapreduce中实现二次排序 ...
- Hadoop MapReduce 二次排序原理及其应用
关于二次排序主要涉及到这么几个东西: 在0.20.0 以前使用的是 setPartitionerClass setOutputkeyComparatorClass setOutputValueGrou ...
- MapReduce二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
- MapReduce 二次排序
默认情况下,Map 输出的结果会对 Key 进行默认的排序,但是有时候需要对 Key 排序的同时再对 Value 进行排序,这时候就要用到二次排序了.下面让我们来介绍一下什么是二次排序. 二次排序原理 ...
随机推荐
- java: jsp:param中文乱码
java: jsp:param中文乱码 假如a.jsp/b.jsp文件中 a.jsp代码: 需要加入:request.setCharacterEncoding("UTF-8") ...
- Delphi Stringlist Delimiter如何区分TAB和空格
var st: TStrings; begin st := TStringList.Create; st.StrictDelimiter := True;//这个多少人用过? st.Delimiter ...
- GW知识点
1.取值: protected void Button1_Click(object sender, EventArgs e) { string str = ""; foreach ...
- C#winform拖拽实现获得文件路径
1.关键知识点说明: 通过DragEnter事件获得被拖入窗口的“信息”(可以是若干文件,一些文字等等),在DragDrop事件中对“信息”进行解析.窗体的AllowDrop属性必须设置成true;且 ...
- [深入学习C#]C#实现多线程的方式:使用Parallel类
简介 在C#中实现多线程的另一个方式是使用Parallel类. 在.NET4中 ,另一个新增的抽象线程是Parallel类 .这个类定义了并行的for和foreach的 静态方法.在为 for和 f ...
- 百度编辑器ueditor的toolbars的各个元素代表的功能说明
百度编辑器ueditor的toolbars的各个元素代表的功能说明
- 如何定义一个接口(接口Interface只在COM组件中定义了,MFC和C++都没有接口的概念)
接口是COM中的关键词,在c++中并没有这个概念.接口是一种极度的抽象.接口用在COM组件中有自己的GUID值,因此定义接口时一定要指定它的GUID值. 实际上接口就是struct,即#define ...
- HasnMap的一种遍历方式:Map.Entry 和 Map.entrySet()
1.Map.Entry 和 Map.entrySet()分别是什么? Map.entrySet():根据名字便可知道,这是一个集合,是一个映射项的set. Map.Entry<k,v>: ...
- 2017-2018-1 20179215《Linux内核原理与分析》第七周作业
一.实验部分:分析Linux内核创建一个新进程的过程. [第一部分] 根据要求完成第一部分,步骤如下: 1. 首先进入虚拟机,打开终端,这命令行依次敲入以下命令: cd LinuxKernel ...
- ACM学习历程—HDU 5536 Chip Factory(xor && 字典树)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5536 题目大意是给了一个序列,求(si+sj)^sk的最大值. 首先n有1000,暴力理论上是不行的. ...