《MySQL慢查询优化》之SQL语句及索引优化
1、慢查询优化方式
- 服务器硬件升级优化
- Mysql服务器软件优化
- 数据库表结构优化
- SQL语句及索引优化
本文重点关注于SQL语句及索引优化,关于其他优化方式以及索引原理等,请关注本人《MySQL慢查询优化》系列博文。优化我个人遵循的原则:积小胜为大胜,以空间换时间。-《论持久战》
2、数据源
工欲善其事必先利其器,为了测试与验证的方便,数据库可以直接采用MySQL官方提供的测试数据库employees,该数据库关系复杂度适中以及数据量较大,适合做SQL语句及索引优化分析,引用官方instruction:
The database contains about 300,000 employee records with 2.8 million salary entries.
The export data is 167 MB, which is not huge, but heavy enough to be non-trivial for testing.
- 数据库获取方式:https://github.com/gavincoder/test_db
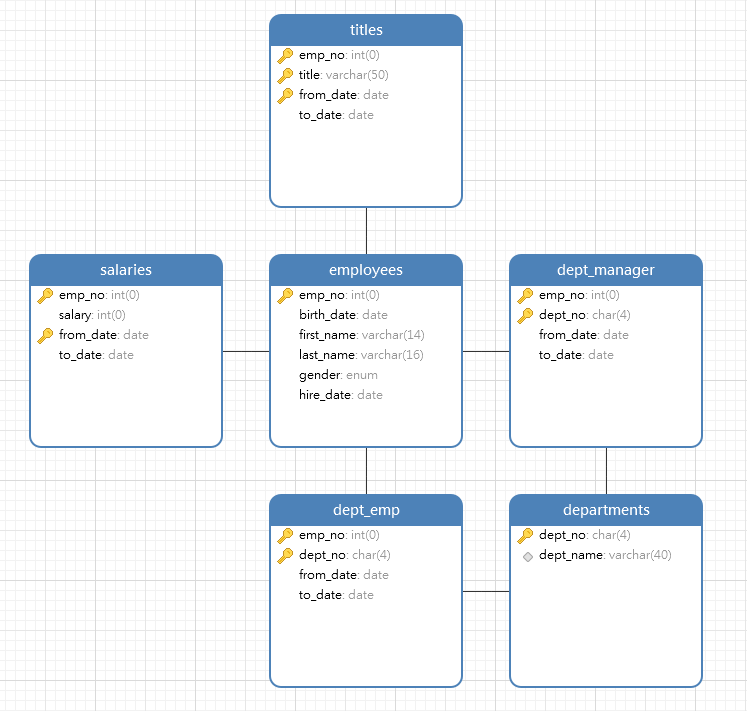
- 数据库E-R关系图:
3、分析工具
采用explain指令直接模拟Mysql优化器执行SQL语句,查看SQL语句的执行计划。
示例:
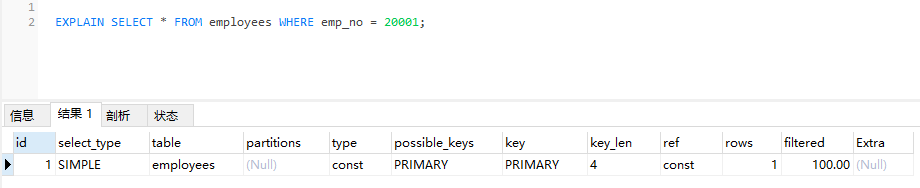
explain命令执行结果包括若干参数:id、select_type、table、type、possible_keys、key、key_len、ref、rows、Extra;重点关注type、possible_keys、key、key_len、extra 这五个参数。
- possible_keys:此次查询中可能会被选用的索引,注意这些索引不一定被查询使用到。
- key:此次查询中真正使用到的索引。当为复合索引时,不确定是否被充分使用。
- type:访问类型,表示MySQL在表中查找所需行的方式。常用的类型有: ALL, index, range, ref, eq_ref, const, system, NULL(性能从左到右逐步提升),其中:
| ALL | Full Table Scan, MySQL将遍历全表以找到匹配的行; |
| index | Full Index Scan,index与ALL区别为index类型只遍历索引树; |
| range | 只检索给定范围的行,使用一个索引来选择行; |
| ref | 表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值; |
| eq_ref | 类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件; |
|
const system |
当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。如将主键置于where列表中,MySQL就能将该查询转换为一个常量,system是const类型的特例,当查询的表只有一行的情况下,使用system; |
| NULL | MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。 |
- key_len:表示索引中使用的字节数,用来计算索引是否被充分使用,不损失精确性的情况下,长度越短越好 ;
| key_len=字符长度*字节数+类型+是否允许为空 | ||||||
| 索引是否充分使用:复合索引每个列都需要计算,所有索引列都生效了才是充分利用。 | ||||||
|
计算规则: 。字节数相关:长度、字符编码、类型(int+0,char+0,varchar+2)、是否允许为空(空+1,非空+0); 。int类型字节数为4; 。char和varchar的长度是指字符数,一个字符在编码gbk为2个字节、utf-8为3个字节,需要:字符数*字节。 |
||||||
|
示例:
|
- extra:
| Using where说明:SQL使用了where条件过滤数据; |
| Using index说明:表示已经使用了覆盖索引。SQL所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。(聚簇型索引,innodb的主键索引) |
4、索引策略
索引策略是指创建使用索引所要遵循的规则,换句话说,违背了这些规则会导致索引失效或者查询效率降低。
| 策略1:尽量考虑覆盖索引 |
| 策略2:遵循最左前缀匹配 |
| 策略3:范围查询字段放最后 |
| 策略4:不对索引字段进行逻辑操作 |
| 策略5:尽量全值匹配 |
| 策略6:Like查询,左侧尽量不要加% |
| 策略7:注意null/not null 可能对索引有影响 |
| 策略8:尽量减少使用不等于 |
| 策略9:字符类型务必加上引号 |
| 策略10:OR关键字前后尽量都为索引列 |
测试数据表:
show index from employees;

策略1:尽量考虑覆盖索引
覆盖索引:SQL只需要通过遍历索引树就可以返回所需要查询的数据,而不必通过辅助索引查到主键值之后再去查询数据(回表操作)。回表操作的详细介绍可以参考本人《MySQL慢查询优化》系列博文之索引。
EG:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE gender ='M' ;

Using index:表示已经使用了覆盖索引。
策略2:遵循最左前缀匹配
联合索引命中必须遵循“最左前缀法则”。即SQL查询Where条件字段必须从索引的最左前列开始匹配,不能跳过索引中的列。
EG:
| 联合索引 |
INDEX idx_empno_birthdate_gender(emp_no,birth_date,gender) |
| 联合索引命中的where条件字段列表 |
实际上联合索引idx_empno_birthdate_gender等价建立了三个索引。 |
EXPLAIN SELECT * FROM employees WHERE birth_date = '1963-06-01' AND gender ='F';

注:表存在多个索引时,即使Where条件满足最左前缀规则,SQL执行时也未必一定会命中联合索引,根据性能可能直接使用了主键索引。
EG:
EXPLAIN SELECT * FROM employees WHERE emp_no = 10010 AND birth_date = '1963-06-01' AND gender ='F';

PRIMARY KEY (`emp_no`)
策略3:范围查询字段放最后
联合索引定义时,务必将范围查询字段放在最后。使用联合索引时范围列后面的索引列无法生效,同时索引最多用于一个范围列,如果查询条件中有多个范围列,也只能用到一个范围列索引。
索引的定义需要参考具体的SQL实现。
EG1:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE emp_no > 10015 AND gender ='F';

只是使用到了主键索引PRIMARY(emp_no),联合索引未生效idx_empno_birthdate_gender(emp_no,birth_date,gender);
删除idx_empno_birthdate_gender索引,新建联合索引idx_gender_birthdate_empno(gender,birth_date,emp_no);

EG2:
EXPLAIN SELECT emp_no,birth_date,gender FROM employees WHERE emp_no > 10015 AND gender ='F';

策略4:不对索引字段进行逻辑操作
在索引字段上进行计算、函数、类型转换(自动\手动)都会导致索引失效。
EG:
CREATE INDEX idx_first_name ON employees(first_name);
EXPLAIN SELECT * FROM employees WHERE LEFT(first_name,3) ='Geo';

策略5:尽量全值匹配
全值匹配也就是精确匹配不使用like查询(模糊匹配),使用like会使查询效率降低。
策略6:Like查询,左侧尽量不要加%
like 以%开头,当前列索引无效(当为联合索引时,当前列和后续列索引不生效,可能导致索引使用不充分);当like前缀没有%,后缀有%时,索引有效。
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name like'Geo%';

EG2:
EXPLAIN SELECT * FROM employees WHERE first_name like'%Geo%';

策略7:注意NULL/NOT NULL可能对索引有影响
在索引列上使用 IS NULL 或 IS NOT NULL条件,可能对索引有所影响。
- 字段定义默认为NULL时,NULL索引生效,NOT NULL索引不生效;
- 字段定义明确为NOT NULL ,不允许为空时,NULL/NOT NULL索引列,索引均失效;
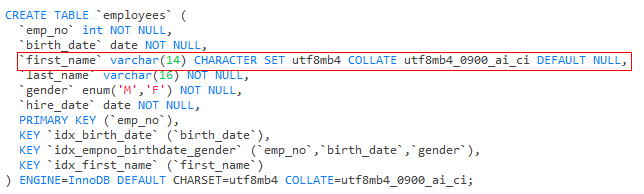
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name IS NULL;

EG2:
EXPLAIN SELECT * FROM employees WHERE first_name IS NOT NULL;

EG3:
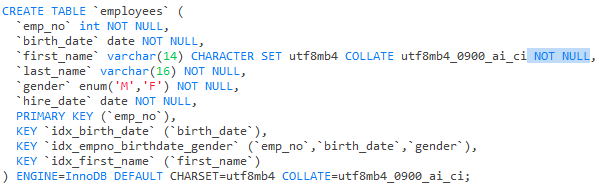
EXPLAIN SELECT * FROM employees WHERE first_name IS NOT NULL;

策略8:尽量减少使用不等于
不等于操作符是不会使用索引的。不等于操作符包括:not,<>,!=。
优化方法:数值型 key<>0 改为 key>0 or key<0。
EG:
EXPLAIN SELECT * FROM employees WHERE first_name != 'Georgi';

策略9:字符类型务必加上引号
若varchar类型字段值不加单引号,可能会发生数据类型隐式转化,自动转换为int型,使索引无效。
EG:
EXPLAIN SELECT * FROM employees WHERE first_name = 1;

策略10:OR关键字前后尽量都为索引列
当OR左右查询字段只有一个是索引,会使该索引失效,只有当OR左右查询字段均为索引列时,这些索引才会生效。OR改UNION效率高。
EG1:
EXPLAIN SELECT * FROM employees WHERE first_name = 'Georgi' OR emp_no = 20001;

EG2:
EXPLAIN SELECT * FROM employees WHERE first_name = 'Georgi' OR last_name = 'Facello';

后续:
- 当全表扫描速度比索引速度快时,MySQL会使用全表扫描,此时索引失效。
- 表中存在多个索引时,即使where条件满足某个索引策略,MySQL查询优化器也不一定会使用该索引,可能使用其他索引,取决于性能。另外,当某个索引没有命中也不一定会走全表扫描,可能走其他索引。
- 理论上索引对顺序是敏感的,也就是说where子句的字段列表需要讲究顺序,但是由于MySQL的查询优化器会自动调整where子句的条件顺序以匹配适合的索引,因此,允许我们不去刻意关注where子句的条件顺序。
《MySQL慢查询优化》之SQL语句及索引优化的更多相关文章
- 【转】MySQL用户管理及SQL语句详解
[转]MySQL用户管理及SQL语句详解 1.1 MySQL用户管理 1.1.1 用户的定义 用户名+主机域 mysql> select user,host,password from mysq ...
- 如何用VS EF连接 Mysql,以及执行SQL语句 和存储过程?
VS2013, MySQL5.7.18 , MySQL5.7.14 执行SQL语句: ztp_user z = new ztp_user(); object[] obj = new object[] ...
- 如何记录MySQL执行过的SQL语句
很多时候,我们需要知道 MySQL 执行过哪些 SQL 语句,比如 MySQL 被注入后,需要知道造成什么伤害等等.只要有 SQL 语句的记录,就能知道情况并作出对策.服务器是可以开启 MySQL 的 ...
- mysql里面如何用sql语句让字符串转换为数字
sql语句将字符串转换为数字默认去掉单引号中的空格,遇到空格作为字符串截止, SELECT '123 and 1=1' +0 结果为123 MySQL里面如何用sql语句让字符串的‘123’转换为数字 ...
- MySQL数据库(一)—— 数据库介绍、MySQL安装、基础SQL语句
数据库介绍.MySQL安装.基础SQL语句 一.数据库介绍 1.什么是数据库 数据库即存储数据的仓库 2.为什么要用数据库 (1)用文件存储是和硬盘打交道,是IO操作,所以有效率问题 (2)管理不方便 ...
- SQl语句查询性能优化
[摘要]本文从DBMS的查询优化器对SQL查询语句进行性能优化的角度出发,结合数据库理论,从查询表达式及其多种查询条件组合对数据库查询性能优化进行分析,总结出多种提高数据库查询性能优化策略,介绍索引的 ...
- Oracle SQL语句之常见优化方法总结--不定更新
1.SQL语句尽量用大写的: 因为oracle总是先解析SQL语句,把小写的字母转换成大写的再执行. 2.WHERE子句中的连接顺序: ORACLE采用自下而上的顺序解析WHERE子句,根据这个原理, ...
- Oracle SQL语句之常见优化方法总结
1.用EXISTS替换DISTINCT 当SQL包含一对多表查询时,避免在SELECT子句中使用DISTINCT,一般用EXIST替换,EXISTS(低效): SELECT DISTINCT USER ...
- mysql中explain查看sql语句索引使用情况
explain + sql: mysql> explain select * from user; +----+-------------+-------+------+------------ ...
随机推荐
- redis的rdb与aof持久化机制
Redis提供了两种持久化方案:RDB持久化和AOF持久化,一个是快照的方式,一个是类似日志追加的方式 RDB快照持久化 RDB持久化是通过快照的方式,即在指定的时间间隔内将内存中的数据集快照写入磁盘 ...
- NS-3环境布置及安装
MMP的,入坑NS3了,LTE是什么鬼!!! ubantu安装NS3解决依赖环境 一堆安装包需要安装,试了N多次(CentOS没安装明白,转而ubantu).利用脚本进行按装. 貌似得先对本机软件进行 ...
- R语言factor类型转numeric
R 语言中为了进行数据分析,比如回归分析,这时候对于数据表格中的factor类型的数据会带来弊端,比如对因子的每一个数据都进行一次回归,这样就显得很复杂,且违背了我们的初衷,需要把factor转换为n ...
- 力扣 122 买卖股票的最佳时机II
力扣 122 买卖股票的最佳时机II 思路: 动态规划,表面上是\(O(2^n)\)的搜索空间,实际上该天的选择只与前一天的状态(是否持有股票)有关.从收益的角度来看,确实每一天的不同选择都会产生不同 ...
- Ubuntu 18.04 Tomcat 安装及配置
转载自:https://blog.csdn.net/weixx3/article/details/80808484 1.下载Tomcat 8.5.31到Apache Tomcat官网,选择tar.gz ...
- MSSQL 高并发下生成连续不重复的订单号
参考: https://www.cnblogs.com/h-change/p/6699683.html 这里在数据库层面生成的,经测试确实不会重复. 附上自己修改后的版本,这里也可以预先生成一年的记录 ...
- CSS浮动好文章
http://www.cnblogs.com/iyangyuan/archive/2013/03/27/2983813.html 看完上面这篇文章,我哭了.写的真好,我这块更菜.
- mdp文件-Chapter2-NVT.mdp
这是mdp文件系列的第二篇,介绍nvt平衡中要使用的mdp文件. 先上代码,nvt.mdp 1 title = OPLS Lysozyme NVT equilibration 2 define = - ...
- 彻底卸载MySQL5.7(msi,exe)版
1,停止MySQL服务 2,右键找到任务管理器 3,在程序中卸载MySQL 4,删除MySQL安装目录 有的是在C:\Program Files下,我的是在(X86)下 5,删除隐藏文件中的MySQL ...
- Hadoop大数据平台节点的动态增删
环境:CentOS 7.4 (1708 DVD) 工具:MobaXterm 一. 节点的动态增加 1. 为新增加的节点(主机)配置免密码登录.使用ssh-keygen和ssh-copy-id命令(详 ...